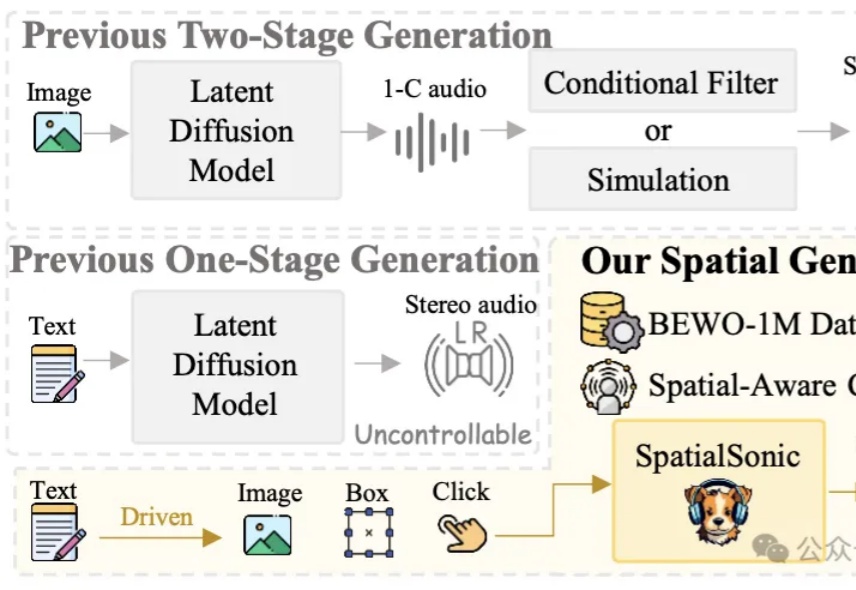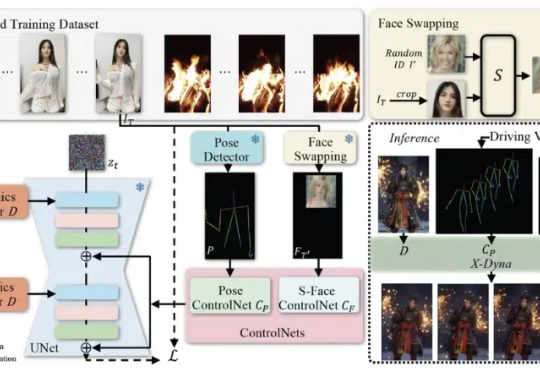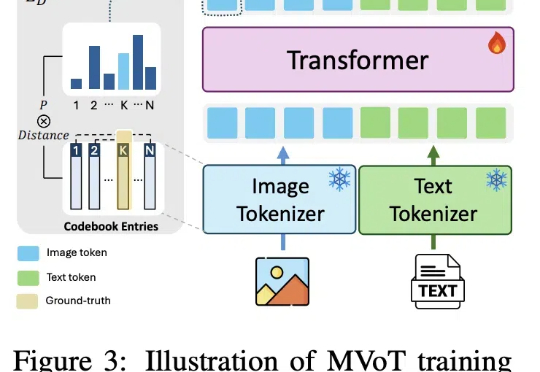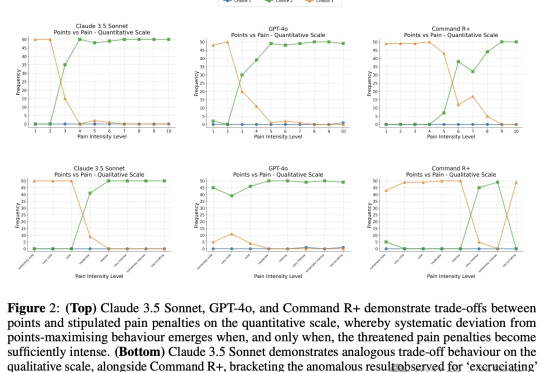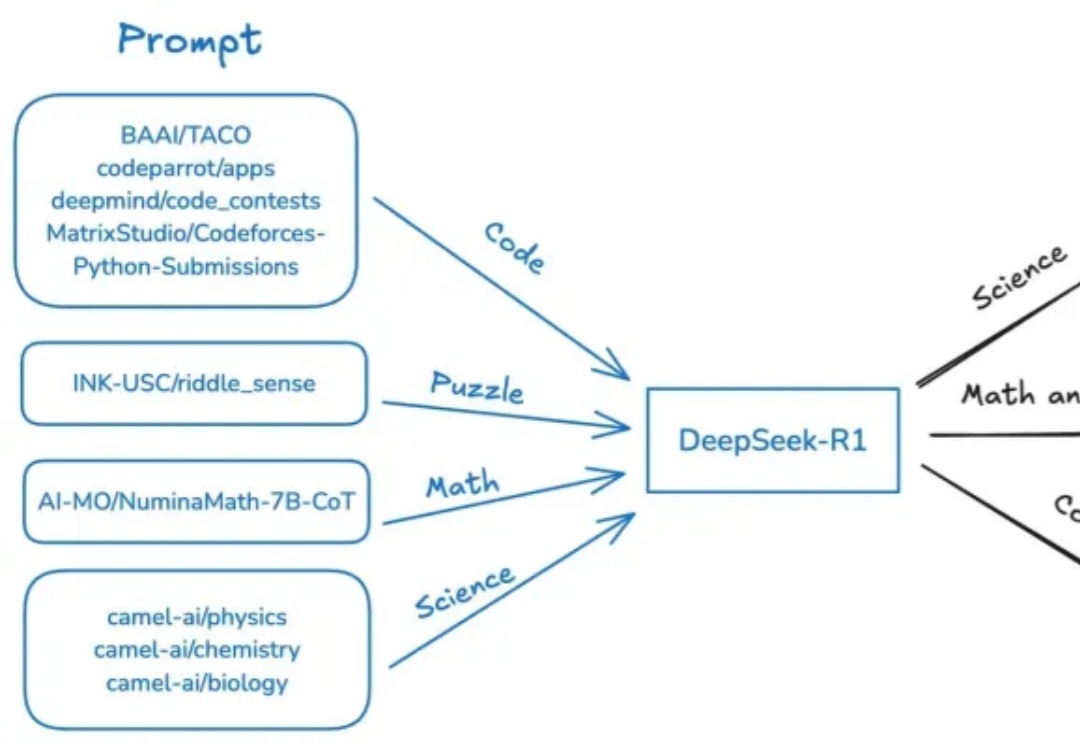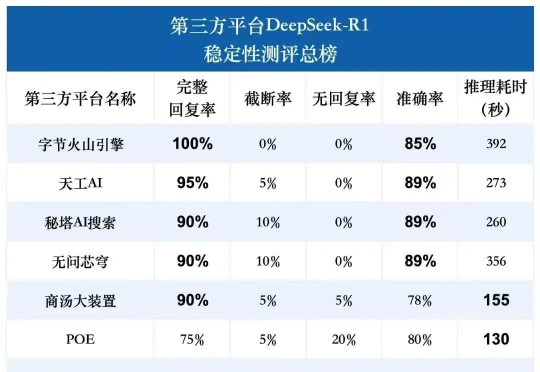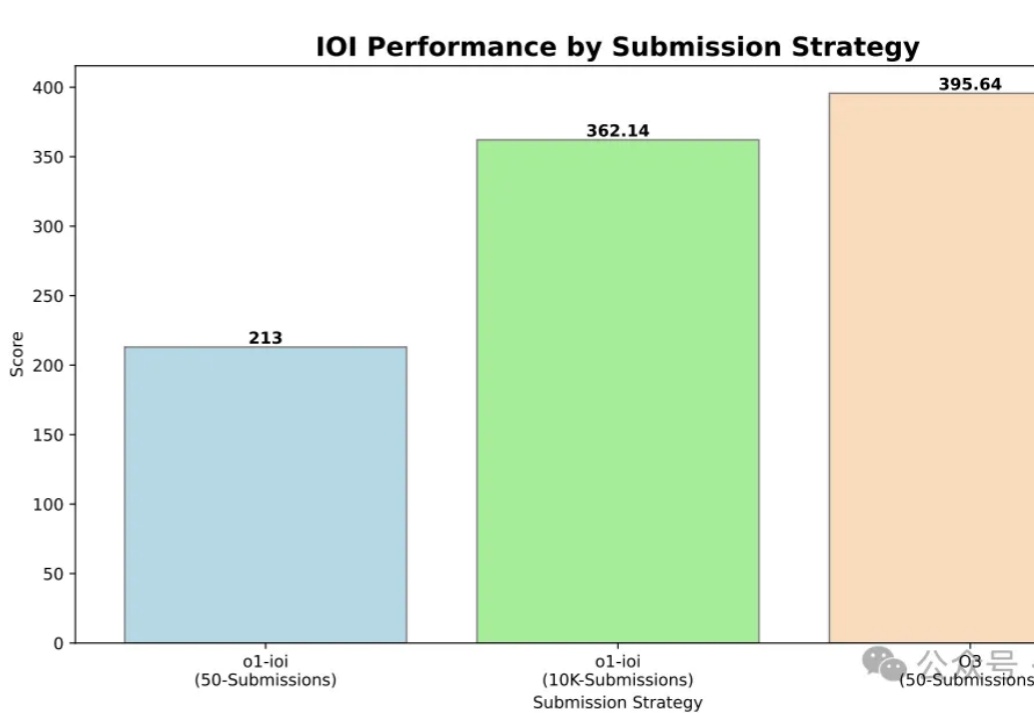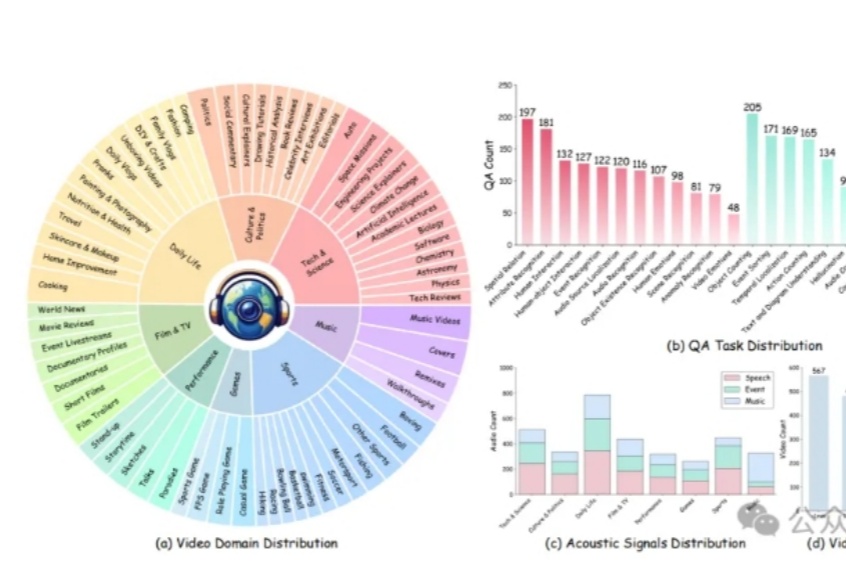
DeepSeek R1之后,AI创业、AI投资会发生什么变化?
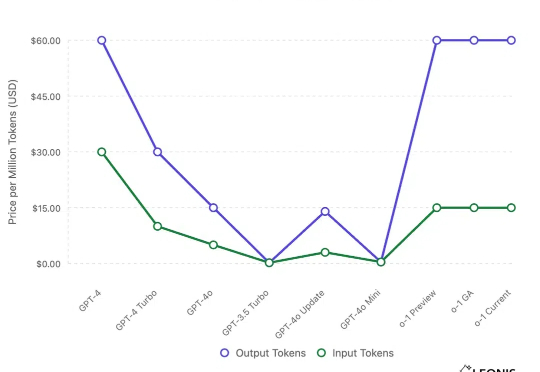
DeepSeek R1之后,AI创业、AI投资会发生什么变化?自一月以来, DeepSeek 在 AI 领域引发了极大的热度,也出现了大量分析文章。其中来自 Leonis Capital 于 2.6 发表于 Substack 上的文章:「DeepSeek: A Technical and Strategic Analysis for VCs and Startups」
来自主题: AI技术研报
6853 点击 2025-02-15 16:00