# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
要做大模型领域的安卓和Linux。
36氪获悉,大模型架构创新公司元始智能(RWKV)已于12月完成数千万人民币天使轮融资,投资方为天际资本。本轮融资后,公司估值较此前种子轮翻倍,而本轮融资将主要用于团队扩充、新架构迭代以及产品商业化落地。
OpenAI旗下的ChatGPT于2022年11月发布,并掀起全球生成式AI浪潮后,已经有两年多的时间。而支撑起ChatGPT的Transformer架构以及Scaling Law(缩放定律),正是这场革命的技术发展主线。
大语言模型(LLM)之所以能够涌现智能,简而言之,是因为让AI模型的参数规模从原来的亿级扩大到了如今的千亿、万亿,在学习了足够多的数据后,模型涌现出了智能。
但大模型也有自己的“阿喀琉斯之踵”——幻觉、准确率几乎是无法完全解决的问题。在刚刚过去的2024年,随着大模型迭代放缓,无论是学界还是工业界,都迎来了对Transformer架构,以及Scaling Law(缩放定律,指增加算力、数据规模,模型性能会相应提高,获得更多智能)的大讨论。
元始智能(RWKV)的成立,正是希望探寻一条能够超越Transformer架构的新路。"我们不仅是一家大模型公司,而且是一家有能力持续实现AI模型底层架构创新的“黑科技”公司。"元始智能联合创始人罗璇表示。
RWKV的创始人彭博毕业于香港大学物理系,曾是量化交易专家。彭博从2020年开始,就选择独立开发RWKV这个创新架构和开源项目。2022年底,RWKV发布首个模型,到如今2023年6月正式成立商业公司,团队已从最初3人发展至近20人的规模。
与依赖巨额算力和数据的Transformer架构不同,RWKV选择了一条更加注重效率和灵活性的技术路线。
“简单而言,目前主流的Transformer架构,相当于每次对话中,模型每输出一个Token,都需要把前文从头全部‘读’一遍,并且需要始终记录前文每个token的状态(即 KV Cache)。” 元始智能联合创始人罗璇表示。这也注定了Transformer不是一个高效的信息处理架构,而且需要大量的算力。
但RWKV最大的技术突破在于,模型不需要始终记录每个Token的状态——也就是不需要每次对话都“从头读全文再给回复”,计算量大大减少。这相当于将Transformer的高效并行训练、与RNN的高效推理能力相结合。
RNN(循环神经网络)并不是一个新技术。虽然它的推理效率高于Transformer,但在RWKV之前,大家普遍认为RNN的能力弱于Transformer。但RWKV的出现,证明了改进后的RNN不但效率保持高于Transformer,且同样具有很强的语言建模能力。
不过,效率更高的代价是:作为状态空间大小固定的RNN,不可能将无限长度的前文全部压缩进状态空间。也就是说,RWKV会逐渐遗忘模型自动判断为“可以遗忘的细节”(对于模型自动判断为重要的细节,模型会持久记忆),相当于看了一遍前文就回答问题,不会再反复阅读前文。
彭博认为,这并不是RWKV架构的缺陷。正如,虽然人类大脑本身没有完美的记忆力,但人类通过少量复读和外部记忆,同样可以拥有完美的记忆力。RWKV可以通过引入RL(强化学习)的方法,来自动判断在必需的时候重新阅读前文,这比Transformer“强行把所有东西都记住”的效率要高得多。
同时,RWKV的特性也有利于在部分场景的应用和落地,比如写作、音乐生成等创意性场景,模型产出的结果会更创新,“AI味”更弱。
“在音乐生成等创意领域,RWKV的架构更接近人脑的记忆演绎机制,不是简单检索过去的信息,而是通过不断更新和重组来‘演绎’,从而产生新的内容。”罗璇解释。
目前,RWKV已经完成了从0.1B到14B的模型训练,且海外社区已发布了32B的预览模型。在过去两年中,RWKV也实现了重要的技术突破:架构从RWKV-4逐步迭代至RWKV-7。
最新发布的RWKV-7模型,在同等参数规模下,可以全面超越Transformer架构的性能。这种优势体现在多个维度:例如,在模型学习效率上,RWKV-7能比经过充分优化的Transformer架构更快地提升准确度。而使用相同参数和训练数据的情况下,在核心benchmark如英语和多语言测试中,RWKV-7也能表现更优。
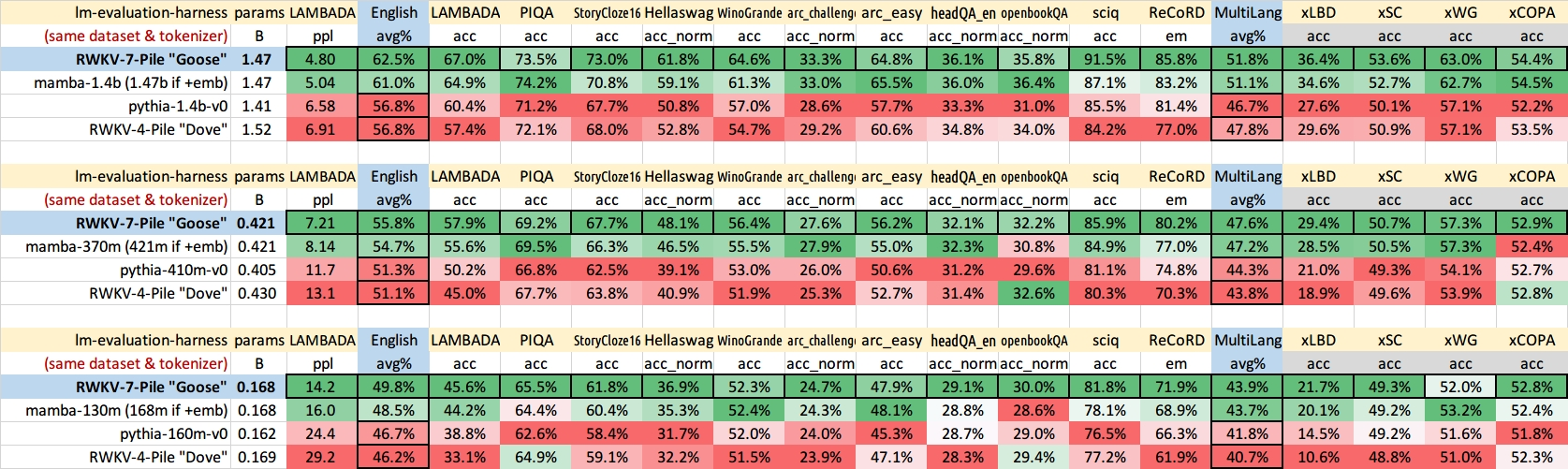
来源:RWKV
RWKV-7的记忆力,比起之前的RWKV也显著更强。例如,0.1B的RWKV-7在4k上下文窗口下训练,就能自动解决16k的大海捞针问题。
“RWKV采用的类RNN架构更接近人脑和宇宙的运作方式,通过高效的信息压缩机制,使模型能够在有限资源下实现持续学习和进化。”罗璇表示。
持续学习,也是RWKV-7版本的一个重要技术突破。比起主流模型采用的“训练-推理分离”机制,RWKV能够让模型“边推理边学习”,更好地学习前文中的的规律。
RWKV高效推理的机制,相当适合用于小模型、端侧等场景中——大模型虽然性能强,但计算层面依然面临不少桎梏:无论是手机还是电脑,硬件层面如果没有足够强大的计算单元,也没有办法让模型在本地运转,而是要依赖云端的计算,这就降低了使用体验。
当前,元始智能的公司业务分为两大部分,一是将模型开源,这一部分将持续保持全开源和免费——在GitHub上,RWKV的核心开源项目RWKV-LM已收获了超过12900的star,并且逐步建立起开发者生态,当前已有包括腾讯、阿里、浙大、南方科技大学在内的多家高校和公司使用了RWKV;二是商业实体。在2024年,RWKV做了不少产品侧的尝试,同时覆盖To B和To C。
在软件侧,RWKV面向C端市场推出了AI音乐生成应用。而在To B领域,元始智能选择了具身智能和新能源两大领域,为企业提供模型授权,目前已达成的合作客户包括国家电网、有鹿机器人等企业。
在未来,元始智能计划在2025年推出70B及以上参数的RWKV-7和终端部署方案,并通过结合新型推理框架和新型芯片,探索更大规模的模型。罗璇表示,随着如今Scaling Laws转向,预计2025年上半年将迎来新架构的爆发期,届时元始智能也会加速商业化落地。
文章来自于“咏仪”,作者“咏仪”。



【开源免费】suno-api是一个使用监听技术实现了调用suno功能,并封装好API的AI音乐项目。
项目地址:https://github.com/gcui-art/suno-api
