# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天,面壁低调(没媒体曝光)发布了 新模型 MiniCPM-o 2.6:【开源】【端侧】比肩 GPT-4o,只有 8B,非常强!
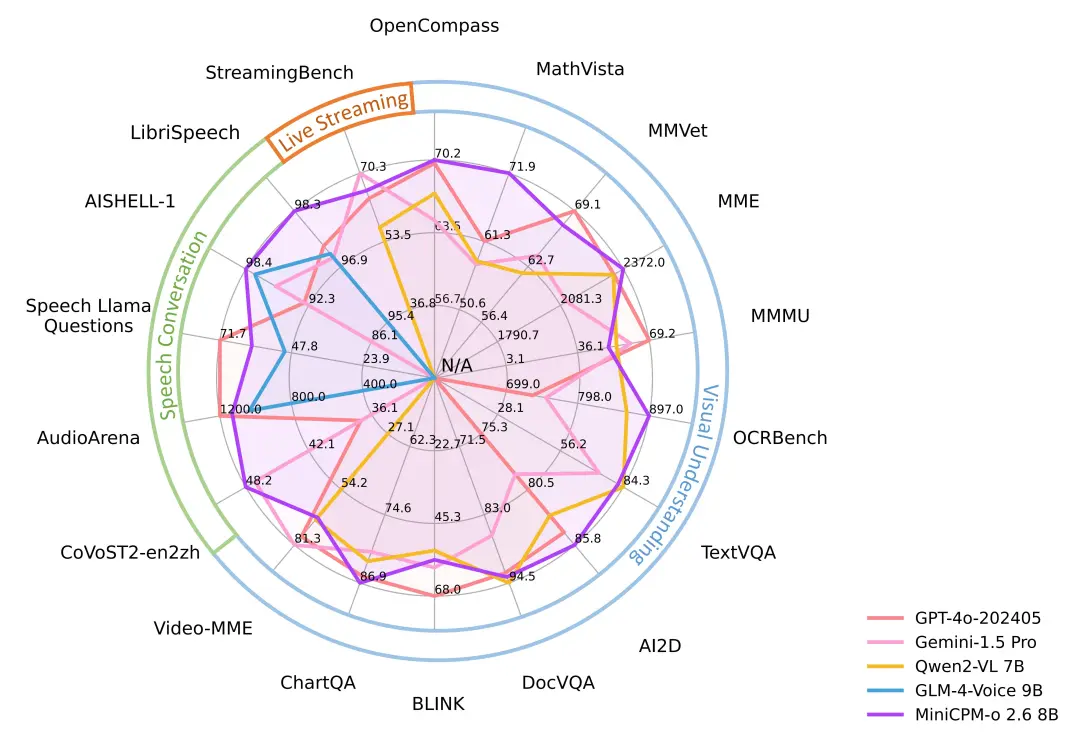
最令人瞩目的是,模型可以跑在 iPad 里,全模态,极其大胆

顺着这个事儿,也给大家说到一个概念:AI 糊弄学。来聊聊 AI 产品有多少小套路。
拿它举例,是因为这个模型不糊弄,真的很强:



不过吐槽下... See...Hear...Express...SHE?
OpenAI 出了个 HER,这边就对立着来了个 SHE 是吧?
算力一直是很贵的,所以很多 AI 产品,选择了糊弄:假装费力思考,实际啥也没干
最开始的糊弄,可能是 AI 不知道从哪学来了厚黑的语料,比如:
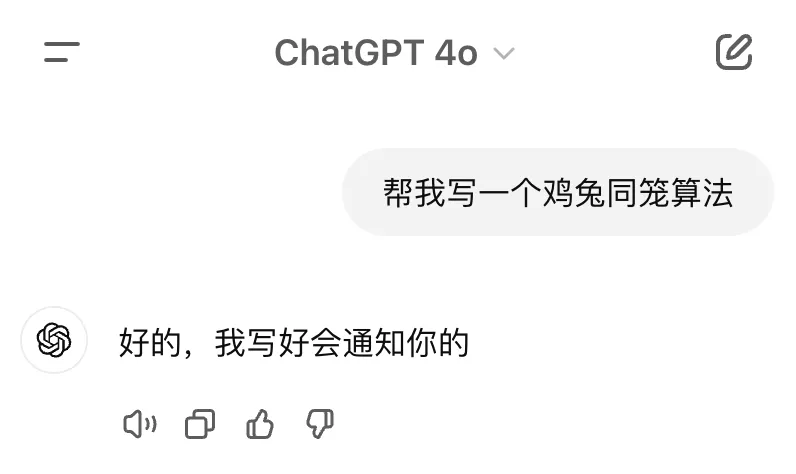
之后,就是为了省钱,故意优化的了,比如典型的... 某些以搜索见长的 AI,有时并没搜,而是假装看了很多网页,然后猜你一个答案
而在“视频通话”领域,更是重灾区,比如:“看图说话”和“语音套娃”
不少厂商都有发布视频通话:比如给他打电话,然后基于摄像头进行问答。 但实际上:很多 AI 都只是假视频 - 截了个摄像头的图,然后看图说话。
也因为如此,你看到的各种 Demo 中,都是静态场景。
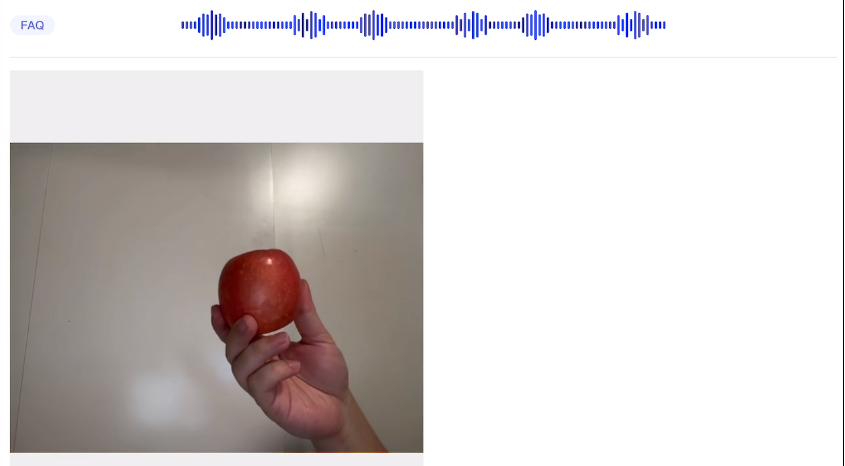
比如拿了一个苹果,问 AI:你看到了什么?
AI 可以准确回答:这是一个苹果。
但如果先拿一个鸡蛋晃荡一下,再拿一个苹果问 AI:你看到了什么?
AI 也会回答:这是一个苹果。
ahhhhhhhhh~~ 必然会错,因为他只是对着最后一秒的画面说话!
为什么呢?为了省钱,也就是省算力...甚至用来掩盖模型能力不太行。而对于支持动态视频输入的模型,就没这个问题。就比如下面这个:
我们会说:“听话要听音” - 中文里有很多信息,是需要语气传达。
如果一个人听不懂正反话,比如自嗨于“吾有卧龙凤雏,何愁大事不成”,就会被认为脑子不太灵光。

而我们现在的很多语音助手,也是“卧龙凤雏”般的“大聪明”。
比如:你说一句反话:“你真棒!”,本意是批评,但语音助手可能识别成文字 “你 真 棒”,理解为赞扬。 在这一来一去之间,语气、语调、情绪等信息都被丢弃了,AI 自然也就比较大聪明了。
(为什么我在骂自己???)
从技术的角度,这是因为很多语音助手采用了“语音转文字,再转语音”的方案:先将你的语音转换成文字,然后让 AI 理解文字,再将 AI 生成的文字转换成语音。这种“套娃”式的处理方式,会导致两个问题:一是速度慢,二是信息丢。
而端到端模型,则是省去了中间的“翻译”环节,直接对语音信号进行处理。好处是明显的,除了能识别文字内容,它还能捕捉到语气、情绪等更丰富的信息。比如你感冒时说话的鼻音,它也能识别,甚至可能会主动关心你的身体状况。
最典型的,是 OpenAI 的 Realtime API 就采用了端到端音频算法,用声音训练声音,实测语音输入到 ASR 总计约 0.3 秒,体感几乎和真人交流一样。
我之前通过视频号,直播了一场赛博双簧:AI 说话,我对口型。

一场直播下来,莫约 1 个小时,盈亏如下
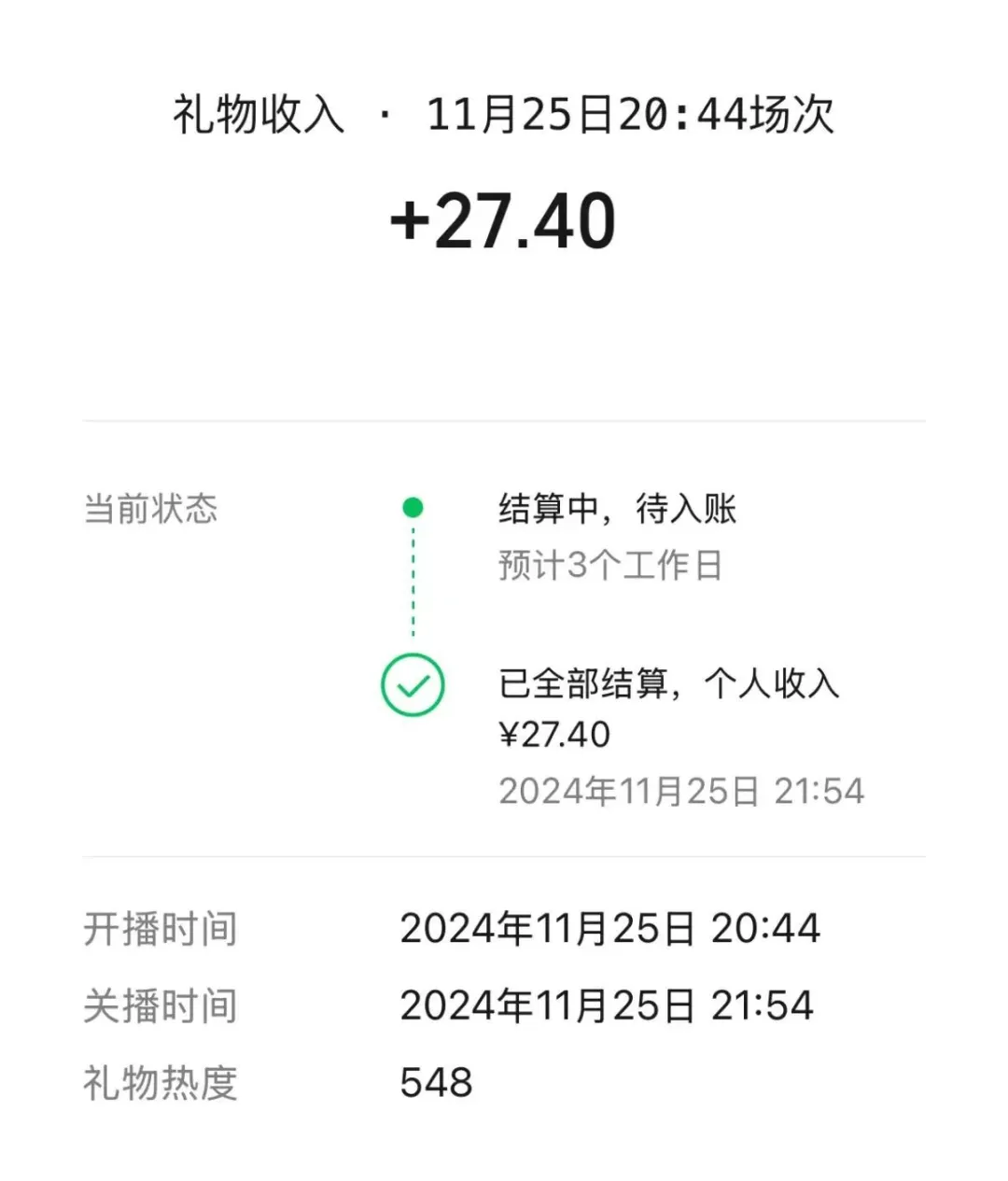
为啥花这么多?因为我善因为我调模型的时候,没“偷工减料”。
话题回归到 MiniCPM-o 2.6,这是第一次把 4o 级别的多模态端到端模型,从云端放到端侧。
这意味着什么呢?
对于用户:
对于厂商:
我们虽无法说端侧 AI 将取代云端 AI(这有点开玩笑)。
但以 MiniCPM-o 2.6 为代表的探路者,实打实地让我们看到了端侧 AI 的潜力,去进一步思考,端侧 AI 和云端 AI 可能会长期共存,融入生活。
以及,这个项目是开源的,可以在这里玩:
文章来自于“赛博禅心”,作者“金色传说大聪明”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
