# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
o1背后的推理原理,斯坦福和伯克利帮我们总结好了!
在最新的一篇长达100页的论文中,他们将o1模型背后的推理机制提炼成了一个通用的框架——元链式思维(Meta-CoT)。

这个元链式思维(Meta-CoT)到底是什么意思呢?
简单来说,它可以让模型在推理过程中反思推理任务——
这样不仅能得出结论,它还可以帮助我们找到更多新的研究思路和方法。
比如在经典的24点问题中,传统的CoT虽然也能得出正确的结论,但是Meta-CoT在推理过程中不止会关注输入的问题,而是在推理过程中思考更多的子问题并进行尝试:

这也是o1模型可以在HARP等数学基准中大幅领先的原因:
SynthLabs公司的CEO Nathan Lile还自信地表示:
元链式思维(Meta-CoT)是通往超级智能(Superintelligence)的正确道路。下一波人工智能就是元链式思维(Meta-CoT)循环。


在提出新框架之前,我们先要理解一个问题:为什么传统模型经常在高级推理任务中“卡壳”。
其实啊,主要原因在于大语言模型的预训练和指令调整语料库数据中,不包含真实数据生成过程。
以数学问题为例,网上和教科书中虽有会有解答,但对于错误的论证方法为何失效,却很少有相关的资料,
如此一来,在遇到复杂推理问题时,被中间环节困住的模型就很难调整到正确的思考方向。
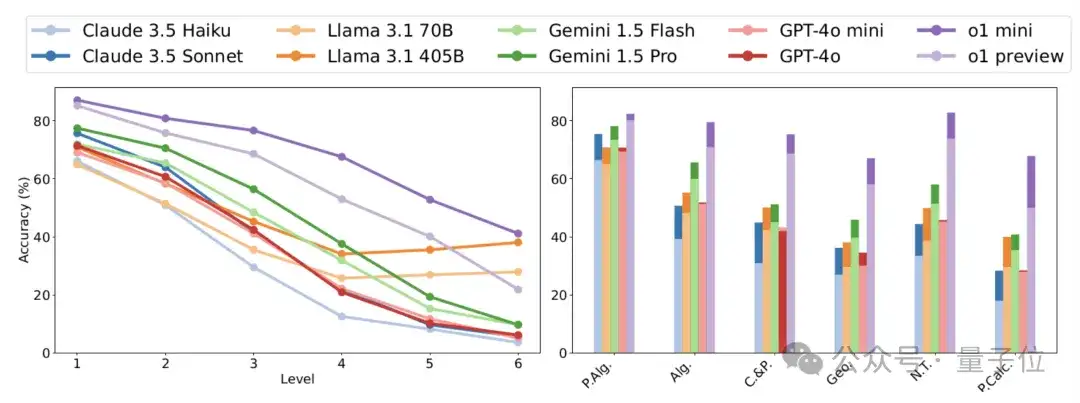
而在全新的高中奥数水平数学基准测试中,OpenAI的o1模型系列表现出众,不仅远超以往的模型,而且问题越难优势越明显。
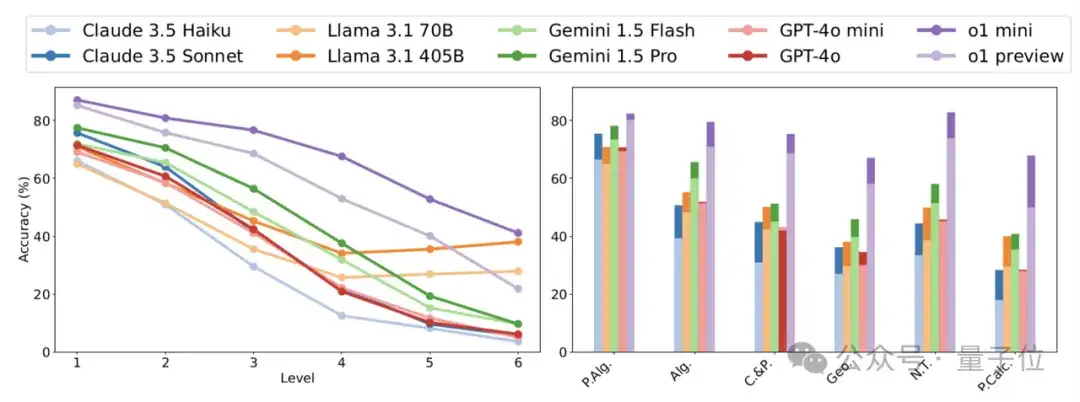
从生成tokens数量看,其他大语言模型生成的解决方案长度与人类相近,这也就是说明,它们只是在搜索匹配训练数据。
而o1模型在简单问题上生成的tokens数与人类相当,在高难度问题上,生成tokens数则大幅增加,与传统模型拉开差距。
这表明o1模型的CoT覆盖范围更广,能更好地接近真实数据生成过程。
我们先来看一道2011年国际数学奥林匹克竞赛的 “风车问题”:
平面上有至少两个点的有限集合,假设任意三点不共线,从过其中一点的直线开始,让直线绕该点顺时针旋转,碰到集合中另一点时,新点成为旋转轴继续旋转,此过程无限持续。能否选一个点和过该点的直线,让集合中每个点都无限次成为旋转轴呢?

官方给出的解答如下:


这道题的解答虽然很简短,不依赖先验知识,但却是竞赛中最难的题之一,600 多名参赛者中只有少数人答对。
主要难点在于,它的解答过程不是线性的。很多人会选择用凸包构造或哈密顿图论方法,最终都会失败。
而答对的人主要是依靠大量几何探索和归纳推理,才最终找到了答案。
也就是说,这个解答过程不是从左到右按部就班生成的。
从潜在变量过程角度看,经典思维链是对潜在推理链进行边缘化,得出最终答案的概率。
但对于复杂问题,真实解答生成过程应该是解答的联合概率分布,取决于潜在生成过程。
这就是团队所说的元思维链(Meta - CoT)过程,使用这个思路,就可以大大提升大语言模型在复杂问题上的推理能力。
Meta-CoT的一个重要步骤是,在面对高级推理问题时,大语言模型会努力提高搜索的效率。
以前模型通常会使用Best-of-N方法,也就是独立生成多个完整答案,然后挑出最好的,但这个方法比较耗时。
在Meta-CoT中,研究人员把推理过程想象成一个“步步走”的游戏,也就是马尔可夫决策过程(MDP)。
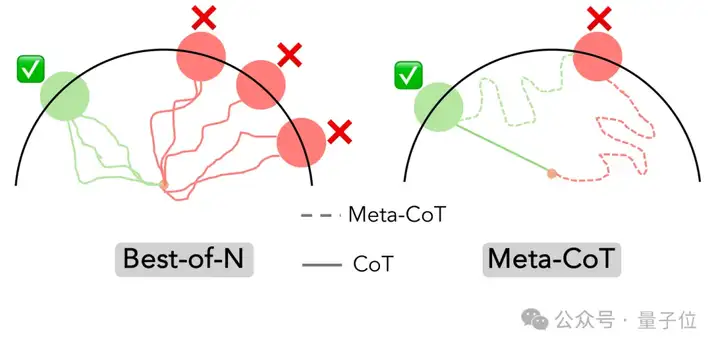
(PRM),它可以用来评估中间步骤能能否得出正确答案。
如果发现某个解答方向没希望,模型就会尽快停下,回到可能成功的中间状态,重新寻找解决方案。
这种树搜索方法在简单推理任务里已经显出明显的优势,在实际应用中也有成功案例。
论文的主要作者之一Rafael Rafailov是斯坦福毕业的博士,也参加过很多数学竞赛,他表示这个新的搜索过程和他自己解答题目时的状态也是一样的:
评估解决方案的潜在方法、修剪没有取得进展的方向、探索其他可能的分支主张、尝试根据直觉构建通往最终目标的路径
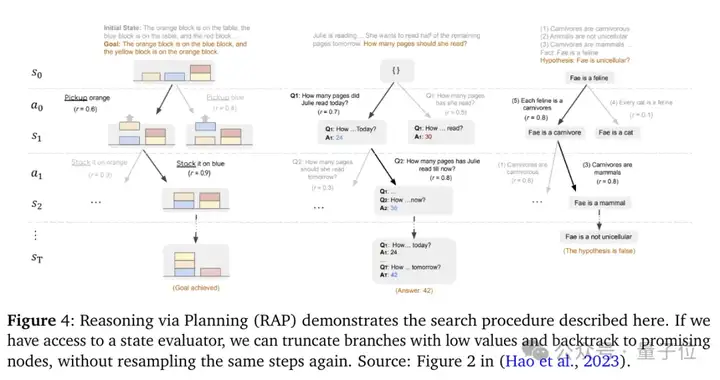
另外一个挑战在于,大模型通常会使用强化学习方法从过去经验里学习好的推理策略,但当遇到新领域的推理问题时,用传统RL训练出来的策略就不太好用了。
为了提高大模型解决不熟悉领域问题的能力,研究人员尝试在Meta-CoT中让大模型把推理过程当成一场“冒险游戏”,也就是部分可观测马尔可夫决策过程(POMDP),非常适合用来升级模型。
在这个过程中,模型可以根据不同情况调整策略。
以下图中的迷宫游戏为例,模型一开始可以随意行走,但慢慢地,通过将不同的顶点加入到路径数据集或删除数据集中,就会逐渐找到正确的方向。

而且,通过过程监督,模型能及时得到反馈,知道自己是否走在正确的解答道路上。
研究人员还发现,让模型主动探索不同的推理路径,能大大提升它的表现。在实验里,模型会努力尝试各种方法,结果在解决复杂问题时,答对的概率也提高了很多。
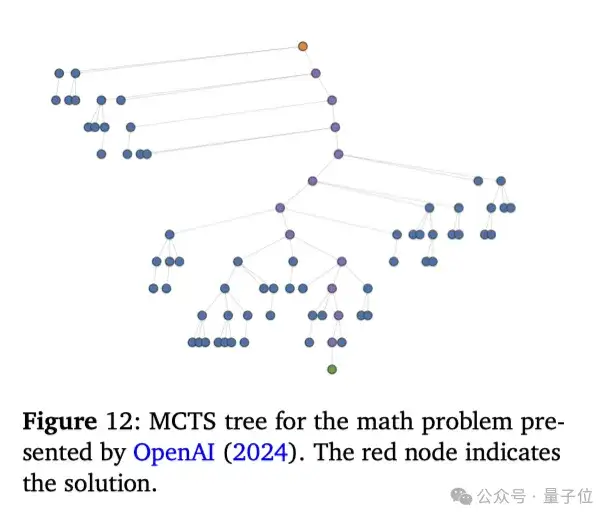
论文还探讨了通过搜索算法(如下图中的蒙特卡罗树搜索(MCTS)和A*搜索)生成合成训练数据的更多方法,这些方法可以帮助模型在上下文中学习并执行复杂的搜索策略。

那么相比原始的CoT,使用Meta-CoT新框架的LLM性能到底变强了多少呢?下面一起来看看论文中的实验部分。
在数据收集方面,本论文主要使用了多个数学问题数据集,包括HARP、NuminaMath、Omni-MATH和OpenMathInstruct-2。通过对这些数据集进行过滤和处理,生成了适合训练的合成数据。
实验中的模型包括当前主流的多个LLM,包括Llama 3.1 8B、70B和GPT-4o等。
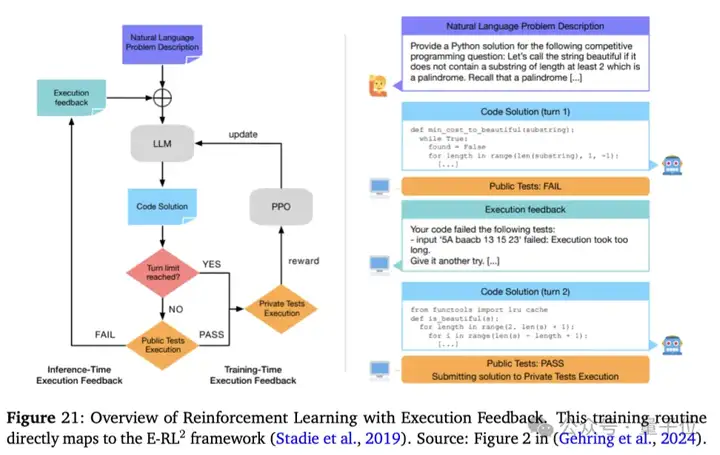
实验设计包括指令调优和强化学习后训练两个阶段。指令调优阶段使用线性化的搜索轨迹进行训练,强化学习后训练阶段使用E-RL2目标进行训练。
在指令调优阶段,团队使用了多种优化目标,包括标准过程克隆方法和元链式思维优化目标。
在强化学习后训练阶段,他们使用了不同的折扣率和优化算法,如PPO和REINFORCE。
小规模的实验结果:在小规模实验中,使用MCTS和A*搜索算法生成的合成数据显著提高了模型在复杂数学问题上的表现。
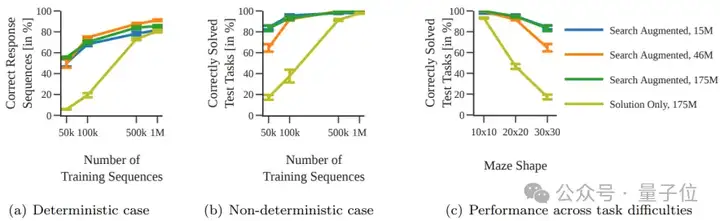
上下文探索的实验结果:在上下文探索实验中,模型在数学问题上的表现随着上下文探索序列长度的增加而提高。然而,过长的序列长度也会导致性能下降,这也提醒我们需要在探索和推理之间找到平衡。
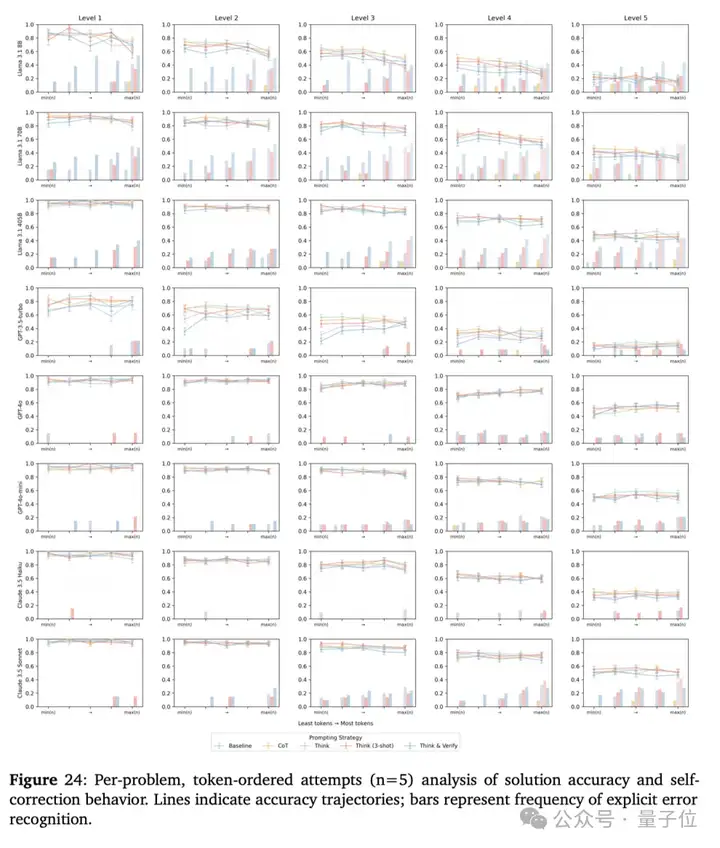

综合实验结果:综合实验结果表明,使用元链式思维框架可以显著提高LLMs在复杂推理任务上的表现。例如,使用 E-RL2 目标训练的模型在HARP数学基准测试中的表现比基线模型提高了约25%。
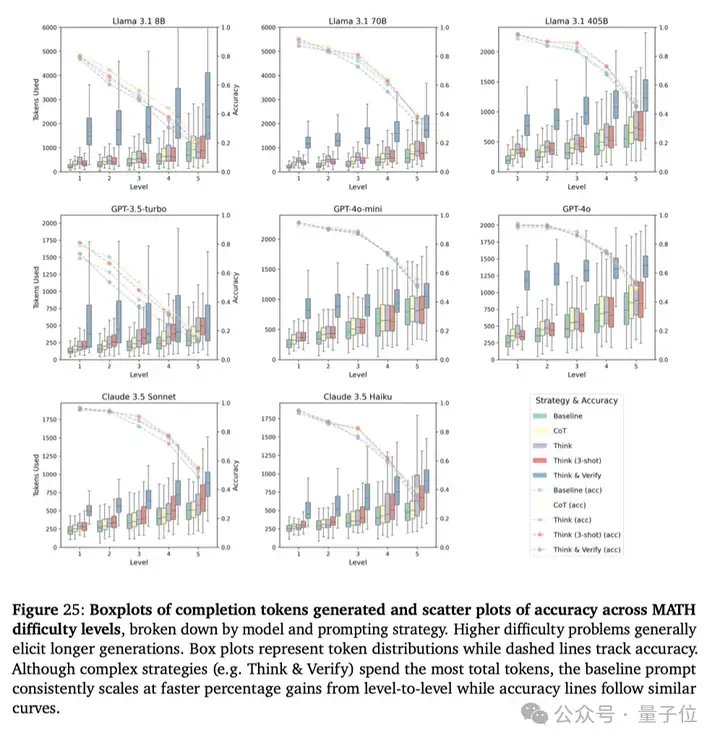
论文提出的通过自教推力器、A*算法等方法进行合成的元链式思维(Meta-CoT)的框架,通过显式建模推理过程和搜索过程,使得LLMs在各项常见的实验任务中进行复杂推理的表现都有所提升。
团队成员也表示,未来会进一步验证所提出方法效率的必要性,开发出更有效的过程监督和验证技术。
此外,针对当前LLM普遍在数学问题等逻辑性较强的任务上表现不佳的现象,他们还正在构建大数学(Big Math) 项目。
这个项目的目标是聚合超过50万个高质量、可验证的数学问题,并最终完全开源!

对相关项目感兴趣的朋友们可以点击下面的链接了解更多内容~
参考链接:
[1]https://arxiv.org/pdf/2501.04682v1
[2]https://x.com/NathanThinks/status/1877510438621163987
文章来自微信公众号 “量子位”,作者 “奇月”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
