自大 DeepSeek-v3 惊艳全场后:DeepSeek-V3 是怎么训练的|深度拆解
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网:
- R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
- R1 上线 API,对用户开放思维链输出
- R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini
- 最离谱的是,价格只有 OpenAI 的几十分之一
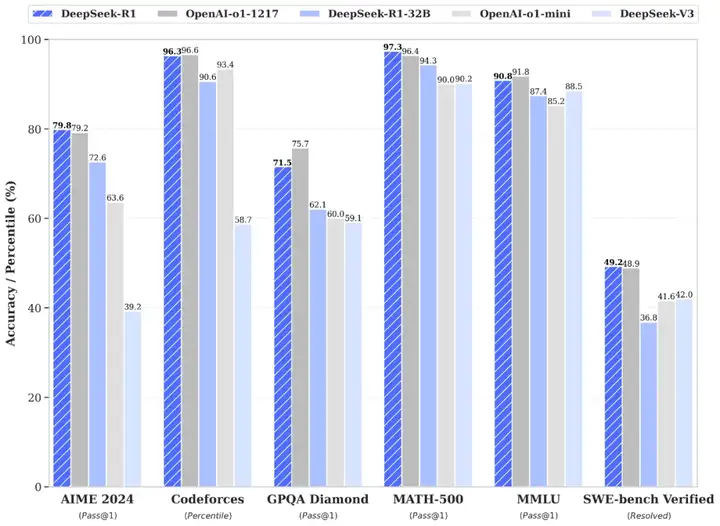
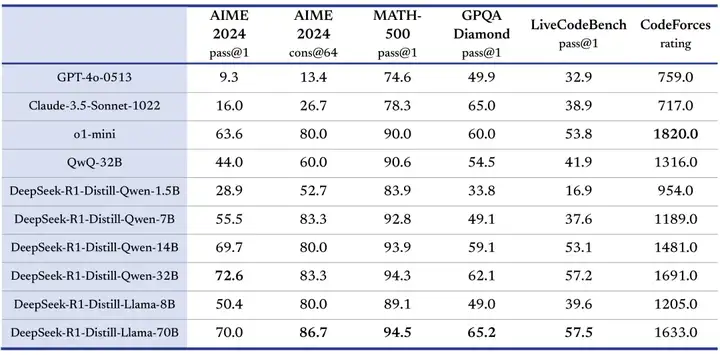
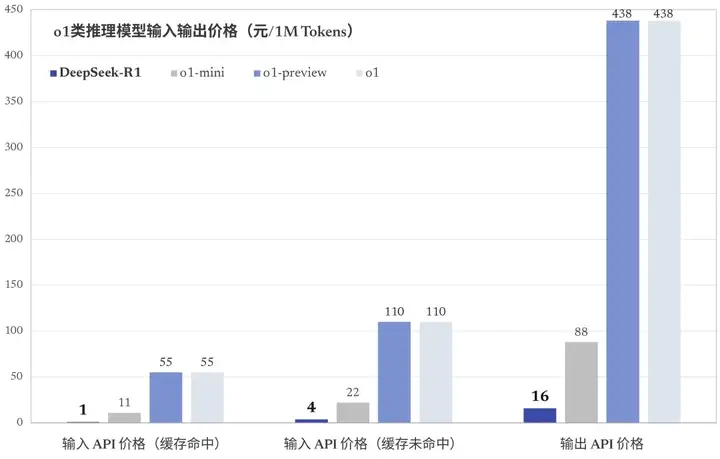
下面,让我们以更加系统的方式,来看看这次的 R1,是这么炼成的。
本文将从性能、方法、蒸馏、展望几个纬度来拆解 V3,所用到的图表、数据源于其论文:《R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。
添加客服微信:openai178,免费获得详细报告。
结论前置
- 先插入一句:除了 R1 之外,DeepSeek 还发布了 R1-Zero
- R1-Zero 基于 DeepSeek-V3-Base,纯粹通过 RL (强化学习) 训练,无 STF (监督微调)
- R1 则基于 R1-Zero,先利用少量人工标注的高质量数据进行冷启动微调,然后再进行 RL
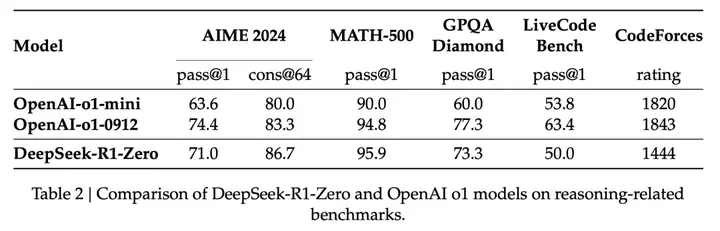
- 纯强化学习的有效性:R1-Zero 的训练,证明了仅通过 RL,无 SFT ,大模型也可以有强大的推理能力。在 AIME 2024 上,R1-Zero 的 pass@1 指标从 15.6% 提升至 71.0%,经过投票策略 (majority voting) 后更是提升到了 86.7%,与 OpenAI-o1-0912 相当 (表 2,第 7 页)。
- “顿悟”现象的出现:训练过程中,R1-Zero 出现了“顿悟”现象,能够自发地学习到新的、更有效的推理策略 。
- 蒸馏比小型模型直接 RL 更有效:将 R1 的推理能力蒸馏到小型模型 (如 Qwen 系列和 Llama 系列),比直接在这些小型模型上应用 RL 效果更好 (表 5,第 14 页)。例如,R1-Distill-Qwen-7B 在 AIME 2024 上得分 55.5%,远超 QwQ-32B-Preview;R1-Distill-Qwen-32B 更是取得了 72.6% 的惊人成绩 。这说明大型模型在 RL 过程中学到的推理模式具有通用性和可迁移性。
- 冷启动数据的价值:R1 相较于 R1-Zero,仅通过引入少量高质量的冷启动数据,便提升了 RL 的效率和最终性能。
性能评估
论文在多个维度对 R1 的性能进行了评估,涵盖了知识密集型任务、推理密集型任务、长文本理解任务和开放式问答任务,并与多个业界领先的基线模型进行了对比。在评估中,对比了包括 DeepSeek-V3、Claude-3.5-Sonnet-1022、GPT-4o-0513、OpenAI-o1-mini 以及 OpenAI-o1-1217 在内的模型:
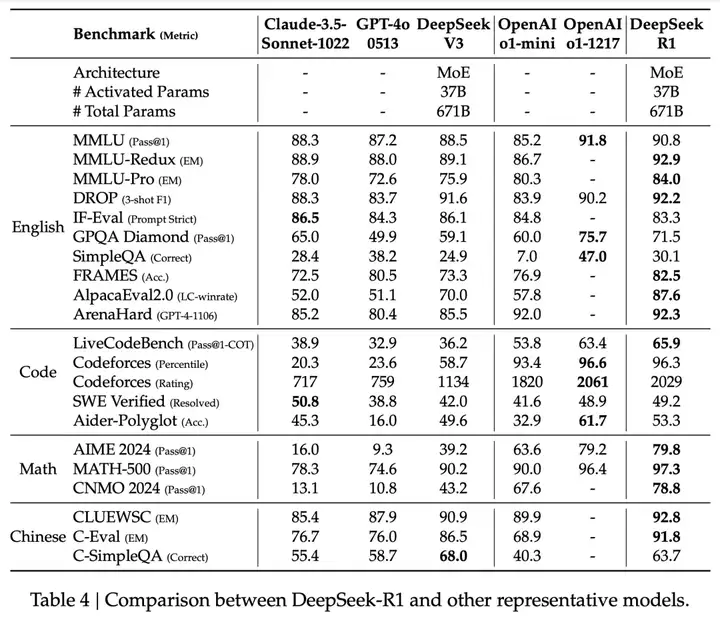
上表来自于论文中的表 4,阅读课得出以下结论:
- R1 在推理任务上表现出色,特别是在 AIME 2024 (美国数学邀请赛)、MATH-500 (数学竞赛题) 和 Codeforces (编程竞赛)等任务上,取得了与 OpenAI-o1-1217 相媲美甚至超越的成绩。
- 在 MMLU (90.8%)、MMLU-Pro (84.0%) 和 GPQA Diamond (71.5%) 等知识密集型任务基准测试中,性能显著超越了 DeepSeek-V3 模型。
- 在针对长上下文理解能力的 FRAMES 数据集上,R1 的准确率达到了 82.5%,优于 DeepSeek-V3 模型。
- 在开放式问答任务 AlpacaEval 2.0 和 Arena-Hard 基准测试中,R1 分别取得了 87.6%的 LC-winrate 和 92.3%的 GPT-4-1106 评分,展现了其在开放式问答领域的强大能力。
训练流程
R1-Zero
- 架构思路:纯粹的强化学习训练模式。 没有任何 SFT 数据的情况下,通过纯粹的强化学习。
- 算法应用:直接在 DeepSeek-V3-Base 模型上应用 GRPO 算法进行强化学习训练。
- 奖励机制:使用基于规则的奖励机制,包括准确性奖励和格式奖励,来指导模型的学习。
- 训练模板:采用了简洁的训练模板,要求模型首先输出推理过程 (置于标签内),然后给出最终答案 (置于标签内)。

- “顿悟”时刻:R1-Zero 的训练过程中还出现了“顿悟”现象。例如,表 3 (第 9 页) 展示了一个 R1-Zero 在解决一道数学题时的中间版本输出。在这个例子中,模型在推理过程中突然意识到可以“重新评估”之前的步骤,并尝试用一种新的方法来解题。

性能表现: 展示了 R1-Zero 在 AIME 2024 基准测试上的性能变化曲线。随着 RL 训练的进行,模型的 pass@1 指标从最初的 15.6% 稳步提升至 71.0%,达到与 OpenAI-o1-0912 相当的水平。(第 7 页,图 2)。
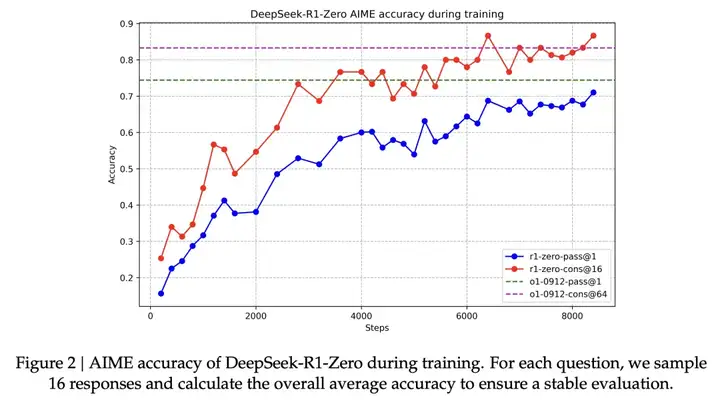
在 AIME 2024、MATH-500 等数学推理任务上,以及 GPQA Diamond 等知识问答任务上,R1-Zero 均取得了与 OpenAI-o1-0912 相媲美的成绩,部分任务甚至有较大的领先。(第 7 页,表 2)
R1
- 架构思路:在 DeepSeek-V3-Base 模型的基础上,先利用少量高质量的 “冷启动” (Cold Start) 数据进行微调,然后再进行强化学习。 这种方法结合了监督学习和强化学习的优势,既可以利用人类的先验知识引导模型,又可以发挥强化学习的自学习和自进化能力。
- 冷启动阶段:使用数千个高质量的人工标注样本对 DeepSeek-V3-Base 模型进行微调,作为强化学习训练的初始模型。为了构建高质量的冷启动数据,DeepSeek 团队尝试了多种方法,包括:
- 使用带有长 CoT 的 few-shot prompting。
- 直接提示模型生成带有反思和验证的详细解答。
- 收集 R1-Zero 的输出,并进行人工标注和格式化。
- 面向推理的强化学习:在冷启动阶段之后,R1 采用了与 R1-Zero 类似的强化学习训练流程,但针对推理任务进行了特别优化。为了解决训练过程中可能出现的语言混杂问题,R1 引入了一个语言一致性奖励 (Language Consistency Reward),该奖励根据 CoT 中目标语言单词的比例来计算。
- 拒绝采样与监督微调:当面向推理的强化学习收敛后,R1 利用训练好的 RL 模型进行拒绝采样 (Rejection Sampling),生成新的 SFT 数据。与之前的冷启动数据不同,这一阶段的 SFT 数据不仅包含推理任务,还涵盖了其他领域的数据,例如写作、角色扮演、问答等,以提升模型的通用能力。
- 面向全场景的强化学习:在收集了新的 SFT 数据后,R1 会进行第二阶段的强化学习训练,这一次,训练的目标不再局限于推理任务,而是涵盖了所有类型的任务。此外, R1 采用了不同的奖励信号和提示分布, 针对不同的任务类型进行了优化。例如, 对于数学、代码和逻辑推理等任务, 采用基于规则的奖励;对于开放式问答、创意写作等任务, 则采用基于模型的奖励。
核心方法
GRPO
R1 采用的核心算法是 Group Relative Policy Optimization (GRPO) 算法,并辅以精心设计的奖励机制来指导模型的学习。与传统的需要构建 Critic 模型来估计状态值函数的算法不同,GRPO 通过比较一组样本的奖励来估计优势函数 (Advantage),降低了训练过程的复杂度和所需的计算资源。GRPO 算法的目标函数和优势函数的计算公式在论文的 2.2.1 章节 (第 5 页) 中有详细的数学描述。

奖励系统
R1-Zero 的奖励系统,主要以下两类:
- 准确性奖励 (Accuracy Rewards): 评估模型生成的响应是否正确。对于具有确定性答案的任务 (例如数学题),模型需要将最终答案放在特定格式 (例如,放在一个方框内) 中,以便进行自动验证。对于代码生成任务 (例如 LeetCode 题目),则利用编译器对生成的代码进行测试。
- 格式奖励 (Format Rewards): 强制模型将推理过程放在 和 标签之间,以便于分析和理解模型的推理过程。
训练模板
R1-Zero 采用了一种简洁的训练模板 (表 1,第 6 页),要求模型首先输出推理过程,然后给出最终答案。模板如下:

其中,prompt 会在训练过程中,被替换为具体的推理问题。
模型蒸馏
DeepSeek 团队进一步探索了将 R1 的推理能力蒸馏到更小的模型中的可能性。他们使用 R1 生成的 800K 数据,对 Qwen 和 Llama 系列的多个小模型进行了微调。表 5 (第 14 页) 展示了模型蒸馏的结果。
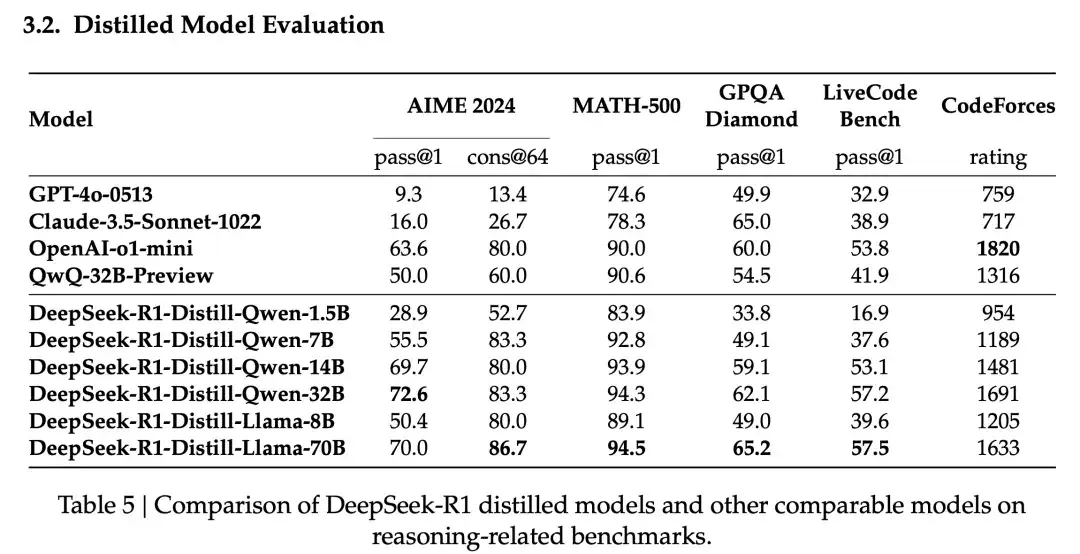
可以看出:
- 经过 R1 蒸馏的小模型,在推理能力上得到了显著提升,甚至超越了在这些小模型上直接进行强化学习的效果。 例如,R1-Distill-Qwen-7B 在 AIME 2024 上的得分达到了 55.5%,远超 QwQ-32B-Preview。
- R1-Distill-Qwen-32B 在 AIME 2024 上得分 72.6%,在 MATH-500 上得分 94.3%,在 LiveCodeBench 上得分 57.2%,这些结果显著优于之前的开源模型,并与 o1-mini 相当。
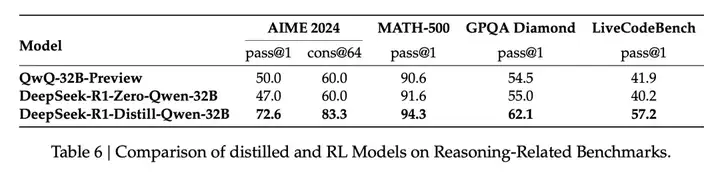
表 6 (第 14 页) 对比了 R1-Distill-Qwen-32B 和 R1-Zero-Qwen-32B 的性能。 结果表明,直接在 Qwen-32B-Base 上进行强化学习,只能达到与 QwQ-32B-Preview 相当的水平,而经过 R1 蒸馏的 Qwen-32B 模型则远超两者。这说明,R1 学到的推理模式具有很强的通用性和可迁移性,可以通过蒸馏的方式传递给其他模型。
还有更多
在论文的最后,DeepSeek 团队也探讨了 R1 模型的局限性,并提出了未来的研究方向:
局限性:
- 通用能力:R1 的通用能力 (例如函数调用、多轮对话、复杂角色扮演和 json 输出) 仍落后于 DeepSeek-V3。
- 语言混杂:R1 在处理非中英文问题时,可能会出现语言混杂现象。
- 提示词工程:R1 对提示词较为敏感,使用 few-shot 提示可能会降低其性能。
- 软件工程任务:由于 RL 训练的评估周期较长,R1 在软件工程任务上的性能提升有限。
未来工作:
- 探索如何利用长 CoT 提升 R1 在通用能力上的表现。
- 解决 R1 的语言混杂问题。
- 优化 R1 的提示词策略。
- 将 RL 应用于软件工程任务,提升 R1 在该领域的性能。
- 继续探索更有效的强化学习算法和奖励机制,进一步提升模型的推理能力。
- 研究如何将 R1 的推理能力更好地应用于实际场景,例如科学研究、代码生成、药物研发等。
额外的
DeepSeek 团队在研究过程中也尝试了一些其他方法,但并未取得理想的效果,例如:
- Process Reward Model (PRM): PRM 的构建和训练都存在较大挑战,且容易导致奖励“hack”。
- Monte Carlo Tree Search (MCTS): MCTS 在 token 生成任务中面临搜索空间过大的问题,且 value model 的训练较为困难。
文章来自微信公众号 “ 赛博禅心 “,作者 ” 金色传说大聪明 “



