# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Google Fellow吴永辉博士离职谷歌,正式加入字节跳动,未来将专注于AI基础研究。这位在谷歌深耕17年AI老将,曾主导了神经机器翻译、RankBrain等突破性项目。
谷歌17年老将,正式加入字节跳动。
据报道,吴永辉博士已确认离职谷歌,加盟字节负责AI基础研究领域的工作。

他将在字节担任大模型团队Seed基础研究负责人,专注于大模型基础研究搜索、AI for Science科研工作,直接向CEO梁汝波汇报。

2008年9月,吴永辉博士最初作为一名排序工程师加入谷歌,致力于改进谷歌核心网页搜索排名的算法。

自2015年1月起,他转入了Google Brain团队,专注于深度学习及其应用研究。他是谷歌神经机器翻译和RankBrain项目的核心贡献者,推动了语音识别的技术发展。
直到2023年,他又晋升为谷歌DeepMind研究副总裁,Google Fellow级别。
要知道,Google Fellow是谷歌顶尖工程师才能享有的称号,只有极少数的员工能够获得这个头衔。
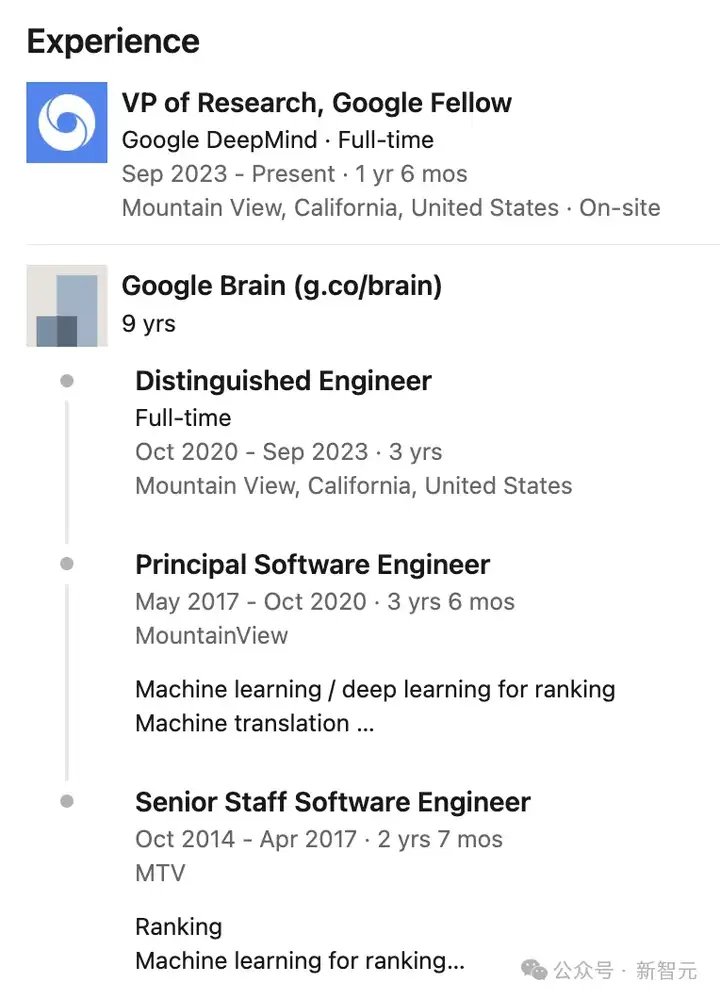
有网友为此,还做了非常详细的解说,成为Google Fellow(10级)是一个终身荣誉。
值得一提的是,目前谷歌只有两位Senior Fellow(11级,相当于高级副总裁):Sanjay Ghemawat和Jeff Dean。
以下是Google工程师的职级体系,从1级开始:
L1:IT支持人员
L2:应届大学毕业生
L3:拥有硕士学位
L4:需要几年工作经验或博士学位
L5:大多数工程师的职业发展止步于此
L6:顶尖10%的工程师,他们的能力往往能决定项目的成败
L7:具有长期优秀业绩记录的L6级工程师
L8:Principal Engineer(首席工程师),通常负责某个重要产品或基础设施
L9:Distinguished Engineer(杰出工程师),令人敬仰的存在
L10:Google Fellow,这是终身荣誉,获得者通常是该领域全球顶尖专家
L11:Google Senior Fellow,目前公司仅有的两位11级工程师是Jeff Dean和Sanjay Ghemawat

吴永辉曾获得了南京大学计算机学士学位,并于2008年获得了加州大学河滨分校的数据科学硕士学位和计算机科学博士学位。

他的研究兴趣包括信息检索、排序学习、机器学习、机器翻译、自然语言处理等领域。

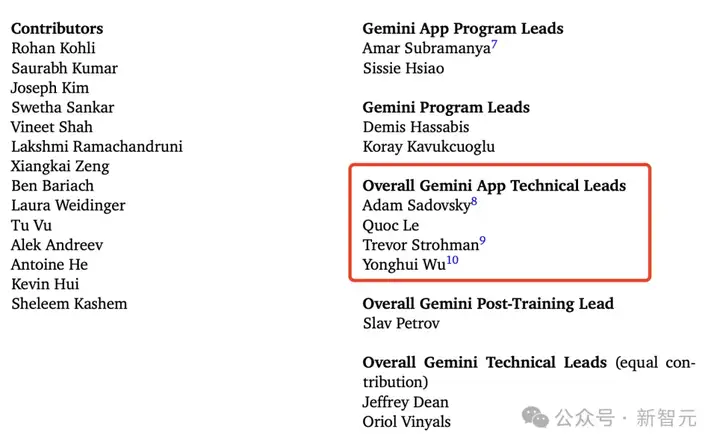
作为谷歌大牛,吴永辉参与了Gemini模型的开发,在团队贡献名单中,是Gemini应用总技术负责人之一。
他也参与了Gemini 1.5的研发,将大模型上下文扩展到100万token。
论文地址:https://arxiv.org/pdf/2312.11805
他还是Palm 2大模型训练团队的核心贡献者。

论文地址:https://arxiv.org/pdf/2305.10403
根据谷歌Scholar个人介绍,截至目前,吴永辉总被引数超5万,h-index为72。
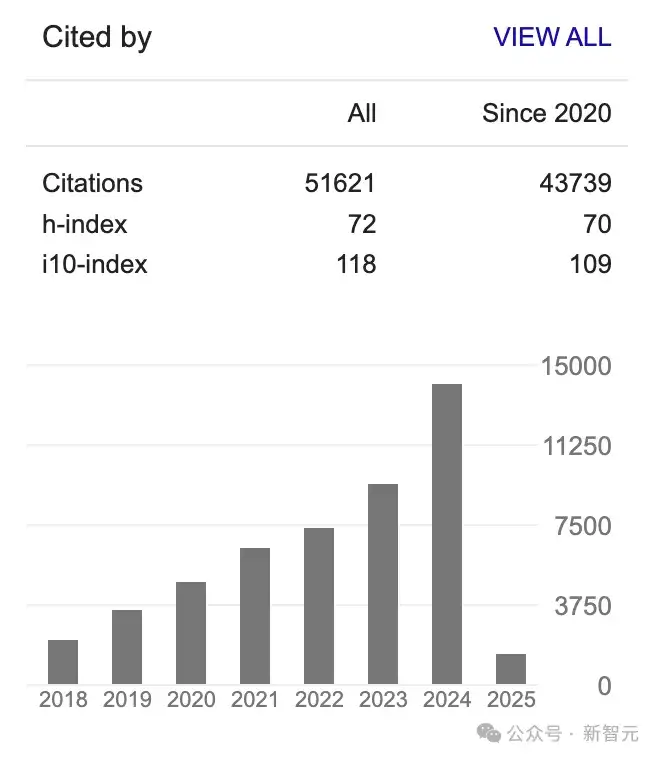
其中,被引数最高的文章便是2016年发表的——Google's Neural Machine Translation System。

论文地址:https://arxiv.org/pdf/1609.08144
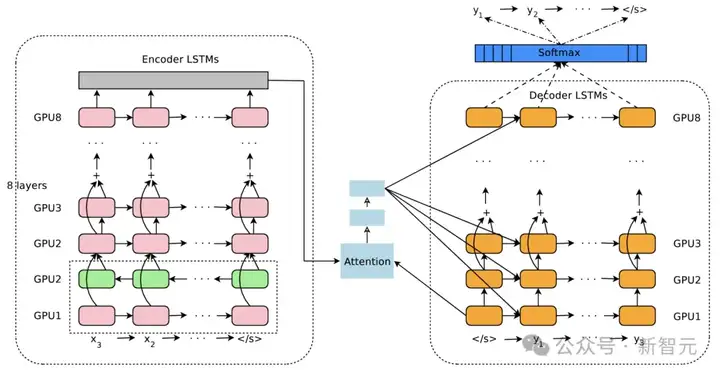
这篇论文主要提出了神经机器翻译系统:GNMT,由一个深度LSTM网络构成,包含8层编码器和8层解码器,使用了注意力机制和残差连接。
为了提高并行性并缩短训练时间,注意力机制将解码器的底层连接到编码器的顶层。
为了更好地处理稀有词汇,作者还将词汇分解为一组有限的常见子词单元(wordpieces),同时用于输入和输出。这种方法在「字符」分隔模型的灵活性和「词」分隔模型的高效性之间提供了良好的平衡,能够自然处理稀有词汇的翻译,最终提高了系统的整体准确性。
在WMT’14 英语-法语和英语-德语基准测试中,通过对一组独立简单句子的人工对比评估,相比于谷歌基于短语的生产系统,GNMT将翻译错误减少了60%。
其次,被引第二高是2020年发表的Conformer,一个语音识别模型,基于Transformer改进而来。
主要改进的点在于,提取长序列依赖的时候更有效,而卷积则擅长提取局部特征,因此将卷积应用于Transformer的Encoder层,同时提升模型在长期序列和局部特征上的效果。
实际证明,该方法确实有效,在当时的LibriSpeech测试集上取得了最好的效果。

参考资料:
https://scholar.google.com/citations?user=55FnA9wAAAAJ&hl=en
https://www.theinformation.com/articles/veteran-google-researcher-joins-bytedance-as-ai-rivalry-intensifies
文章来自于“新智元”,作“桃子”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
