# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。尽管这些方法已取得令人瞩目的成果,但由于 SMPL 在衣物表现上的局限性,以及缺乏大规模真实交互数据的支持,它们依然难以生成日常生活中的复杂交互场景。
相比之下,在 2D 生成模型中,由于大语言模型和海量文字 - 图片数据的支持,这一问题得到了有效的解决。2D 生成模型如今能够快速生成高度逼真的二维场景。而且,随着这些技术被引入到 3D 和 4D 生成模型中,它们成功地将二维预训练知识迁移到更高维度,推动了更精细的生成能力。然而,在处理 4D 人体 - 物体交互时,这些 3D/4D 生成的方法依然面临两个关键挑战:(1)物体与人体的接触发生在何处?又是如何产生的?(2)如何在人体与物体的动态运动过程中,保持它们之间交互的合理性?
为了解决这一问题,南洋理工大学 S-Lab 的研究者们提出了一种全新的方法:AvatarGO。该方法不仅能够生成流畅的人体 - 物体组合内容,还在有效解决穿模问题方面展现了更强的鲁棒性,为以人为核心的 4D 内容创作开辟了全新的前景。

想深入了解 AvatarGO 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!

近年来,随着人体 - 物体(HOI)交互数据集(如 CHAIRS [2], BEHAVE [3])的采集,以及扩散模型和 transformer 技术的迅速发展,基于文本输入生成 4D 人体动作和物体交互的技术已经展现出了巨大的潜力。然而,目前的技术大多集中于基于 SMPL 的人体动作生成,但它们难以真实呈现日常生活中人物与物体交互的外观。尽管 InterDreamer [4] 提出了零样本生成方法,能够生成与文本对齐的 4D HOI 动作序列,但其输出仍然受到 SMPL 模型的局限,无法完全突破这一瓶颈。
在另一方面,随着 3D 生成方法和大语言模型(LLM)的快速发展,基于文本的 3D 组合生成技术逐渐引起了广泛关注。这些技术能够深度理解复杂对象之间的关系,并生成包含多个主体的复杂 3D 场景。例如,GraphDreamer [5] 通过 LLM 构建图结构,其中节点代表对象,边表示它们之间的关系,实现了复杂场景的解耦;ComboVerse [6] 则提出空间感知评分蒸馏采样技术(SSDS),强化了空间的关联性。随后,其他研究 [13, 14] 进一步探索了联合优化布局以组合不同组件的潜力。但它们在生成 4D HOI 场景时,依然面临着两个核心挑战:
为了解决这些挑战,AvatarGO 提出了两项关键创新,以解决物体与人体应 “如何交互” 以及 “在哪里交互” 的问题:
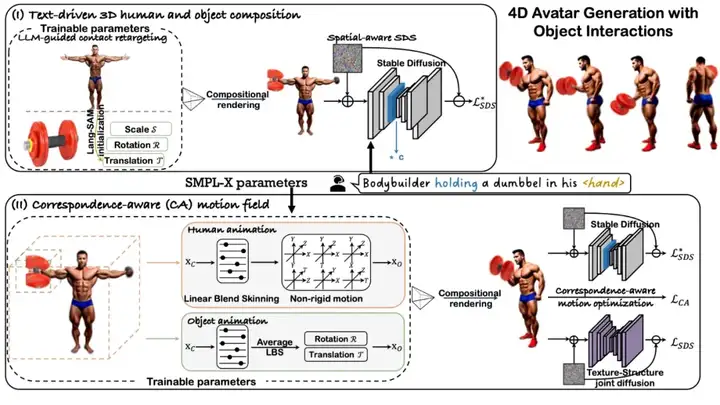
AvatarGO 以文本提示为输入,生成具有物体交互的 4D 虚拟人物。其框架核心包括:(1)文本驱动的 3D 人体与物体组合(text-driven 3D human and object composition):该部分利用大型语言模型(LLM)从文本中重定向接触区域,并结合空间感知的 SDS(空间感知评分蒸馏采样)来合成 3D 模型。(2)对应关系感知的动作优化(Correspondence-aware motion optimization):该优化方法联合优化人体和物体的动画,能够在动画过程中有效维持空间对应关系,从而提升对穿模问题的鲁棒性。

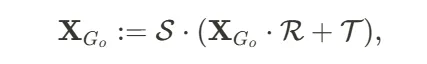

空间感知评分蒸馏采样(spatial-aware score distillation sampling):沿袭 ComboVerse [6] 的方法,我们采用 SSDS 来促进人体和物体之间的 3D 组合生成。具体而言,SSDS 通过用一个常数因子𝑐(其中𝑐>1)缩放指定标记 < token∗>的注意力图,从而增强 SDS 与人体和物体之间的空间关系。

在这里,<token∗>对应于编码人体 - 物体交互项的标记,如 <‘holding’>,这些标记可以通过大型语言模型(LLMs)识别,也可以由用户指定。

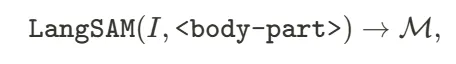
其中,<body-part>表示描述人体部位的文本,例如 <‘hand’>。
随后,他们通过逆向渲染将 2D 分割标签反投影到 3D 高斯上。具体来说,对于分割图上的每个像素𝑢,他们将掩模值(0或 1)更新回到高斯点云上:
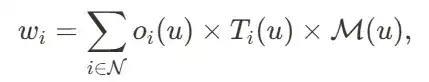








与其他 4D 生成方法的比较:下方视频展示了 AvatarGO 与现有 4D 生成方法(包括 DreamGaussian4D [7],HumanGaussian [12],TC4D [8])的对比。结果表明,1)即使有了人体 - 物体交互图像作为输入,DreamGaussian4D(采用视频扩散模型)在 4D 驱动时仍然面临困难;2)HumanGaussian 直接通过 SMPL LBS 函数直接进行的动画,往往会产生不流畅的效果,特别是对手臂的处理;3)TC4D 面临与 DreamGaussian4D 类似的问题,同时,它将整个场景视为一个整体,缺乏对单个物体的局部和大规模运动的处理。相比之下,AvatarGO 能够持续提供优越的结果,确保正确的关系并具有更好的穿模鲁棒性。

本文介绍了 AvatarGO,这是首次尝试基于文本引导生成具有物体交互的 4D 虚拟形象。在 AvatarGO 中,作者提出了利用大语言模型来理解人类与物体之间最合适的接触区域。同时,作者还提出了一种新颖的对应关系感知运动优化方法,利用 SMPL-X 作为中介,增强了模型在将 3D 人体和物体驱动到新姿势时,抵抗穿模问题的能力。通过大量的评估实验,结果表明 AvatarGO 在多个 3D 人体 - 物体对和不同姿势下,成功实现了高保真度的 4D 动画,并显著超越了当前的最先进技术。
局限性:在为以人为中心的 4D 内容生成开辟新途径的同时,作者同时也认识到 AvatarGO 存在一定的局限性:
1. AvatarGO 的流程基于 “物体是刚性体” 的假设,因此不适用于为非刚性内容(如旗帜)生成动画;
2. AvatarGO 的方法假设物体与人体之间持续接触,这使得像 “运篮球” 这样的任务难以处理,因为在某些时刻人与物体不可避免地会断开连接。
参考文献
[1] SMPL: A Skinned Multi-Person Linear Model. SIGGRAPH 2015.
[2] Full-Body Articulated Human-Object Interaction. arXiv 2212.10621.
[3] BEHAVE: Dataset and Method for Tracking Human Object Interactions. CVPR 2022.
[4] InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object Interaction. NeurIPS 2024.
[5] GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs. CVPR 2024.
[6] ComboVerse: Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance. ECCV 2024.
[7] DreamGaussian4D: Generative 4D Gaussian Splatting. arXiv 2312.17142.
[8] TC4D: Trajectory-Conditioned Text-to-4D Generation. ECCV 2024.
[9] Comp4D: Compositional 4D Scene Generation. arXiv 2403.16993.
[10] Language Segment-Anything. https://github.com/luca-medeiros/lang-segment-anything
[11] HexPlane: A Fast Representation for Dynamic Scenes. CVPR 2023
[12] HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting. CVPR 2024
[13] InterFusion: Text-Driven Generation of 3D Human-Object Interaction. ECCV 2024.
[14] Disentangled 3d scene generation with layout learning. ICML 2024.
[15] Gala3D: Towards Text-to-3D Complex Scene Generation via Layout-guidedGenerative Gaussian Splatting. ICML 2024
文章来自于“机器之心”,作者“机器之心”。



