# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DeepSeek开源周,今日正式收官!
内容依旧惊喜且重磅,直接公开了V3和R1训练推理过程中用到的文件系统。
具体来说,包括以下两项内容:

划重点就是,3FS可以把固态硬盘的带宽性能利用到极致,表现出了惊人的速度:
V3和R1中训练数据预处理、数据集加载、嵌入向量搜索和KV Cache查找等工作,3FS都立下了汗马功劳。
网友们表示,3FS和Smallpond为AI数据处理设定了新基准,将改变数据处理的游戏规则。
对于AI来说,这就像从自行车升级到了高铁。
根据DeepSeek团队介绍,3FS是一种高性能的分布式文件系统,面对的就是AI训练和推理工作负载的挑战。
它利用现代SSD和RDMA网络来提供共享存储层,从而简化分布式应用程序的开发。
SSD就是固态硬盘,而RDMA(远程直接访问,remote direct memory access)是一种直接存储器访问技术。
它可以在没有双方操作系统介入的情况下,将数据直接从一台计算机的内存传输到另一台计算机,也不需要中央处理器、CPU缓存或上下文交换参与。
特点就是高通量、低延迟,尤其适合在大规模并行计算机集群中使用。
具体到3FS,具有以下特点:
并且,3FS能够适用于大模型训练推理和过程中不同类型的应用负载:
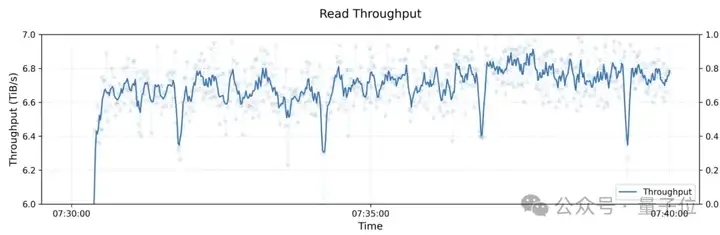
在大型3FS集群上的读取测试中,实现了惊人的高吞吐量。
该集群由180个存储节点组成,每个存储节点配备2×200Gbps InfiniBand网卡和16个14TB NVMe SSD。
大约500+个客户端节点用于读压测,每个客户端节点配置1x200Gbps InfiniBand网卡。
在训练作业的背景流量下,最终聚合读吞吐达到约6.6TB/s。
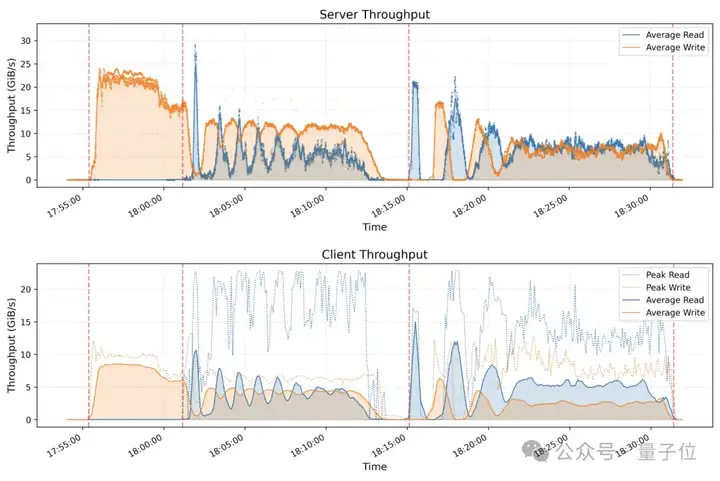
DeepSeek还用GraySort基准测试评估了基于3FS构建的smallpond框架,该基准测试可测量大规模数据集的排序性能。
测试分为两个阶段,先用键的前缀位通过shuffle对数据进行分区,然后进行分区内排序。两个阶段既需要从3FS读取,也需要向3FS写入数据。
测试集群包含25个存储节点(2个NUMA域/节点、1个存储服务/NUMA、2×400Gbps NIC/节点)和50个计算节点(2个NUMA域、192个物理核心、2.2 TB RAM 和1×200 Gbps NIC/节点)。
最终对8192个分区中110.5TB数据进行排序,耗时30分14秒,平均吞吐量为3.66TB/分钟。
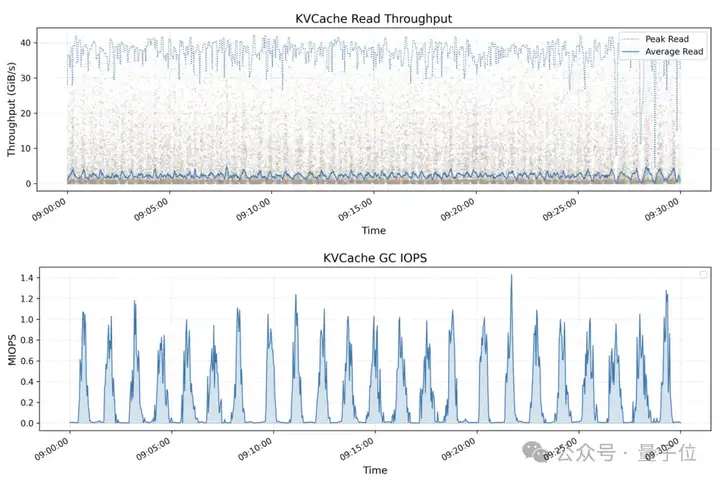
另外,KV缓存客户端的读取吞吐量,峰值也达到了40GB/s。
回顾DeepSeek这五天开源的内容,几乎都和AI Infra相关:
并且主打的就是极度压缩成本,降低消耗的同时将各种硬件的性能全部发挥到极致。
而另外一边,有网友已经在期待V4和R2的上线了。
至此,DeepSeek开源周的连载也要告一段落了,但DeepSeek后续动作依然值得持续关注。
项目地址:
https://github.com/deepseek-ai/3FS
参考链接:
https://x.com/deepseek_ai/status/1895279409185390655
文章来自微信公众号 “ 量子位 “,作者 克雷西



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
