# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国内首个以国产全功能GPU为底座的大规模算力集群,正式落地了!
这便是来自摩尔线程的KUAE智算中心,全国产千卡千亿模型训练平台。

摩尔线程CEO张建中在主题演讲中带来重磅发布,包括大模型智算加速卡MTT S4000,以及专为千亿参数大模型训练和推理提供强大支持的摩尔线程KUAE平台,他表示:
摩尔线程KUAE智算中心的正式启用,是公司发展的重要里程碑。
摩尔线程构建了从芯片到显卡到集群的智算产品线,依托全功能GPU的多元计算优势,旨在满足不断增长的大模型训练和推理需求,以绿色、安全的智能算力,大力推动AIGC、数字孪生、物理仿真、元宇宙等多模态应用的落地和千行百业的高质量发展。
与此同时,摩尔线程联合国内众多合作伙伴发起并成立了摩尔线程PES -KUAE智算联盟和摩尔线程PES-大模型生态联盟,共同夯实从智算基础设施到大模型训练与推理的国产大模型一体化生态,持续为我国大模型产业发展加速。
摩尔线程大模型智算加速卡MTT S4000,采用第三代MUSA内核,单卡支持48GB显存和768GB/s的显存带宽。
基于摩尔线程自研MTLink1.0技术,MTT S4000可以支持多卡互联,助力千亿大模型的分布式计算加速。
同时,MTT S4000提供先进的图形渲染能力、视频编解码能力和超高清8K HDR显示能力,助力AI计算、图形渲染、多媒体等综合应用场景的落地。
尤为重要的是,借助摩尔线程自研MUSIFY开发工具,MTT S4000计算卡可以充分利用现有CUDA软件生态,实现CUDA代码零成本迁移到MUSA平台。

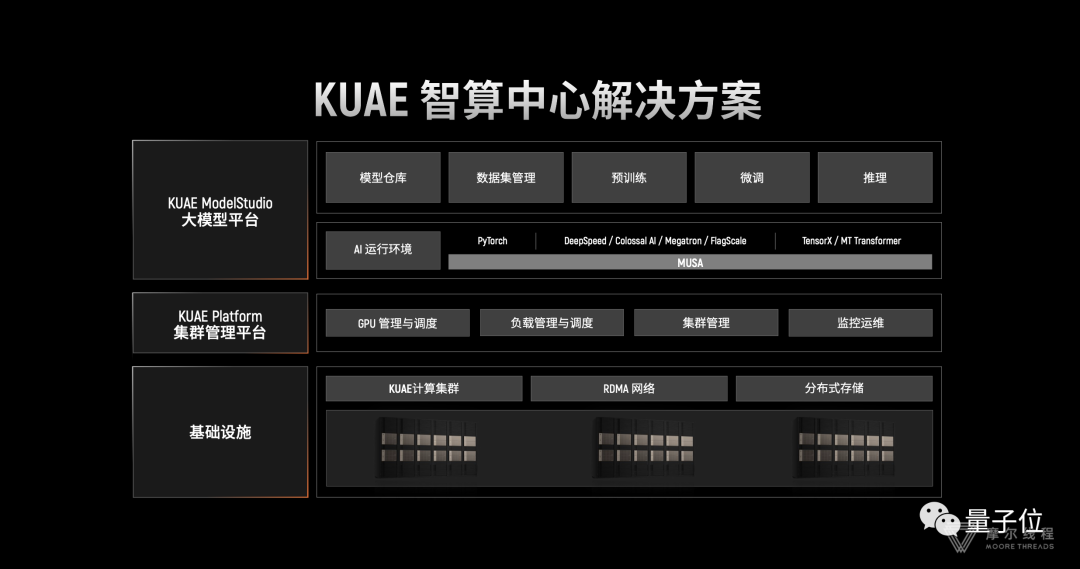
摩尔线程KUAE智算中心解决方案以全功能GPU为底座,是软硬一体化的全栈解决方案,包括以KUAE计算集群为核心的基础设施、KUAE Platform集群管理平台以及KUAE ModelStudio模型服务,旨在以一体化交付的方式解决大规模GPU算力的建设和运营管理问题。
该方案可实现开箱即用,大大降低传统算力建设、应用开发和运维运营平台搭建的时间成本,实现快速投放市场开展商业化运营。
分布式并行计算是实现AI大模型训练的关键手段。
摩尔线程KUAE支持包括DeepSpeed、Megatron-DeepSpeed、Colossal-AI、FlagScale在内的业界主流分布式框架,并融合了多种并行算法策略,包括数据并行、张量并行、流水线并行和ZeRO,且针对高效通信计算并行和Flash Attention做了额外优化。

目前,摩尔线程支持包括LLaMA、GLM、Aquila、Baichuan、GPT、Bloom、玉言等各类主流大模型的训练和微调。
基于摩尔线程KUAE千卡集群,70B到130B参数的大模型训练,线性加速比均可达到91%,算力利用率基本保持不变。
以2000亿训练数据量为例,智源研究院700亿参数Aquila2可在33天完成训练;1300亿参数规模的模型可在56天完成训练。
此外,摩尔线程KUAE千卡集群支持长时间连续稳定运行,支持断点续训,异步Checkpoint少于2分钟。
摩尔线程KUAE千卡计算集群凭借高兼容性、高稳定性、高扩展性和高算力利用率等综合优势,将成为大模型训练坚实可靠的先进基础设施。
大模型时代,以GPU为代表的智能算力是基石,也是生成式AI世界的中心。
摩尔线程联合中国移动北京公司、中国电信北京分公司、联想、世纪互联、光环新网、中联数据、数道智算、中发展智源、企商在线、北电数智北京数字经济算力中心、紫光恒越、瑞华产业控股(山东)、赛尔网络、中科金财、中耘智算、金舟远航(排名不分先后)等十余家企业,共同宣布“摩尔线程PES - KUAE智算联盟”成立。
联盟将大力建设和推广从底层硬件到软件、工具到应用的全国产智算平台,旨在实现集群的高利用率,以好用、易用的全栈智算解决方案成为大模型训练首选。

活动现场,摩尔线程分别与中联数据和数道智算进行了现场签约,并共同为摩尔线程KUAE智算中心揭牌。
现场200多名与会嘉宾一同见证了这一重要时刻。


人工智能应用的突破,生态是关键。
为此,摩尔线程携手360、飞桨、京东言犀、智谱AI、超对称、无问芯穹、滴普科技、网易、清华大学、复旦大学、浙江大学、北京理工大学、凌云光、瑞莱智慧、南威软件(排名不分先后)等多家大模型生态伙伴,发起并成立“摩尔线程PES - 大模型生态联盟”。
摩尔线程将以MUSA为中心的软硬一体化大模型解决方案,积极与广泛的生态伙伴开展兼容适配及技术调优等工作,共同推动国产大模型生态的全面繁荣。

在最后的圆桌对话环节,摩尔线程副总裁董龙飞与中能建绿色数字科技(中卫)有限公司董事长墙虎、智谱AI CEO张鹏、京东云首席AI科学家裴积全、中金资本董事总经理翟赢、超对称创始人吴恒魁、数道智算董事长甄鉴等重磅嘉宾,就当前大模型的算力需求和智算中心的建设与运营等话题展开了深入探讨。
嘉宾一致认为,智算中心不应只是硬件的堆积,更是对软硬一体化的GPU智算系统整合能力的考验,GPU分布式计算系统的适配、算力集群的管理和高效推理引擎的应用等,都是提高算力中心可用性的重要因素。
国产智算中心的发展,更是依托于将各方需求和优势充分融合,产业聚力才能实现整个生态的协同,推动国产事业往前发展。




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
