# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
凭借对文本、图像、语音等多模态数据的融合处理能力,多模态大模型实现了更为丰富、全面的理解与生成,在复杂场景中表现得更接近人类水平,已然成为人工智能领域的重要发展方向。
然而,随着评测基准的激增,数据污染问题日益凸显,导致模型在评测中“记住”答案,从而高估了模型性能,降低了评测基准的可信度。为解决这一问题,司南推出了多模态模型闭源评测基准,评测数据动态更新迭代,包含多项细分评估维度,确保测试数据的新颖性和客观性,从而真实评估多模态模型的综合能力,为模型评估提供更可靠、更全面的基准。
基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。
首期榜单共包含 48 个多模态模型,其中包含:
整体性能排名
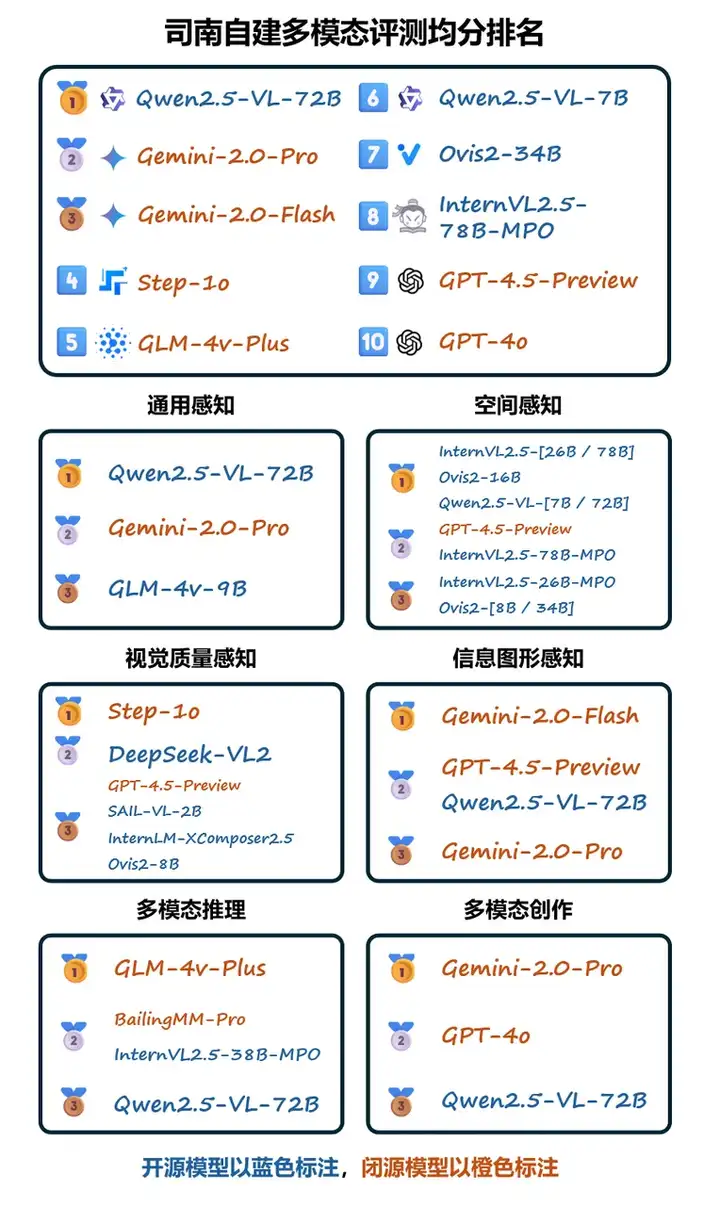
在本次评测中,多模态大模型的整体表现差异明显,平均得分从 17.60(最低)到 48.25 (最高)。性能排名最高的模型是 Qwen2.5-VL-72B ,而最低的则是 LLaVA-v1.5-7B。
在整体性能上,开源模型 Qwen2.5-VL-72B 排名第一,其在 通用感知、空间感知和信息图表理解 三个维度上领跑所有模型,表现优异。然而,在 视觉质量感知 和 多模态推理 这两个方面仍有较大提升空间,尤其是在复杂推理任务中,该模型的得分相对较低,说明当前的多模态推理能力仍为一个待突破的方向。在 Qwen2.5-VL-72B 之后,4个商业 API 模型:Gemini-2.0-Pro, Gemini-2.0-Flash, Step-1o, GLM-4v-Plus 分别占据榜单的 2-5 名。
除 Qwen2.5-VL-72B 之外,其他开源模型,如 Qwen2.5-VL-7B, Ovis2-34B, InternVL2.5-78B-MPO 也取得了较高排名。在小参数量模型中,Qwen2.5-VL-7B 以 7B 参数量取得了 第六名 的亮眼成绩,超越了 GPT-4.5,Claude-3.5-Sonnet 等一系列闭源 API 模型 ,表明即使在较小的参数规模下,合理的架构和优化依然能够带来极具竞争力的多模态能力。
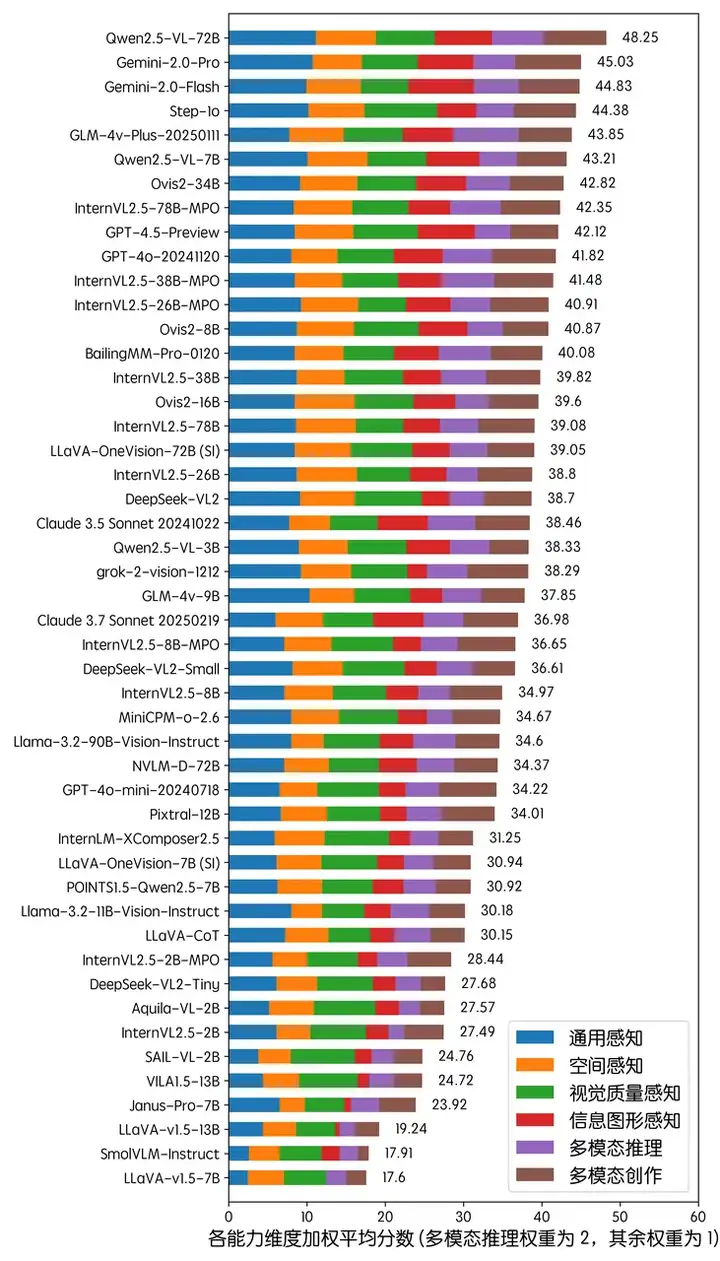
深层洞察
此外,在本次 OpenCompass 多模态闭源评测 中,我们观察到了一些值得注意的趋势和洞察点,我们将其总结如下:
闭源评测 排名趋势与 多模态公开学术榜单 基本一致:本次闭源评测结果与此前公开学术榜单 (基于 MMBench,MMMU,MathVista 等公开学术测评集综合得分进行排名) 展现出 高度一致性,但在细节排名上有特定差异:
海外闭源模型 多模态理解性能趋于瓶颈:在全球主流的闭源 API 模型中,整体的 多模态理解能力 似乎已经进入 性能瓶颈期 ,并未再出现 显著提升 :
开源模型架构 选型上,视觉编码器选型分歧较大,但语言模型趋于统一:在本次评测中,我们发现 开源多模态模型的架构选择 呈现出 视觉编码器多样化,语言模型统一化 的现象:
开源多模态模型的整体进步:回顾 2024 年初(LLaVA-1.5 时代)以来的发展 ,开源多模态模型已经实现了跨越式提升。
理解-生成一体化 模型目前仍处于早期阶段:当前阶段 理解-生成一体化 的开源模型,如 Janus-Pro-7B ,其理解能力仍然薄弱 ,相比于专注于理解任务的模型,其多模态推理能力排名较为靠后,综合能力仅略优于 LLaVA-v1.5 基线。这说明目前的开源方案在泛化理解、知识推理以及复杂视觉任务上的能力仍然存在一定瓶颈。
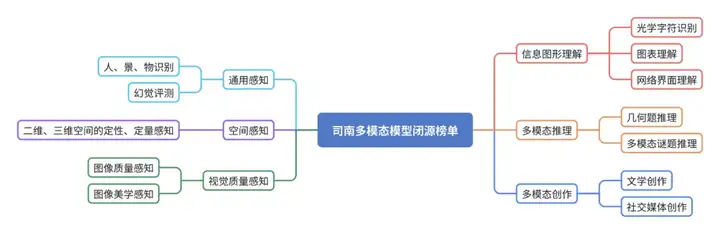
本榜单基于闭源测试数据,对不同多模态模型在通用感知、空间感知、视觉质量感知、信息图形理解、多模态推理、多模态创作六大能力维度上的表现进行了评测,并基于归一化分数计算模型的平均得分进行排序。闭源评测基准拥有较为丰富的题目类型,包含单选、多选、填空、开放性创作等,且为中英文双语,可以同时考验模型的多语言理解能力。

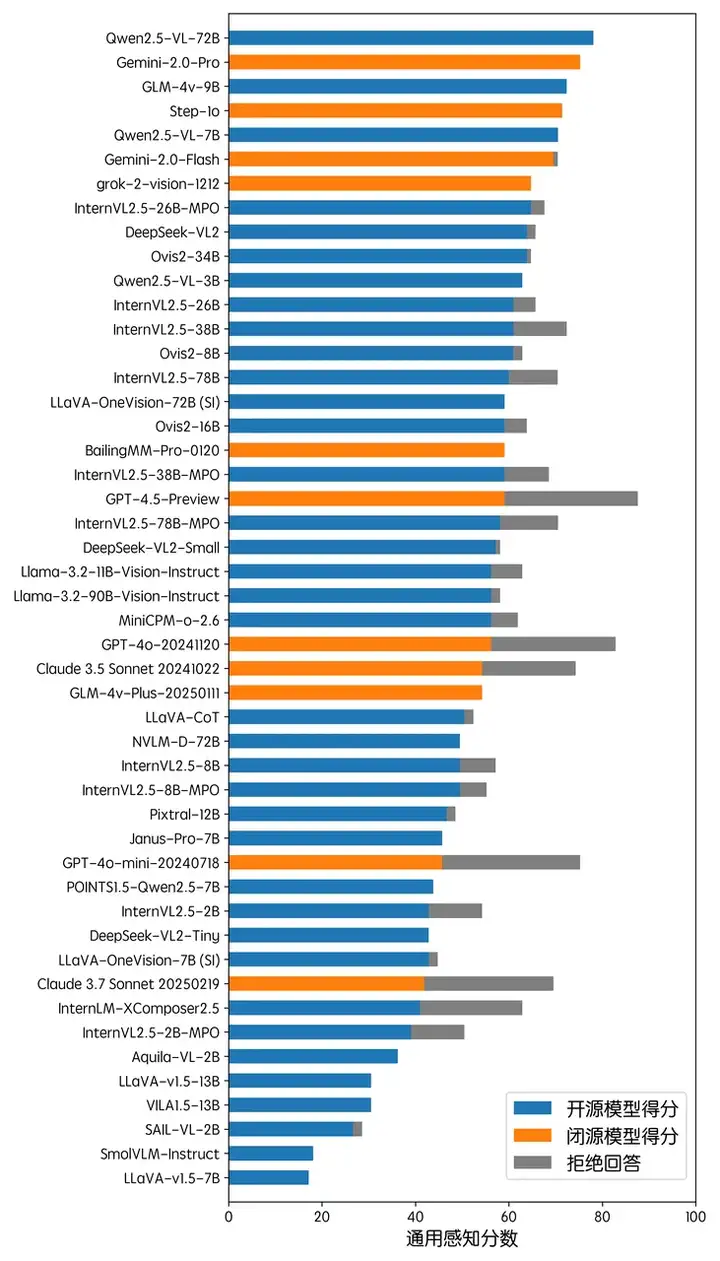
通用感知
在通用感知能力方面,开源模型 Qwen2.5-VL-72B 排名第一。但需注意的是,在通用感知测试中存在涉及人物识别的问题,而部分闭源 / 开源模型会对此类问题产生拒答 (其中 GPT-4.5,GPT-4o,Claude 3.5 / 3.7,InternVL 等模型均在不同程度上有此类现象)。下方的性能展示图片也标注了每个模型的拒答比率。
视觉质量感知
在视觉质量感知方面,不同模型间的能力差异不大,开源与闭源模型间亦不存在较大差异。值得注意的是,小参数量模型,如 SAIL-VL-2B, Aquila-VL-2B 等,在视觉质量感知上也展现了突出的性能。
空间感知
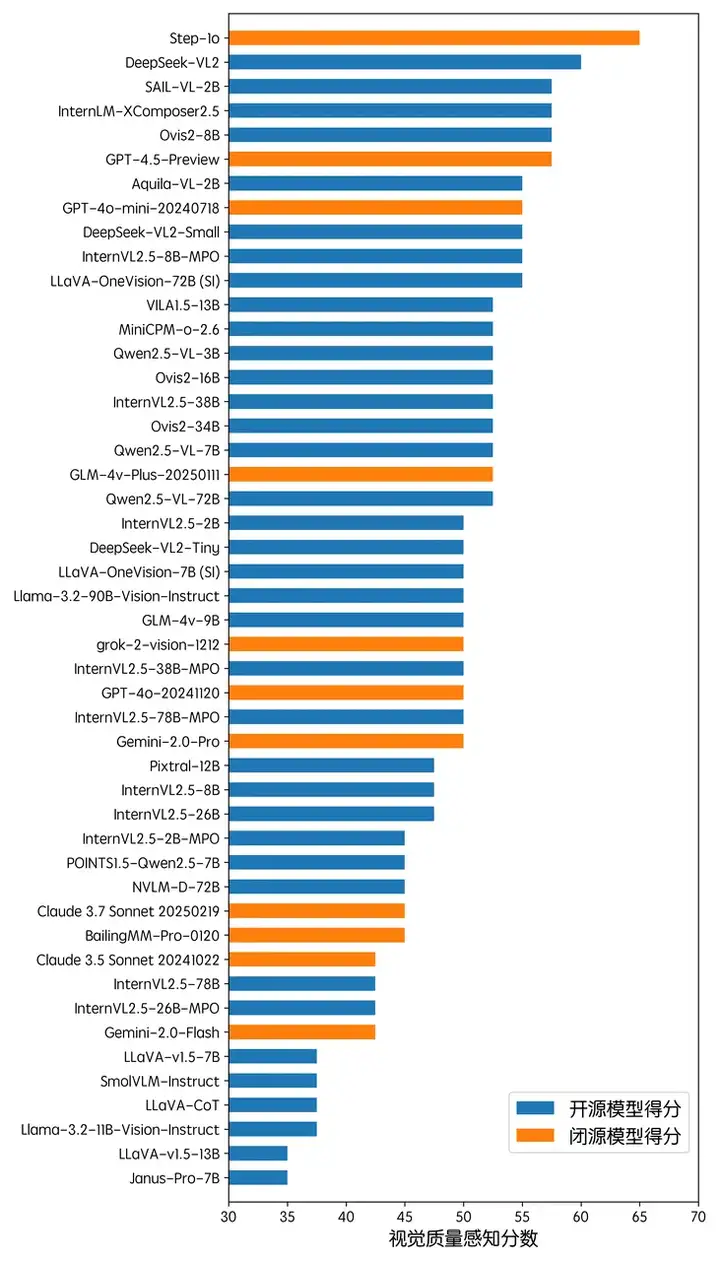
整体而言,在空间感知方面,当前多模态大模型的能力整体仍相对较差,模型取得的最高分数仍不到 60 分。值得注意的是,开源模型,如 InternVL2.5 及 Qwen2.5-VL 等模型,在空间感知测试中取得了最佳的成绩,超越了 Gemini2.0 等一系列 API 模型。大部分闭源模型在空间感知方面的能力相对不尽如意。
信息图形感知
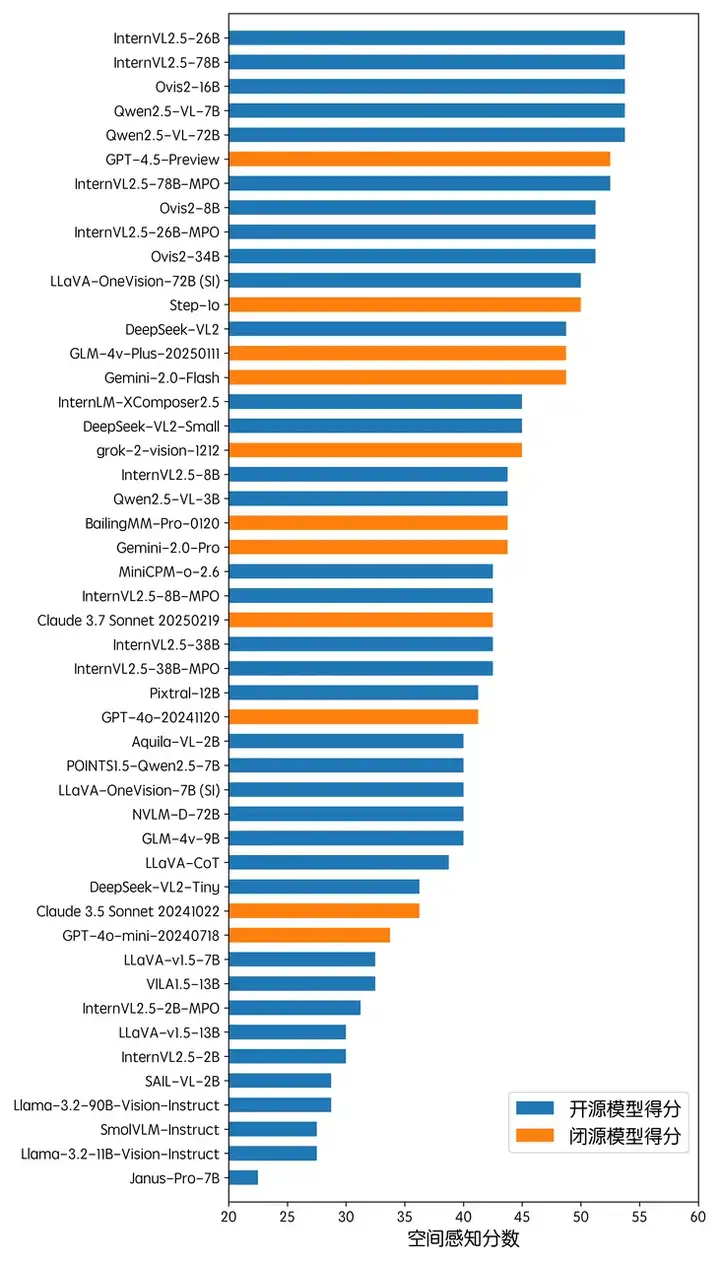
在信息图形感知方面,Gemini-2.0-Flash 在评测中取得了最佳的成绩,并以较大幅度领先于第 2 位的 Qwen2.5-VL-72B。整体上,闭源 API 模型在信息图形理解方面的性能处于领先的地位,占据了前 10 名中的 7 席。整体上,当前多模态大模型的信息图形理解能力仍不尽如意,在这一具备挑战性的测试上,最强的 Gemini-2.0-Flash 也仅取得了不到 60 的总分,而 LLaVA-v1.5-7B 基线甚至未能获得分数。
多模态推理
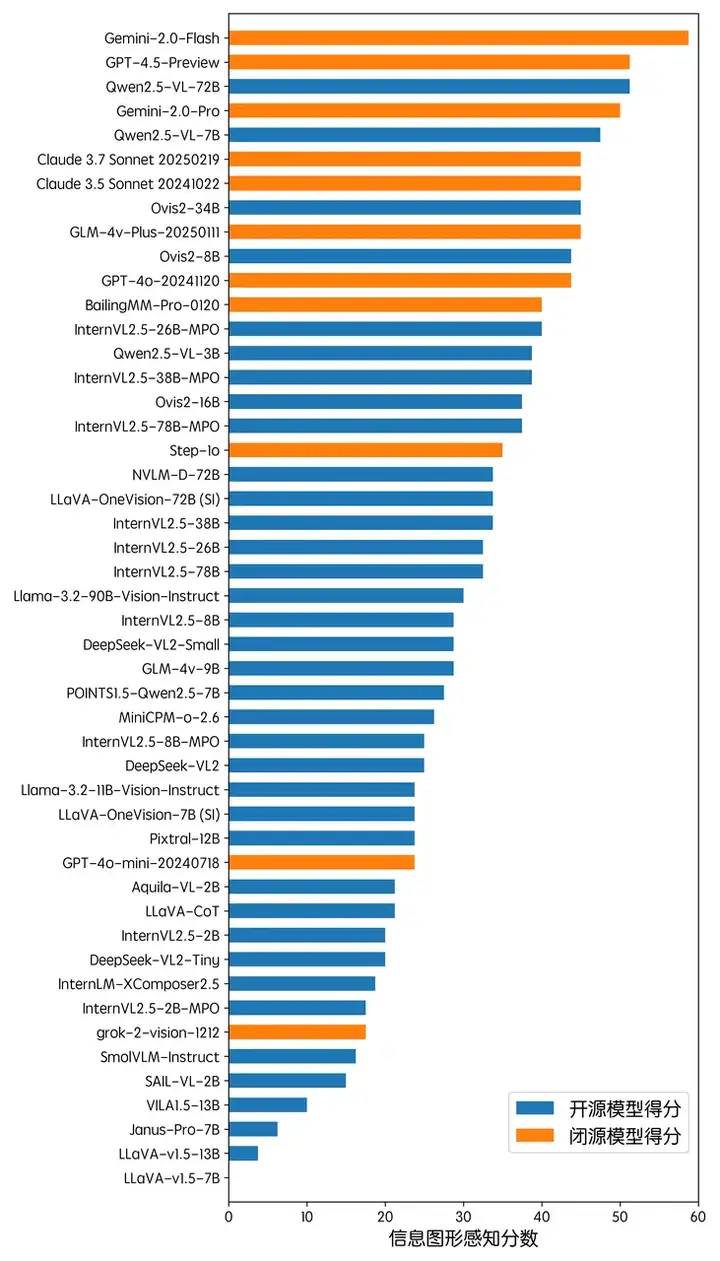
在多模态推理方面,GLM-4v-PLUS 在评测中取得了最佳的成绩。整体上,闭源 API 模型在多模态推理方面的性能处于领先的地位,占据了前 10 名中的 7 席。此外,InternVL2.5-MPO 及 Qwen2.5-VL 也展现了和闭源模型近似的性能。整体上,当前多模态大模型的多模态推理分数都严重偏低,模型最高的分数仍不到 30。
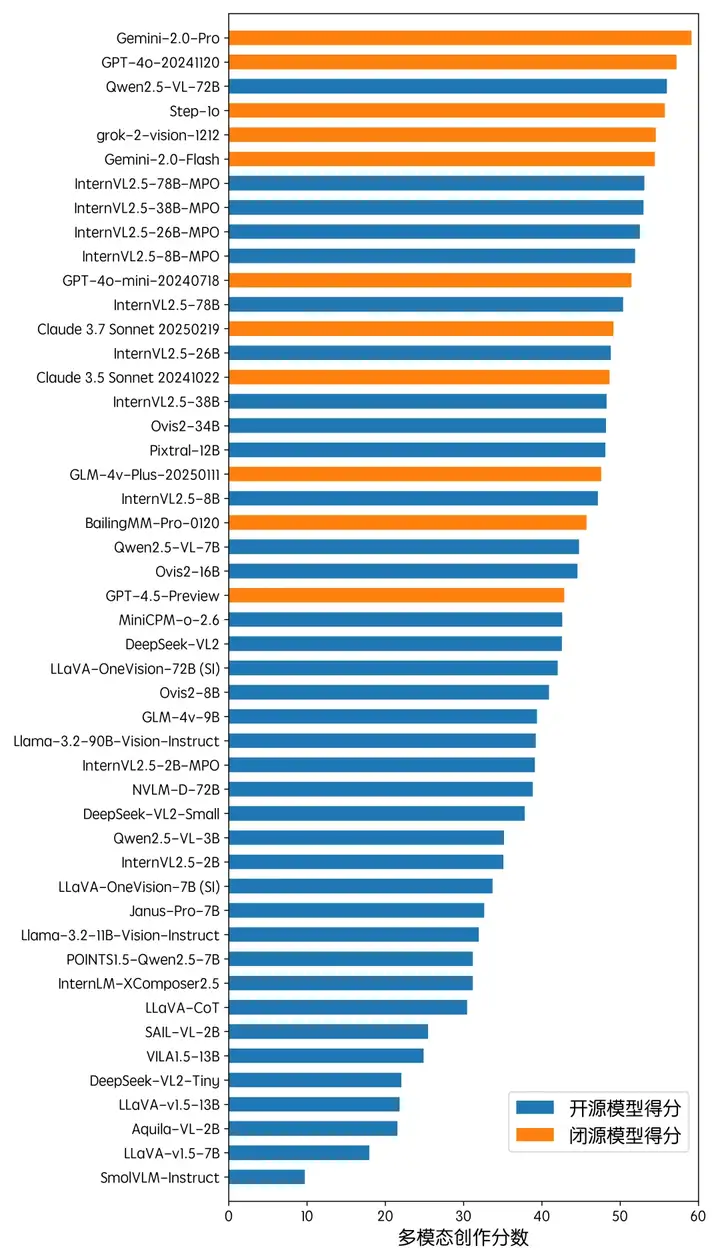
多模态创作
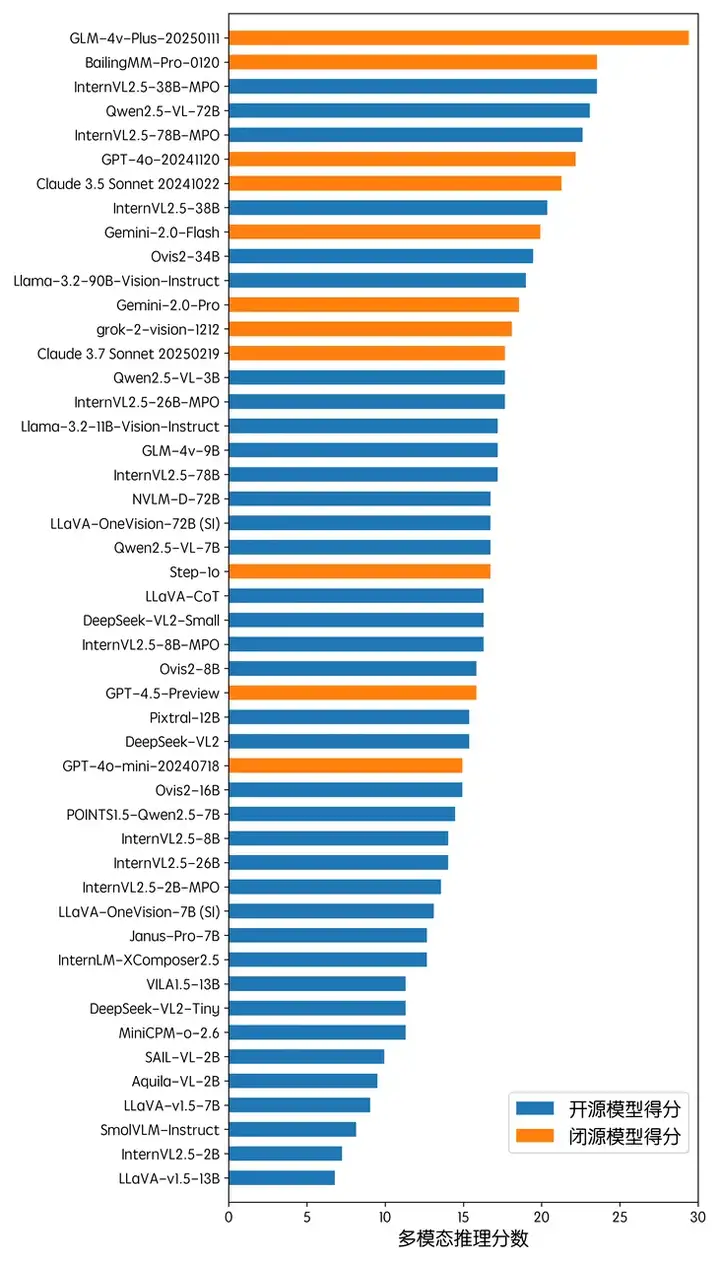
在多模态创作方面,Gemini-2.0-Pro 及 GPT-4o 在评测中取得了最佳的成绩。整体上,闭源 API 模型在多模态创作方面的性能处于领先的地位,占据了前 5 名中的 4 席。此外,Qwen2.5-VL 也展现了和闭源模型近似的性能。
在本部分中,我们展示了一些本次闭源评测中较为具有挑战性的题目。除多模态创作维度外 (不存在客观对错),其他维度的示例 Top-3 模型均未能成功答对。
通用感知
图中的品牌是什么,与哪项运动有关?

['李宁', '篮球']
图中有几个人?

17
下方展示一些视觉质量感知领域具备挑战性的题目(Top-3 模型均未答对)。
Which description most accurately reflects the visual quality of the image?
A. The image is of good clarity, with vivid colors and a harmonious composition.
B. The image is out of focus, with noticeable blur on the plant stalks due to motion.
C. The image is in focus but too dark, particularly in the background areas.
D. The image is clear, but the colors appear too intense and unnatural.

B
How does the color contrast of the markers and the noise in the image affect its aesthetics?
A. The image has a strong color contrast between red and green markers, but the visible noise detracts from the sharpness and clarity of the markers.
B. The color contrast is good for the red and green markers on the white background, and the noise overwhelms the composition, making the image look chaotic.
C. The image has strong color contrast between the red and green markers, and the noise does not affect the overall aesthetics.
D. The color contrast is good between red and green markers with good light reflections, and the noise creates a soft, blurred effect that enhances the aesthetic appeal.

C
下方展示一些空间感知领域具备挑战性的题目(Top-3 模型均未答对)。
Consider the real-world 3D locations and orientations of the objects. Which side of the white SUV is facing the 24 hr parking?
A. front
B. left
C. back
D. right

B
To which object does the given top view correspond?
A. A
B. B
C. C
D. D
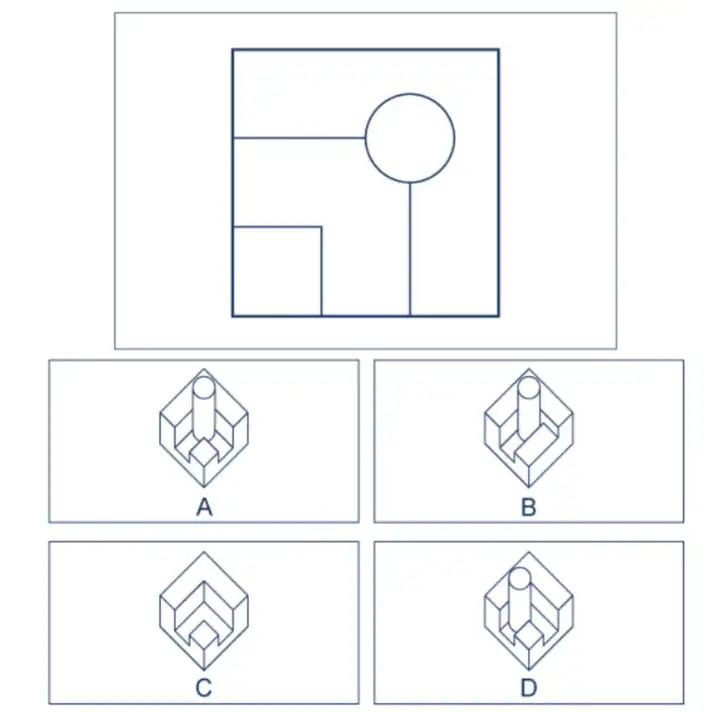
A
信息图形感知
下方展示一些信息图形感知领域具备挑战性的题目(Top-3 模型均未答对):
在图上的这些模型中,谁的Math+Code分数最低?
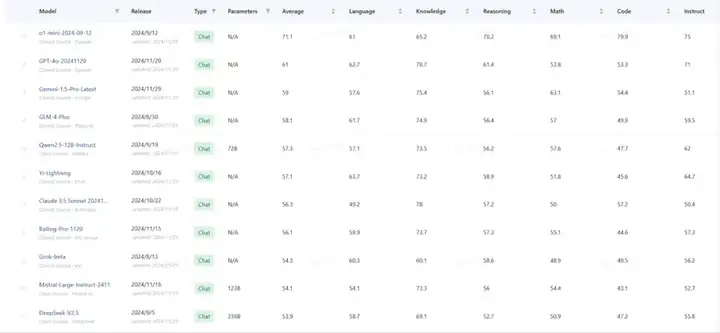
['Grok-beta', 'Yi-Lightning']
In which category is the difference between men and women's trust levels most pronounced?
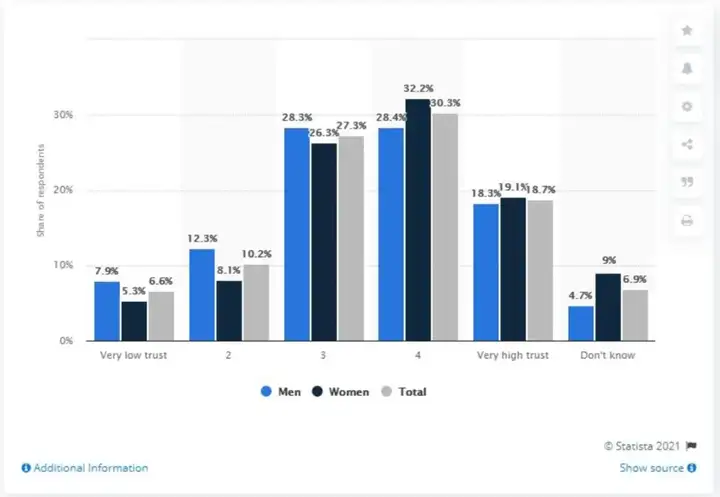
["Don't Know"]
制作傩面具的第五道工序是什么?

['挖瓢']
下方展示一些多模态推理方面具备挑战性的题目。
如图,正方形 ABCD 由四个全等的直角三角形(\triangle ABE, \triangle BCF, \triangle CDG, \triangle DAH)和中间一个小正方形 EFGH 组成,连接 DE。若 AE = 4, BE = 3,则 DE = ________。
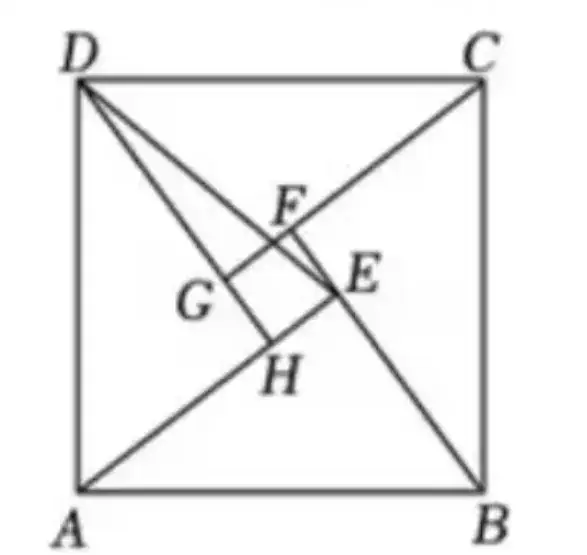
\sqrt{17}
如图所示,一物体受到恒力F1作用,同时受到从0开始增大的F2作用,两力之间的夹角θ不变,则随着F2从0开始增大,物体受到的合力 ________ ?
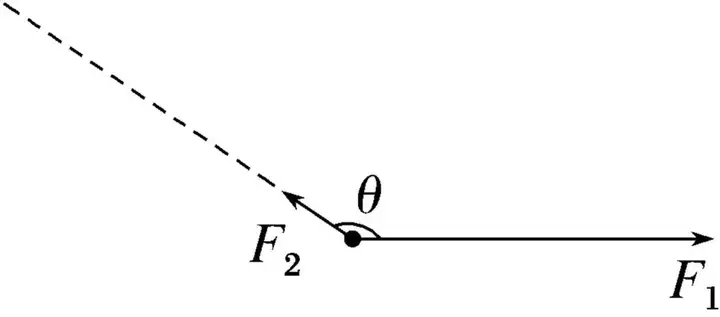
B
下方展示一些多模态创作方面的例题。
Assume you are a warm-hearted elementary school teacher who enjoys writing festive holiday notes filled with gentle encouragement, sweet memories, and thoughtful well-wishes for each recipient. This is the front image of a holiday card. Please follow the requirements below to write a holiday message inspired by the image to your former student, Julia, who you recently learned is studying far from home and may be feeling a bit homesick.

Dear Julia,
多模态模型闭源评测榜单已同步上线至司南官网,欢迎大家访问查看更详细的评测数据!
https://rank.opencompass.org.cn/
同时,司南评测过程中所用到的工具链均在 GitHub 开源,诚挚邀请您在学术研究或产品研发过程中使用~
https://github.com/open-compass/
文章来自微信公众号 “ 司南评测体系 “,作者 司南评测体系



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
