# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
ChatGPT 平地一声雷,打乱了很多人、很多行业的轨迹和节奏。这两年模型发布的数量更是数不胜数,其中文本大模型就占据了 AIGC 赛道的半壁江山。关注我的家人们永远都是抢占 AI 高地的冲锋者。
所以,今天我准备用一个小调查开头——
【当前你对大模型最不满的点是什么?】
(我尽可能整理的全一点儿,但也不可避免地会有遗漏,家人们可以在评论区讨论 ~)
幻觉、知识滞后是一个老生常谈的话题,现在模型基本上都已经具备 RAG 联网能力,或者通过人类反馈强化学习(RLHF)优化生成逻辑来缓解;为了让模型多记住点东西,增大上下文长度也是这两年各大厂商卷的方向,硬是被谷歌卷到了 2M 的天花板。
关于「在特定专业领域的回答深度不够」,现在特别火的 Manus 虽然它想做成通用型 Agent,但我觉得也能解决一部分专业度问题,像秘塔的研究模式、Deep Research、百度的深度搜索,有不少解决方案都在做了。
这里我想提一下第 4 点——
因为这两天对这个感触比较深。
先是看到群里有小伙伴吐槽阿里千问的新推理模型 QwQ-32B 的速度,我也深有体会,等半天没有结果,心急火燎的。所以我干脆本地部署了一个(看上次的推文);
然后是 Manus,虽然视频 demo 里面,处理速度快到飞起。但是现实总是有骨感的。
不少拿到邀请码的朋友和我吐槽“1 小时才做一半”,速度慢到怀疑人生,一个任务动辄需要几十分钟。
虽然知道它是一个级联、多模块调度的复杂系统,但是也能真实的反映当下现在 AI 的响应速度,有时候真的跟不上我们心里的速度了。
尤其在高峰期或复杂任务中,等待时间,简直让人抓狂。
这种心急如焚的等待,经历过的都懂!
正好这两天看到 family 群里小伙伴在讨论——Mercury Coder

是一个扩散语言模型,2 月底才出来,生成速度快到要起飞,直接秒杀现在所有的大模型。
当时并没有多少人关注它,但是怎么逃得过我这个老技术人的嗅觉。
先感受下它的速度,这是我在官网跑的一个 case(无加速版):
官网地址:
https://chat.inceptionlabs.ai
除了 first token 之前有 3、4 秒的等待,中间几乎是一口气儿 print 出来的。
再看个和 Claude、chatgpt 的对比视频——

Mercury 最先出结果,全程只用了 6 秒,Claude 用了 28 秒生成完毕,chatgpt 则用了 36 秒。
生成速度整整快了 5-6 倍。
来自官方的一组更直观的数字——
“在 NVIDIA H100 GPU 实现高达 1000 tokens/秒的输出速度,在此之前只能在定制芯片能够实现这个速度。 ”

而且,不是通过定制芯片、框架适配、加速计算库这些硬件和工程化手段做到的,而且引入了一种全新的语言模型——
扩散语言模型,diffusion LLM,简称成 dLLM。
扩散模型,听过,语言模型,也听过。两个都不陌生。
那扩散 + 语言模型,听过吗?大部分人到这里可能还没意识到事情的严重性。
这个新结合体,极有可能会终结掉现在所有的大模型。

Deepseek 封了 ChatGPT 的成神之路,diffusion LLM,未来可能封了 Transformer 的进化之路。
理解这个之前,你得先知道,现在绝大部分主流 LLM 都是基于 Transformer 架构。
AI 模型的演进史,从 ngram 到 RNN,再到 LSTM,最后到 Transformer,每一代都是以「前一代」的局限性为靶心。
ngram → RNN:解决了上下文长度限制。
和我一样学过宗成庆老师的《自然语言处理》的一定知道,ngram 是统计语言模型的奠基者。
RNN → LSTM:解决了梯度爆炸/消失问题。
我刚工作那会儿还在大学特学卷积神经网络和 LSTM 呢,天天研究卷积的复杂度是咋算的、输入门、遗忘门是怎么控制的数据的。
LSTM → Transformer:解决了并行化问题。
Transformer → ???
diffusion LLM 可能就是这里的???。
你看这个图——
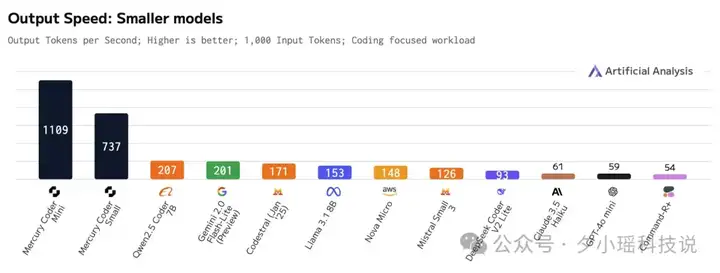
在其他模型的输出速度只有百级别的时候,Mercury 实测速度已突破每秒 1000 Token 大关。
而且,性能表现可以与 GPT-4o-mini 和 Claude 3.5 Haiku 这种各家兼顾效果和速度的模型相提并论。
目前为止,你们见到的大部分大语言模型,在核心建模方法上都大同小异,都是“自回归”式的。简单理解——
从左到右,依次预测下一个词(token)。
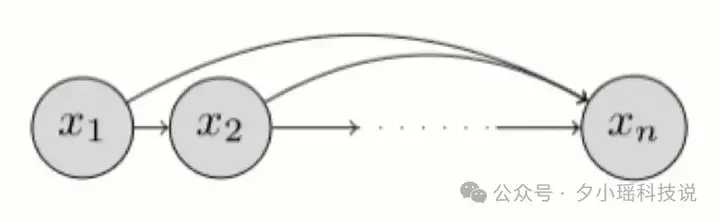
就像写作文,从第一个字开始,根据上下文逐字逐句地写下去,就跟挤牙膏一样。
缺点就是速度慢,因为必须一个字一个字地生成。
更重要的是,生成每个 token 都需经过一次对神经网络的正向计算(推理),带来了巨大的计算负担。
而大多数图像和视频生成 AI 都是用扩散模型,而不是自回归模型。举个恰当的例子:
就像雕塑,先有一块粗糙的石头,逐步去除多余部分,最终呈现出精美的雕像。
优点是并行生成: 理论上可以一次性生成所有 token,速度更快。
比如 DALL-E 2、Stable Diffusion、Sora 都是扩散的代表。
所以你好不好奇,为什么文本生成偏爱自回归,而图像/视频生成偏爱扩散模型?
这背后原因很复杂,涉及到信息和噪声在不同领域的分布,以及我们人类对它们的感知。
扩散模型的核心在于模拟两个互逆的过程完成“由混沌至有序” 的生成策略:
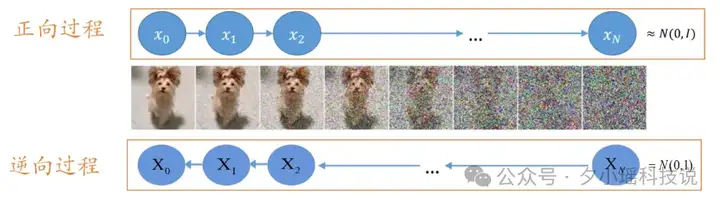
扩散模型不是从左到右,而是一次性生成(这个“一次性”也是通过逐步去噪实现的)。
从纯噪声开始,逐步去除噪声,最终形成一个 token 序列。
去噪的过程,看这个视频很直观——

不是一字一字按顺序生成,像随意蹦出来的字符,最后竟然是连贯的。
这是一篇我前段时间刷到过,来自人大高瓴和蚂蚁集团合作的一篇论文 LLaDA。
论文链接:
https://arxiv.org/abs/2502.09992
再看一个例子——
扩散大语言模型 LLaDA 的核心在于其参数化的模型 𝑝(𝜃)(⋅|𝑥(𝑡))。这个模型接收序列输入,并能同时预测所有被mask的 token (用 M 表示)。 在训练过程中使用交叉熵损失函数,但仅在被掩盖的 token 上计算损失,以优化模型预测掩码 token 的能力, 训练的目标函数如下图所示:
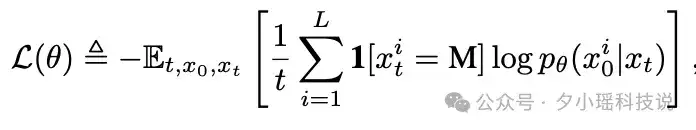
训练完成后,LLaDA 即可用于文本生成。
它通过模拟一个反向扩散过程来实现,这个反向过程由训练好的掩码预测器 𝑝(𝜃) 参数化。 模型的分布被定义为反向过程在时间步 t=0 时所诱导的边缘分布。 这种设计使得 LLaDA 成为一种有原则的生成建模方法。
LLaDA 的架构与目前主流的自回归大语言模型架构相似,仍是基于 Transformer 架构。 然而,LLaDA 并不使用因果掩码。 这是因为 LLaDA 的设计允许模型在进行预测时看到完整的输入序列,而无需像自回归模型那样只能依赖于之前的 token。
回到 Mercury 的性能——
在执行 LLM 推理函数编写任务时,传统自回归模型需迭代 75 次方可完成,而 Mercury Coder 仅需 14 次迭代,速度提升幅度显著:

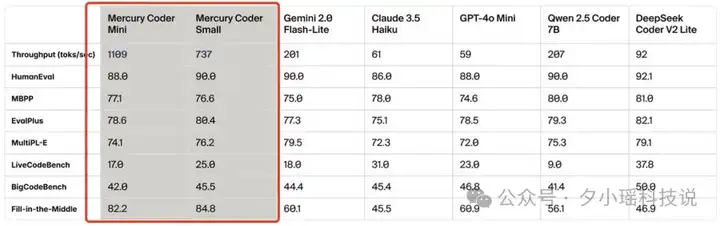
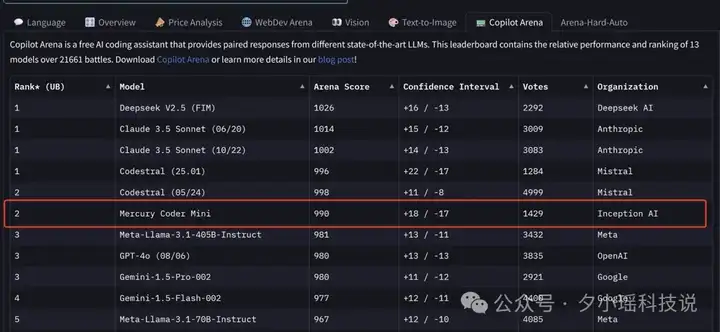
在代码补全能力上,Mercury Coder Mini 在 Copilot Arena 基准测试中取得了卓越成绩,位列第二,不仅超越了 GPT-4o Mini 和 Gemini-1.5-Flash 等模型,甚至能与更大型的 GPT-4o 模型相提并论:
Andrej Karpathy 对这个工作都表示了认可和期待。

吴恩达老师也翻牌了,称这是一次很酷的尝试:

Mercury 的研究团队来自一家名为 Inception Labs 的创业公司, 其联合创始人 Stefano Ermon 不仅是扩散模型技术的核心发明人之一,也是 FlashAttention 原始论文的主要作者之一。
Aditya Grover 和 Volodymyr Kuleshov 毕业于斯坦福大学,并分别执教于加州大学洛杉矶分校和康奈尔大学的计算机科学教授,也共同参与了 Inception Labs 的创立。

Mercury 以及 LLaDA 的出现,标志着基于扩散模型的 dLLM 已经崭露头角。
扩散 LLM 如果要封喉 Transformer,还需要在生成速度(并行去噪)、多样性(摆脱自回归的单调性)和可控性(更精准的输出)上全面胜出。
但眼下,它更像是个有潜力的“后浪”。
但是技术演进往往是融合而非完全替代,未来也有可能是两者的融合,例如先用扩散模型生成草稿,再用自回归模型进行润色。
毕竟在这个信息过载的时代,0.5 秒的加载时长就足以让用户流失。
当「生成速度」成为制约创造力的瓶颈,就要倒逼 AI 走出舒适区。
文章来自于“夕小瑶科技说”,作者“兔子酱、奶茶”。




【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
