# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Manus 爆火出圈,引发 Agent 热潮!
从自行理解任务、拆解步骤到选择工具并执行,这需要 Agent 具备强大的复杂工作流编排和任务处理能力,而工作流也是智能体的核心技术之一。
尽管大语言模型在多个领域已展现出巨大的潜力,但在工作流编排领域,尤其是在复杂工作流的编排上,仍面临显著挑战。
现有大多数模型仅局限于处理节点较少、结构简单的线性工作流,难以满足实际应用中对复杂工作流编排的需求。
为此,清华大学 THUNLP 团队联合人民大学、曼彻斯特大学及武汉大学团队提出了一个全新的、以数据为中心的框架 —— WorkflowLLM,
并设计了首个专为提升工作流编排能力而设计的大规模数据集 WorkflowBench,旨在提升LLM在工作流自动化中的复杂工作流编排能力。
基于 WorkflowBench 数据集,我们对 Llama-3.1-8B 模型进行了微调,获得了 WorkflowLlama,在各项测评集中, 始终表现优于 GPT-4o 等强基线模型。

➤ 论文链接
🔗 https://arxiv.org/pdf/2411.05451
➤ 代码链接
🔗 https://github.com/OpenBMB/WorkflowLLM
➤ 数据集链接
🔗 https://huggingface.co/datasets/openbmb/WorkflowLLM

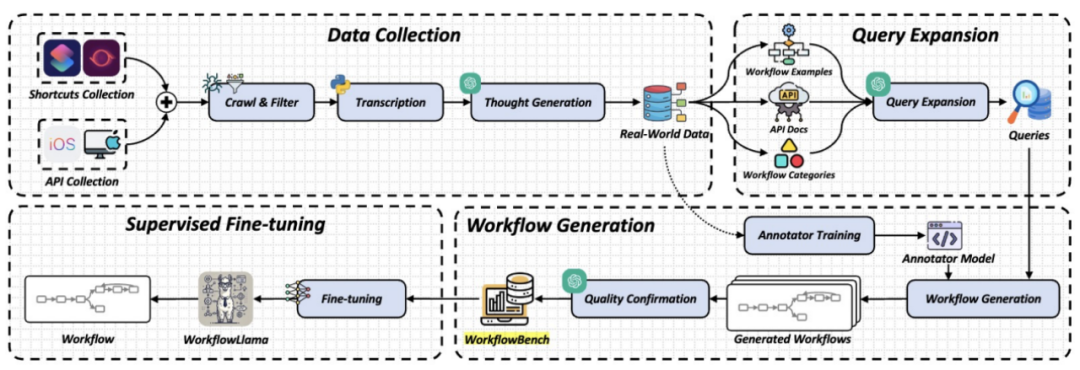
图 1 WorkflowLLM框架概览
如上图所示,WorkflowLLM 主要包含三个阶段:
1. 数据收集:首先爬取高质量的工作流数据,并进行筛选和转换,将快捷指令源代码转录为 Python 风格的代码,便于 LLM 处理。
利用 ChatGPT 生成注释、任务计划和任务查询,丰富数据集并增强 LLM 的学习效果。(详细内容见下文“WorkflowBench 数据构建“)。
2. 查询扩展:使用 ChatGPT 生成更多任务查询,以增加工作流的多样性和复杂性。
采样具有代表性逻辑结构的 API 和工作流示例,引导 ChatGPT 生成类似的工作流。
3. 工作流生成:最后,基于收集到的真实世界数据,训练一个工作流标注模型。利用训练好的标注模型为扩展后的任务查询生成工作流。
对标注模型生成的工作流进行质量确认,确保数据集的完整性。将经过质量确认的合成样本与收集的样本合并,形成最终的 WorkflowBench 数据集。

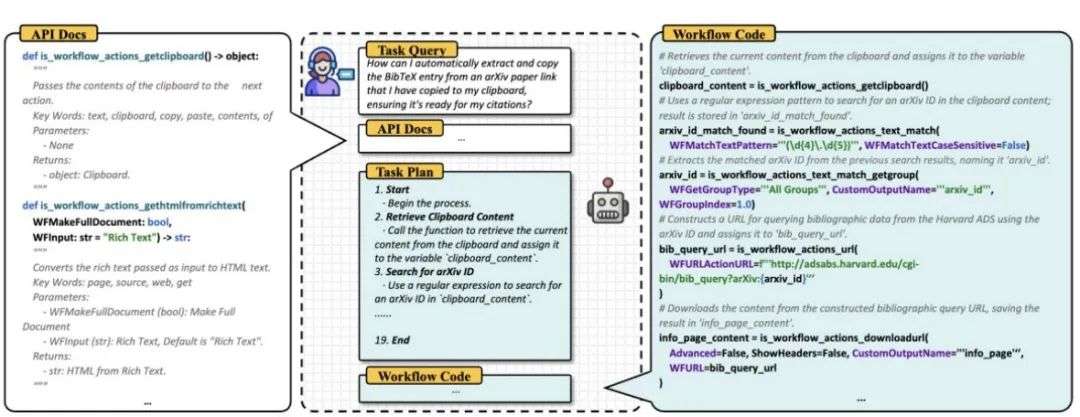
图 2 WorkflowBench数据说明,包括任务查询、API文档、任务计划和带注释的工作流代码
WorkflowBench 数据集的构建过程分为三个阶段。
首先,我们从真实世界的工作流数据(例如 Apple Shortcuts 和 RoutineHub)中收集样本,并将其转录为 Python 代码。
随后,利用 GPT-4o-mini 模型为其生成层次化思维评论。其次,通过 GPT-4o-mini 生成任务查询,以此丰富工作流的多样性和复杂性。
最后,借助标注模型生成扩展查询的工作流,并通过严格的质量确认环节,确保数据集的高质量。
WorkflowBench 数据集包含 106,763 个样本,涵盖 83 个应用程序中的 1,503 个 API。
与现有工作相比,WorkflowBench 不仅包含更多节点的工作流实例,还具备更为复杂的逻辑结构,尤其注重支持多步骤、分支、循环等高级功能的工作流生成。
作为首个专注于提升工作流编排能力的数据集,WorkflowBench 为大语言模型(LLM)提供了丰富且复杂多样的训练数据,
使其能够更好地应对现实世界中对自动化工作的需求。
如图所示,该数据集覆盖了包括 iOS 内置应用、ChatGPT 在内的 83 个应用,涉及 Utility、Games、Music 等 28 个领域。相关数据说明及统计结果如下:
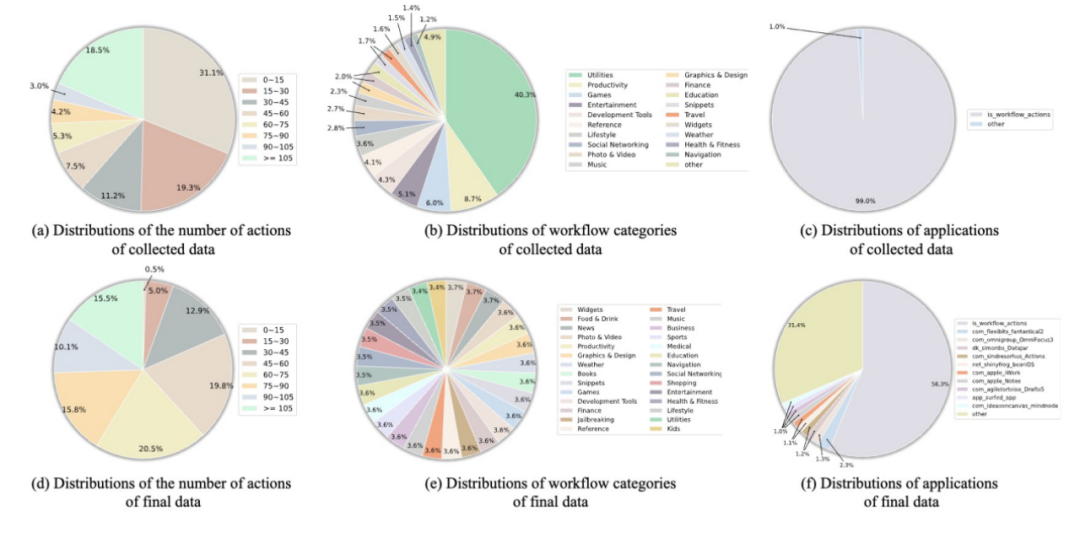
图 3 工作流类别、包含的应用和操作数量的分布比较。上半部分展示了收集到的原始数据,而下半部分展示了扩展后的数据集分布。
基于 WorkflowBench 数据集,我们对 Llama-3.1-8B 模型进行了微调,获得了 WorkflowLlama。
实验结果表明,WorkflowLlama 能够有效地编排复杂工作流,并在未见过的API和指令上展现出卓越的泛化能力。
此外,WorkflowBench 还在超出分布的任务规划数据集 T-Eval 上表现出了强大的 0-shot 泛化能力,取得了77.5%的F1计划分数。
我们使用 CodeBLEU 指标评估生成工作流的语法和语义质量,包括 BLEU、加权 N-gram、AST 匹配和数据流匹配等四个方面。
并用 ChatGPT 作为自动评估器,评估生成工作流是否能够完成用户查询的任务。
实验结果表明,在 CodeBLEU 和 Pass Rate 指标上,WorkflowLlama 都取得了 SOTA 的成绩,远超其他模型,包括 GPT-4o 和 Llama-3.1-70B 等大参数的模型。
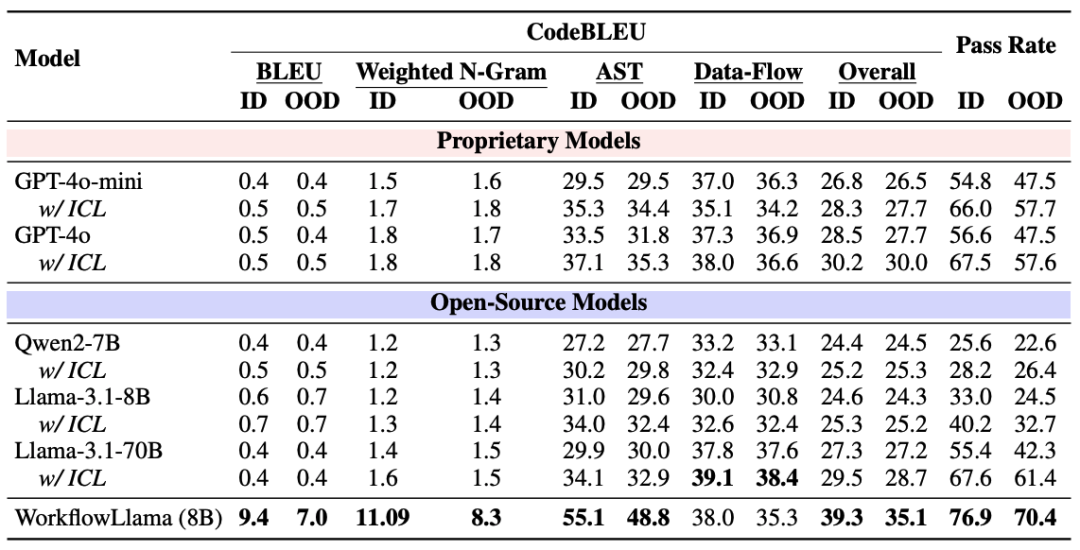
图 4 在未见指令 (ID) 和未见 API (OOD) 场景下,各种模型的性能比较 (%)
此外,我们发现随着工作流复杂性的提升,使用 WorkflowBench 训练得到的 WorkflowLlama 始终表现优于 GPT-4o 等强基线模型。
为了评估模型生成不同复杂度工作流的能力,我们根据动作总数、分支和循环数量以及参考代码的嵌套深度对 CodeBLEU 的性能进行了细分。
如图 5 所示,随着动作数量或逻辑复杂性的增加,所有模型的性能都会下降,然而,在所有复杂度水平上,WorkflowLlama 的表现都显著优于其他所有模型。
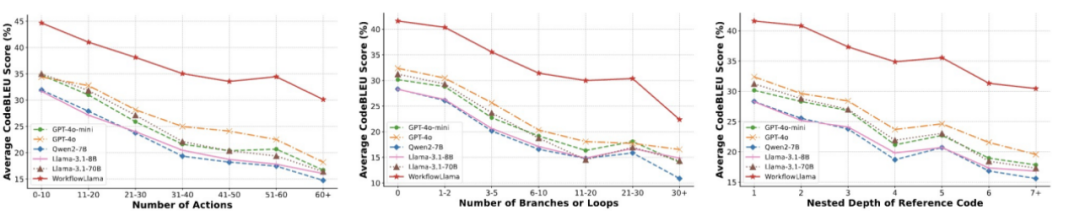
图 5 基于动作数量、分支和循环数量以及参考代码嵌套深度的性能比较
实验结果表明,使用 WorkflowBench 训练可以提升 OOD 数据集 T-Eval 的性能。
为了进一步评估 WorkflowLlama 的泛化能力,我们在 OOD 基准测试 T-Eval 上进行了实验,该测试广泛用于评估 LLM 利用 API 进行多步决策的能力。
如图 6 所示。尽管 WorkflowLlama 在不同的领域和任务上使用不同的 API 进行训练,但在 T-Eval 基准测试中仍然展现出强大的 OOD 泛化性能。
且 WorkflowLlama 显著优于未经微调的 Llama3.1-8B 以及更大的开源模型如 Llama-2-70B 和 Qwen-72B。
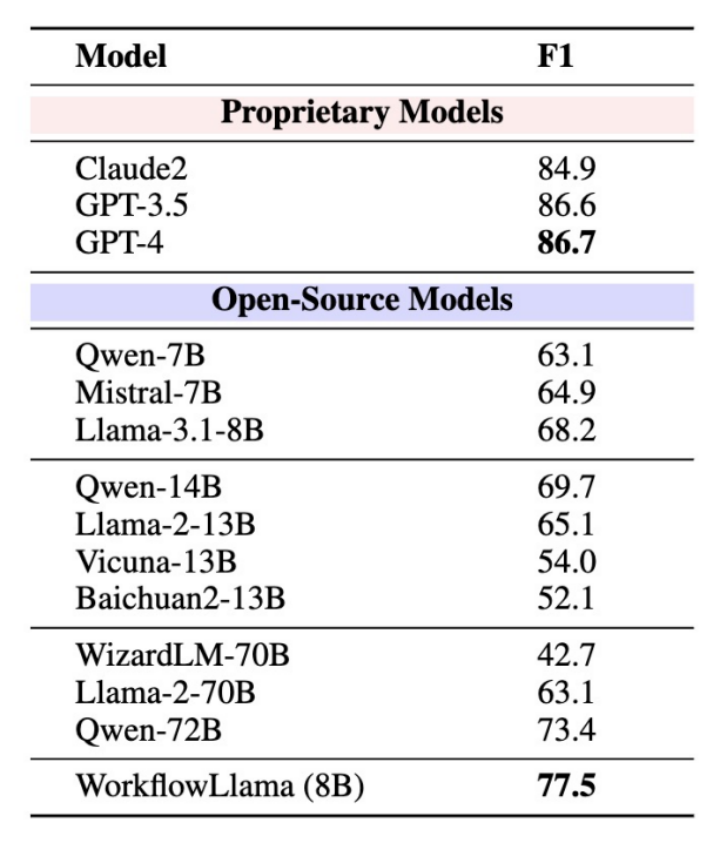
图 6 在 T-Eval 的 PLAN 任务上 F1 分数的比较。(粗体表示同一类别模型中的最佳分数)
文章来自于微信公众号 “ OpenBMB开源社区”,作者 : OpenBMB开源社区



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
