# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。
刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。
对于 AI 的发展,我坚定押注 LLM 的未来。有些做视觉的同学觉得猫狗没有语言,它们只通过视觉去学习也能发展出现在 LLM 不具备的很多智能,
或者想要从视觉里面发现一套新的语言系统。但是,我觉得有很多闪耀的人类智慧是从视觉里得不到的,这些智慧是对世界逻辑结构的抽象发现。
以简单的数字为例,从视觉世界可以得到 123,1 个椅子、6 瓶水,都能抽象出来;但你比较难抽象出来,更抽象不出来虚数。
大家是通过抽象符号定义方程,方程的定义域里有 ,对这个方程的解带出了虚数,接下来又打开新的逻辑世界,复变等等。
这些都是从纯符号逻辑的角度,对世界本身的逻辑结构进行发现,而不是通过视觉。
虚数在可观测世界中不可能观察得到,但这是属于这个世界的逻辑结构的一部分,发现了之后反过来对可观测世界产生巨大影响。
视觉/多模态作用于三维以内,抽象符号系统负责四维时空以上高维空间顶尖智能的突破,各有分工,各有追求。
视觉多模态的应用很 fancy,但我觉得对突破人类尖端智能的帮助相对弱。真正扩展人类认知边界、扩展人类尖端智能的是抽象符号逻辑系统。
一个原因是机器视觉 perception、对宇宙的 encoding 本身是被人类的低维 perception 所 bound 的,人类只能感知四维的信息。
尖端智能的突破还是要通过符号逻辑系统,对世界逻辑结构进行新发现。
在 AGI 出现之前,人类的感知(包括辅助人类进行感知的高精尖设备产生的数据量)未必能够取得突破,
反而有可能是基于抽象符号系统的 AGI 先一定程度实现了,然后反过来帮助人类提升 perception 边界。
来到 Seed 之后,我发现这个优秀的团队能非常好地支持我的 belief,这里充分满足和尊重我个人的兴趣点。
经过大概两个月自由探索的 landing 期,在 8 月我们确定要做一个聪明的推理模型。
9 月 OpenAI O1 出来前后,我们试遍了各种方法,充分探索后我们 bet Outcome-based RL 是关键技术点。这里有两个增强技术信念的点:
既然模型能 sample 出正确答案,那做 RL reverse kl 就应该让模型学会,那把 RL 做好就行了。接下来的问题是 RL 怎么做。
基于这个,当时的判断和 bet 就是 O1 是纯基于 outcome supervision train 出来的。
当时公司内外有很多人都在做O1相关的工作。Based on 这些 bet,我们团队基本是第一个跑 work O1 RL 的。
去年十月份我在公司内部小模型上,只用很少的 GPU、学术界开源数据集,能把数学能力提升几十分,超过内部最大、最强的模型。
同时涌现复杂的类 O1 的推理 pattern
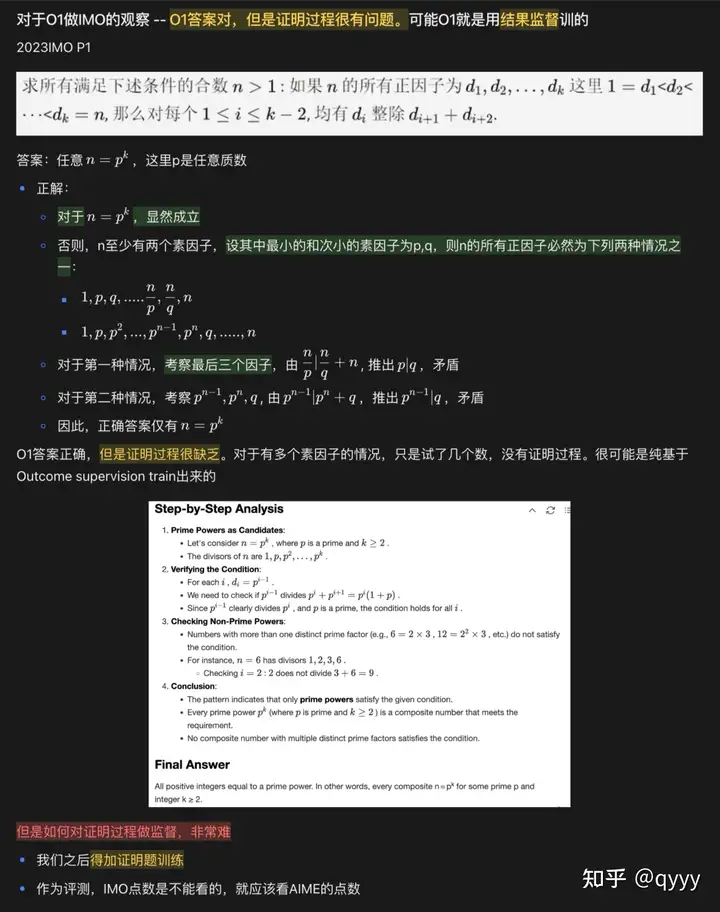
10月初写的 O1 做 IMO 题的具体分析
我们在去年十月也做出了现在流行的 Aha-moment 现象。
十月中旬,我们发现模型如果列了个复杂的方程,会自言自语:“This is very difficult and seems to lead a very complicated equation. Let's try another approach. ”。
它开始自我质疑不断思考,就像人类做题推翻错误草稿时的反思。当时我和我的 mentor 王明轩盯着屏幕反复看各种case确认 —— 这就是我们追求的能力的雏形。
当时我们在文档里兴奋地敲下,“非常有意思。更加坚定地 bet Outcome-based RL 一定能激发出非常厉害的行为!!!”
前后将近一两个月的时间,我几乎睡在公司,经常凌晨两点兴奋地惊醒,满脑子都是新的 idea,爬起来写两小时代码,五点再睡。
最投入的时候,每天和 mentor 持续讨论到晚上 11 点,谁也不想离开公司,当时感觉每一刻都在不断的发现新现象、不断突破性能上限。

当时关于Aha-moment的文档记录
那时每天都在认知突破与兴奋中度过,但是有点遗憾的是,到1月就被Deepseek打爆了hhh。
后来我们的测试结果显示,如果选择蒸馏可以更快提升推理效果和通用应用水平,但当时为了真正弄清楚机理,我们还是选择慢慢来、做长期的事情,
扎实提升数据质量。但我们技术上的认知、bet 和硬实力未必落后。
去年在 R1 发布之前,我们没引入任何蒸馏数据的模型在 AIME 数据集上做到了 70分,但通用应用的水平达不到。
最近我们也开源了一项工作 DAPO (https://mp.weixin.qq.com/s/_ w_HtjNQiG-yP5LEN85o0Q),
整理了之前探索出来的一些 RL技术在 Qwen-32B pretrain model 上跑了实验,和 DeepSeek 使用的 GRPO 公平对比
(相同base model纯做RL,不引入蒸馏等其他变量),结果显示我们在性能和效率上都有优势。
现在回看那段日子,记忆里完全没有疲惫,当时兴奋睡不着觉睡一会就起来写代码的感受还历历在目。
不仅是我个人,在 Seed 团队的这段时间,最打动我的一个点是团队的技术信仰。
身边很多同学都对技术抱有纯粹的追求,从算法优化到工程实现,每个人都在追求技术本质的突破。和这里的同学一起交流进步让我常想起胡适的一句话,
“怕什么真理无穷,进一寸有进一寸的欢喜”,这种技术信仰让我们的 AGI 梦想清晰、坚定。
我个人 bet LLM RL 技术 towards AGI,接下来的目标是研究清楚 RL 的 scaling。
最后借这个机会也 sell 一下,如果你也是和我一样对 LLM 有追求和理想的同学,欢迎加入Seed。首先字节平台大,场景和资源丰富,探索空间足够,上限够高。
而且我觉得和外界印象不一样,新人在这里也可以得到很好的nurture,明轩、永辉经常找我交流,我也可以说是在字节读了博获得的成长。
来字节实习前,我也拿到了很多其他大厂和一线大模型团队的offer,包括做出了 R1 的 DeepSeek,但如果再来一次,我还是会毫不犹豫地选 ByteDance。
因为这里给了同学们放手探索的机会,让我可以独当一面做出有价值的工作。
Btw,我觉得DeepSeek战斗力真的很强,但我会努力让ByteDance胜算更大一点期待在这里与更多优秀的小伙伴同行,一起把 AGI 梦想真正落地实现。
文章来自于微信公众号“大模型智能”,作者 :qyyy@知乎




