# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
日前,毅伯智算基于3月13日推出的搭载满血版DeepSeek-R1-671B的8卡推理一体机TORA3000,
在原有性能基础上再次进行优化,实现在典型企业应用场景下的性能实测吞吐量达到7442TPS,最高并发数支持到900,可以同时支持2000+员工流畅使用。

近期以来,基于DeepSeek模型的一体机成为行业焦点,产品层出不穷,各方对其性能指标各执一词,
但往往脱离测试方法(参数设置)、脱离成本、脱离对标机型谈性能,令市场眼花缭乱。
针对上述问题,毅伯智算通过自研的DeepSeek 8卡一体机的性能表现,尽量为企业理性选择一体机提供一个全方位的评估标准。
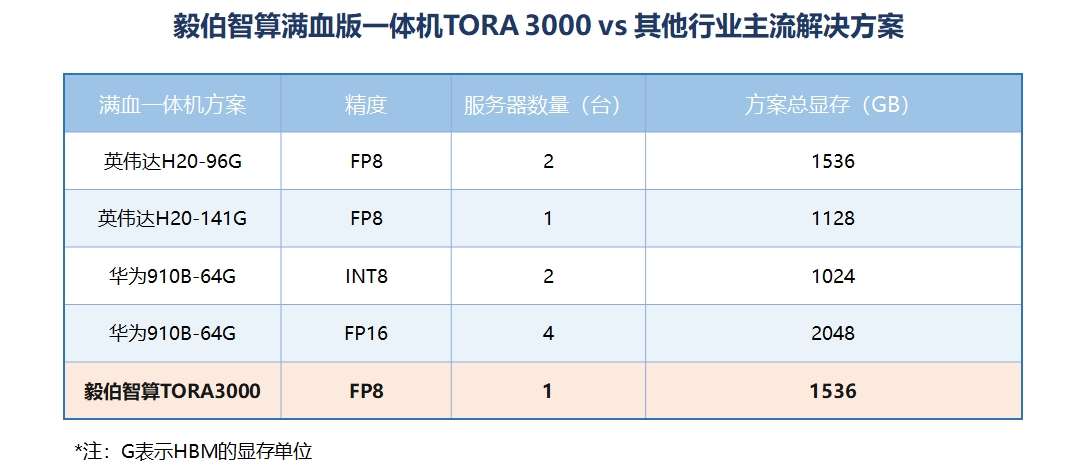
据了解,TORA3000基于AMD新一代Instinct OAM GPU,单颗GPU的HBM3e显存容量高达192GB,总计达1.5TB,
搭载毅伯智算自研的针对DeepSeek MOE(混合专家模型)的软硬件一体解决方案,采用DeepSeek原生精度FP8(杜绝量化后精度下降导致性能虚标),
实现了硬件、组网、功耗的综合成本最优,并可以开箱即用。
本次优化方案使用的推理框架为毅伯智算自研的TORA-vLLM2.0,结合了vLLM与SGLang两种框架各自的优势,
在底层GPU硬件上大幅优化了卡间通信以及全自动化的并行策略等,最终使其综合性能为英伟达H20 (HBM 141G型号)性能的1.8倍,
达到业界一机8卡部署满血版R1模型的同类产品的绝对领先。


提供最具性价比的一体机解决方案
从3月13日全新推出搭载满血版DeepSeek-R1-671B的8卡推理一体机TORA3000,到此次显著优化性能,毅伯智算凭借其软硬件一体化的综合优势,
提供最具性价比的一体机解决方案。
首先是降低客户硬件成本,1机8卡即能实现上述性能,相比16卡机型方案,成本大幅降低;
其次是对FP8精度的支持,原生支持 DeepSeek-R1-671B 所采用的FP8 精度,兼容FP64/32/16 及INT8,在保证推理精度的同时有效降低部署成本;
还有对算子、算法、推理框架协同优化,通过全自研的算子库、编译技术、推理框架等技术手段,实现更快计算效率、长文本和高并发请求支持、更高推理性能;
最后,通过动态专家路由技术,实现MoE模型专家切换效率的提升。
作为国内少数实现全栈自研的软硬协同算力解决方案提供商,毅伯智算团队凝聚了超百人的AI工程师,其中核心成员在人工智能与超算领域拥有超10年的研发经验。
过去三年,团队始终致力于全栈式AI训推平台的研发,并于2024年依托新组建的毅伯智算主体,推出了全栈式AI训推平台。
2025年3月,毅伯智算进一步推出搭载DeepSeek模型的自研8卡推理一体机TORA3000。
文章来自于36氪账号“36氪的朋友们”,作者 :36氪的朋友们



