# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天看到一个非常有意思的事情。

这是第一次,全世界最大的网络基础设施公司之一,Cloudflare,开始用魔法打败魔法,用AI来对抗AI爬虫。
这事情的有意思的程度,足以载入AI发展史册。
这是一次,AI领域的全面战争。
你可能现在还有很多疑惑,Cloudflare是什么,AI爬虫是什么,AI迷宫又是什么,这个事到底有意思在哪。
这一切的开始,我想先跟你讲一个故事。
一个在今年1月份,发生在一个仅有7人的乌克兰公司的故事。
这个公司叫做Triplegangers,做的业务特别简单,就是卖人的3D数字模型。
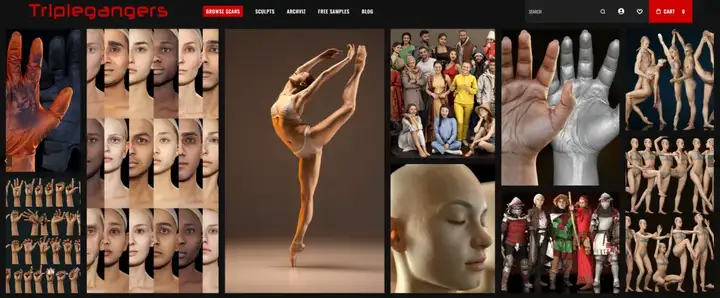
Triplegangers专注于销售“人体的数字孪生”模型素材,这些高清3D模型照片来自真实的人类扫描,价值巨大。
创始人Tomchuk一直很满意,公司虽然不大,但是是他最喜欢的事情。
这个网站上,一共共有65000个产品页面,每个产品的页面至少放着三张高清照片。 每一张图片,都细致地标注了年龄、肤色、纹身甚至伤疤。
但是,就在一个普通的周六早上, 平静被一场风暴骤然打破。
Tomchuk收到了一条紧急通知:公司网站崩溃了,因为受到了大量的DDoS攻击。
他懵逼了,因为平时也没啥仇人,更没啥竞品,守着自己那一亩三分地,谁会好好的来攻击自己呢?
他惊慌失措地开始调查原因,很快发现,居然是OpenAI的爬虫机器人,GPTBot在攻击他的网站。
GPTBot疯狂地爬取每一个页面, 数十万张照片、数十万个描述, 在短短几小时内被无情下载。
这些爬虫机器人使用了整整600个IP地址,数以万计的服务器请求,这种网站哪见过这种架势,网站的服务器瞬间瘫痪,业务陷入停滞。
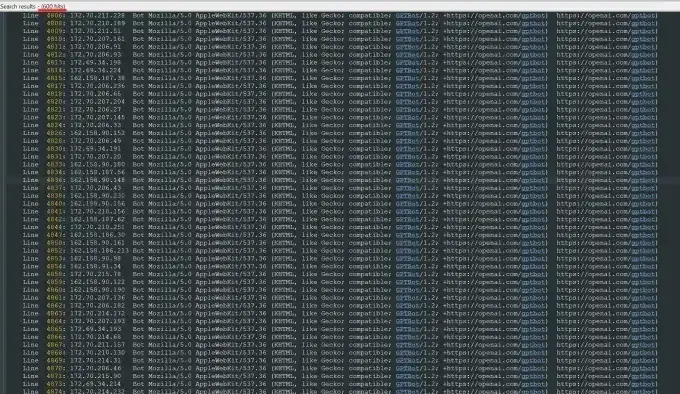
Tomchuk人都傻了,不仅自己的数据全丢了,被OpenAI爬的干干净净,更糟的是,由于服务器压力暴涨, 公司还将面临一笔巨额的AWS账单。
他们这个七人的团队花了十年心血,才构建了这个庞大的数据库,客户遍及游戏开发、动画制作等多个行业。
而现在,啥也没了。
更令人无奈的是,他们原本就明确禁止爬虫机器人未经许可抓取网站数据。
但是因为没那么懂AI,也不太知道那些AI大模型公司的玩法,所以没有严格配置robot.txt 文件,没有配专门告知OpenAI的机器人GPTBot不要访问该网站的标签,这基本等同于默认允许了OpenAI的抓取行为。
关键是吧,配了GPTBot的标签也不够,因为OpenAI还有ChatGPT-User和OAI-SearchBot,这两个标签也要配。你甚至不知道他们还有啥。
"我们原以为禁止条款就足够了,没想到还必须专门设定拒绝机器人的规则。"
几天后,Tomchuk终于设置好了Triplegangers的robot.txt文件,并启用了Cloudflare服务以屏蔽更多爬虫。
Cloudflare大家可能没听过,但是大多数人应该都见过。
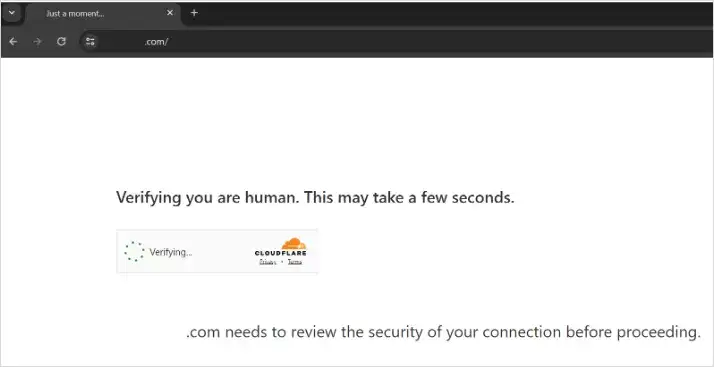
就这个玩意,让你在进入某些网页之前,验证一下你是否是人类。
不过这玩意也不是免费的,挺烧钱的,都是成本。但是为了再防一波OpenAI那种流氓行为,他们只能启用。
这些服务的钱,都还好说,但是让Tomchuk最痛苦的事,他根本不知道,OpenAI到底拿走了多少素材。
而且,Tomchuk说:
"我们甚至联系不上OpenAI,也无法要求他们删除已抓取的数据。"
甚至最离谱的是,如果不是OpenAI这么贪,一次性请求太多,直接把Triplegangers爬崩溃了,而是慢慢爬,一点一点的。
Tomchuk可能这辈子都发现不了自己的数据已经全部丢的干干净净了。
OpenAI的爬虫逻辑很简单,如果你家门口没有保安站岗,那就说明你默认你家里的东西我就都可以拿走,都是我的。因为你没说不准我拿,也没设保安,所以我就可以进门全部洗劫一空。
这是一场战争。
一场没有硝烟的战争。
一场关乎于保护自己财产神圣不可侵犯的战争。
一场关乎于我们,跟这些AI公司的AI爬虫的战争。
Trilegangers的遭遇并不是孤例。
在许多许多公司和内容创作者的眼中,AI爬虫就是这个时代的数字蝗虫,所过之处令网站不堪重负,数据还被洗劫一空。
去年夏天,还有一个著名的的例子,来自于非常老牌的维修教程网站,iFixit。
iFixit发现,他们的网站也成了AI爬虫的盘中餐。
但这一次,吃相难看的不是OpenAI,而是另一个AI王者,Anthropic公司的爬虫ClaudeBot。
当时iFixit的CEO怒不可遏地在社交媒体上爆料:
ClaudeBot在短短24小时内疯狂访问了iFixit近一百万次。直接差点把他们的网站挤爆,触发了所有报警系统,迫使iFixit的运维团队连夜加班处理。
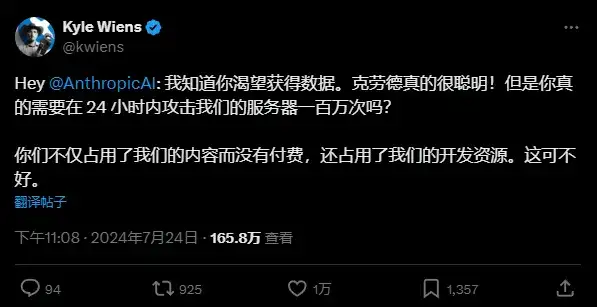
更离谱的是,iFixit早就明文禁止未经许可抓取他们的内容用于AI训练,这一条清清楚楚地写进了网站的使用条款,甚至特别注明“不得将本网站内容用于机器学习或AI模型的训练”。
但是Anthropic的爬虫明显不care这些声明,依旧我行我素地狂扒数据。
更让无语的是,当这事爆了之后,有媒体就去问Anthropic,对方给出的回应几乎和OpenAI如出一辙:
他们表示ClaudeBot爬虫是遵守robots.txt的,如果网站不想被抓,就应该在 robots 文件里屏蔽Claude。
言下之意,就是iFixit你自己明明没说啊,没在robots.txt彻底封禁啊,我们当然就有权一直爬下去啊。
无奈之下,iFixit只好赶紧修改了robots.txt,添加了针对ClaudeBot的延迟和阻止规则。
可这件事留给业界的震动却挥之不去,坦率的讲,连iFixit这样熟悉网络技术的知名网站,一开始都没料到 AI 爬虫会如此不讲武德,明知道别人不情愿却还要硬闯。
如果连老牌互联网从业者都防不胜防,那其他那些没技术团队守卫的小网站、小作者,又咋招架这些窃贼?
甚至更不要脸的是那个AI搜索鼻祖,Perplexity。
知名科技媒体《连线》(Wired)发现,Perplexity的爬虫不仅没有遵守一些网站的robots.txt 禁令,甚至试图悄悄抓取那些明确声明不开放给机器的角落。
换句话说,就是Perplexity公然无视robots协议,偷偷攫取了本不该拿的内容。
可能你看到这里,会疑惑robots协议是个啥。
我们把时间倒回1994年,那个时候网络上也正经历着爬虫之乱。
彼时搜索引擎刚兴起,一些自动爬虫程序在网上横冲直撞,给服务器造成了不小的负担。
于是,一位名叫Martijn Koster的荷兰工程师,提出了一个非常巧妙的主意:
网站管理员可以在站点根目录放一个名为“robots.txt”的文本文件,提前告诉网络机器人,哪里可以爬、哪里不许碰。
这个提议很快得到了行业的广泛认可,成为互联网早期一种非常纯粹的“君子协定”。
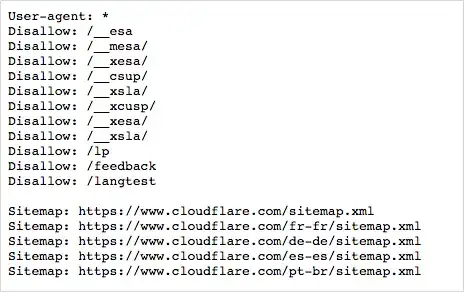
根据robots协议,如果网站在robots.txt里标明了禁止抓取某些内容,那么守规矩的爬虫就应该乖乖止步,不去触碰那些被列入黑名单的路径。
这套机制本质上完全依赖自觉,它没有法律强制力,靠的是爬虫开发者愿意遵守规则的良知和诚意。
但令人欣慰的是,在相当长的岁月里,这种诚意基本上保持了下来。
Google、Yahoo等搜索引擎尊重robots.tx 的边界,微软的Bing也是如此,甚至后来各式各样善意的网络爬虫,都把不伤害网站、遵循站长意愿当作职业道德的一部分。
正因为有robots.txt的存在,网站管理员才愿意敞开大门让搜索引擎索引内容,他们相信敏感或不想公开的角落可以被礼貌地避开。
这份信任,构筑了网络内容自由流通和公平利用的基础。
但是现在,这份来之不易的信任正被无情地侵蚀。
当AI爬虫为了填饱模型的数据需求四处出击时,又有多少还真正尊重 robots.txt的边界?
OpenAI、Anthropic固然口口声声我们遵守robots协议,但事实是,如果你没明确写禁令,他们就默认可以来拿,丝毫不考虑你是否情愿。
只要你没用足够坚固的墙把我挡住,那就是你的错,我闯进来就理所应当。
这种倒打一耙的逻辑让人愤慨之余,也透出一丝悲哀。
所以,在这种背景下,Cloudflare挺身而出,作为大多数网站前的守护者,他们决定,用魔法打败魔法,用AI,对抗AI。
他们为这些AI爬虫,造了一整座AI迷宫。
因为过往的防御逻辑很简单,就是用验证的方式,直接把这些AI爬虫拦在门外,这样会有个问题,反而会惊动敌人,让他们换个马甲卷土重来。
比如OpenAI就有N个AI爬虫。
所以他们这次的更新,用了一个更阴柔的做法:
放对手进来,但是领着它走进一个精心编织的虚假网页迷宫。
在这个迷宫里,所有的页面、链接和内容都是 AI 自动生成的,看上去像模像样,却全都是无意义的空城计。
那些AI爬虫一旦被引诱进去,就会在假内容中团团转,白白浪费计算资源和带宽。
而这些迷宫入口对正常用户是隐形的,真人访客根本不会点击到那些陷阱链接。而 AI 爬虫则乐此不疲地一路追踪下去,越陷越深,直到在虚假的信息泥潭中迷失方向。
大卫终于也有了一块对付歌利亚的利器。
Cloudflare他们在blog中写道:

这是一场战争,一边是如狼似虎、到处搜刮数据的AI爬虫大军,另一边则是苦苦守卫自己数字领土的网站站长和内容创作者们。
我不否认大模型需要海量数据训练,创新常常伴随着对旧有规则的冲撞。
互联网历史上类似的矛盾并非首次:音乐产业曾与数字盗版激烈交锋,新闻出版商也为搜索引擎收录内容而抗议。
也许在很多AI公司看来,网络上的公开内容皆是取之无害、用之无罪的公共资源,抓了又何妨?
但是有没有想过内容生产者的感受呢?知识和创意的源头若得不到尊重和回报,最终枯竭的将是创新本身。没有人愿意辛苦耕耘却被机器毫无顾忌地偷走成果。
至少在现有的伦理和经济体系下,这种行为会磨灭创作者的热情。
到最后,网络上留下的,全部是AI生产的AI垃圾,淹没了整个互联网。
战争已经打响,而AI领域的这场较量正是从爬虫开始的。
我只希望,当硝烟散去,我们还能拥有一个我们所热爱的、开放而可信的互联网。
抛开那些宏大的技术叙事,对于我们每一个普通网民而言。
这才是我们最值得去捍卫的东西。
不是吗。
文章来自于“数字生命卡兹克”,作者“卡兹克”。




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
