# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在Stable Diffusion当中,只需加入一个LoRA就能根据图像创建3D模型了?
港科大(广州)与趣丸科技合作推出了全新三维生成大模型——Kiss3DGen,创新性地将3D生成与成熟的图像生成模型进行了对齐。
并且与主流2D扩散模型技术(如ControlNet、Flux-Redux)兼容协同,无需额外训练即可即插即用。

△由Kiss3DGen生成的场景
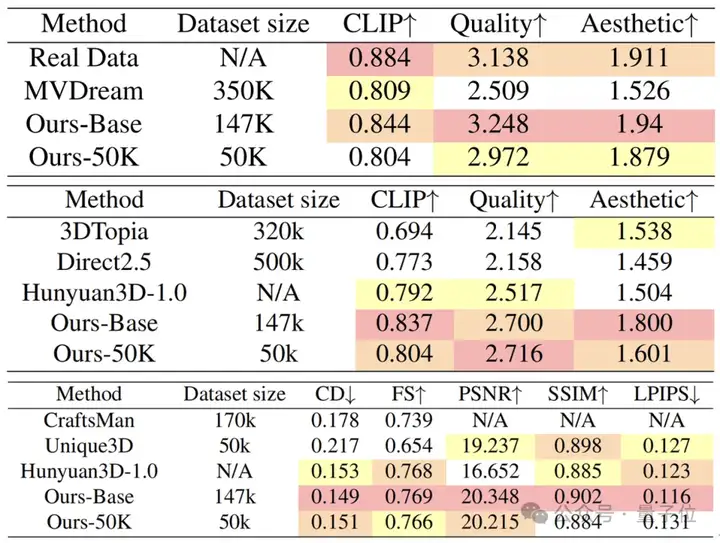
即使在有限的训练数据条件下,Kiss3DGen仍能生成高质量的3D资产,减少对大规模数据的依赖,同时在灵活性和性能方面表现出色。
目前,Kiss3DGen单独使用效果已优于现有开源方法,而且在与现有方法相结合后,性能可进一步增强。
Kiss3DGen的核心创新点在充分利用现有2D图像生成模型的知识与框架,将多视图图像和对应法线贴图拼接成三维聚合图(3D Bundle Image),把传统3D生成问题转化为2D图像生成任务。

这种方式无需调整现有2D模型的结构,能够最大程度继承其成熟的技术优势。
具体流程可分为两大步骤:
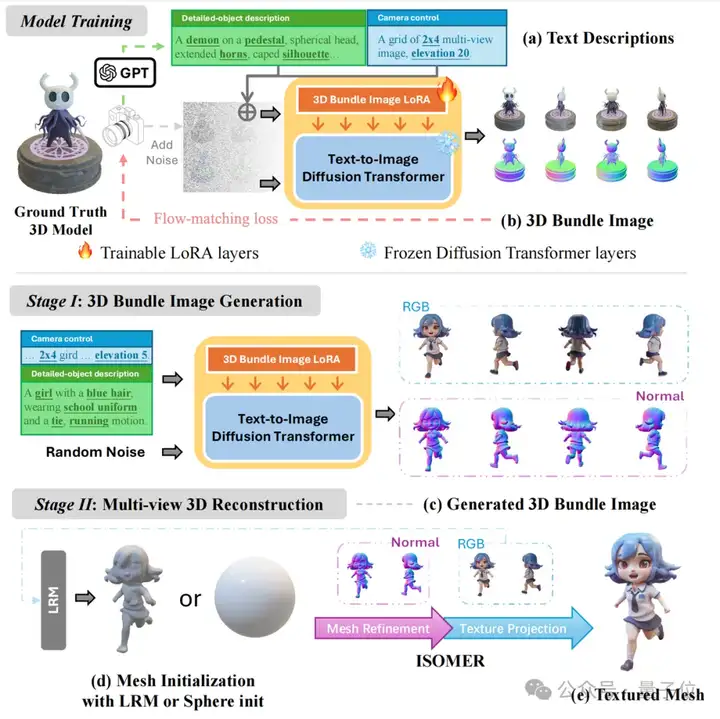
在训练阶段,需要构建高质量文本-3D数据集,使用LoRA技术对预训练的文本-图像扩散模型(如Flux或SD3.5)进行微调,生成高度符合文本描述的三维聚合图。
而生成阶段又可以分为两个环节——
首先利用训练好的模型,根据输入文本提示,生成包含3D模型多视角信息的三维聚合图。
然后,通过LRM或球体初始化方法粗略重建几何和纹理,再通过网格优化与纹理投影技术(如ISOMER),精确重建3D模型的几何形状和纹理细节。
该研究的作者为林坚涛、杨鑫以及陈美羲,他们是来自于香港科技大学(广州)ENVISION实验室的硕博生。



本工作由趣丸科技资助,由陈颖聪教授带领硕博研究团队与趣丸科技联合打造。
陈颖聪,香港科技大学(广州)人工智能学域助理教授,博导,受国家人才计划青年项目资助,他长期致力于计算机视觉和视觉生成模型的研究,已在TPAMI、CVPR、ICCV、ECCV等顶级会议和期刊发表五十余篇论文。
陈教授的研究方向包括三维生成与重建、图像视频生成等,并多次以第一作者身份在顶级会议上做口头报告。
他的研究成果屡获大奖,包括ICCV 2023最佳论文提名和中国图像图形学会自然科学奖一等奖。
同时,陈教授也在多个学术会议和期刊中担任程序委员会成员或审稿人,并与多个科技公司建立了深入的合作关系。

论文:
https://arxiv.org/abs/2503.01370
代码:
https://github.com/EnVision-Research/Kiss3DGen
项目主页:
https://ltt-o.github.io/Kiss3dgen.github.io
在线体验:
https://gen3d.funnycp.com
实验室主页:
https://envision-research.hkust-gz.edu.cn/index.html
文章来自于“量子位”,作者“Kiss3DGen团队”。



【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
