# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
3 月 27 日凌晨,阿里通义千问团队发布 Qwen2.5-Omni。
这是 Qwen 系列中全新的旗舰级多模态大模型,专为全面的多模式感知设计,可以无缝处理包括文本、图像、音频和视频的各种输入,同时支持流式的文本生成和自然语音合成输出。

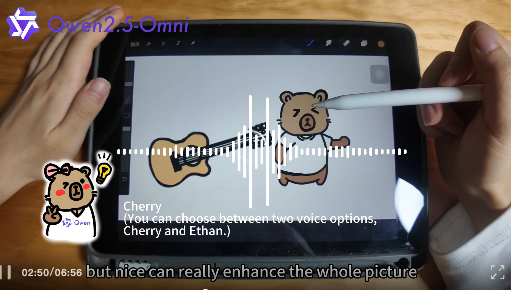
从此以后,你可以像打电话或进行视频通话一样与 Qwen 聊天!可以说是「语音聊天 + 视频聊天」都实现了。
体验地址:https://chat.qwen.ai/
更重要的是,团队人员将支持这一切的模型 Qwen2.5-Omni-7B 开源了,采用 Apache 2.0 许可证,并且发布了技术报告,分享所有细节!
现在,开发者和企业可免费下载商用Qwen2.5-Omni,手机等终端智能硬件也可轻松部署运行。

有网友表示,这才是真正的 Open AI。
大家可以通过官方 demo 感受一下 Qwen2.5-Omni 真实表现。
Qwen2.5-Omni 模型架构
Qwen2.5-Omni 具有以下特点:
前文我们已经提到,Qwen2.5-Omni 采用了 Thinker-Talker 架构。
Thinker 就像大脑一样,负责处理和理解来自文本、音频和视频模态的输入,生成高级表示以及对应的文本。
Talker 则像人类的嘴巴,以流式方式接收 Thinker 产生的高级表示和文本,并流畅地输出离散的语音 token。
Thinker 是一个 Transformer 解码器,配备有音频和图像的编码器,以便于提取信息。相比之下,Talker 被设计为一种双轨自回归 Transformer 解码器架构。
在训练和推理过程中,Talker 直接接收来自 Thinker 的高维表示,并共享 Thinker 的所有历史上下文信息。因此,整个架构作为一个统一的单一模型运行,实现了端到端的训练和推理。
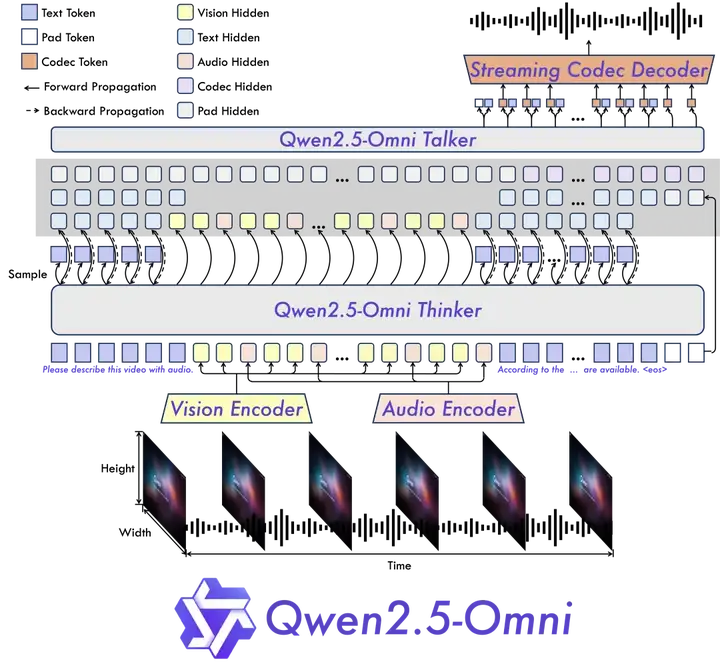
Qwen2.5-Omni 模型架构
模型性能
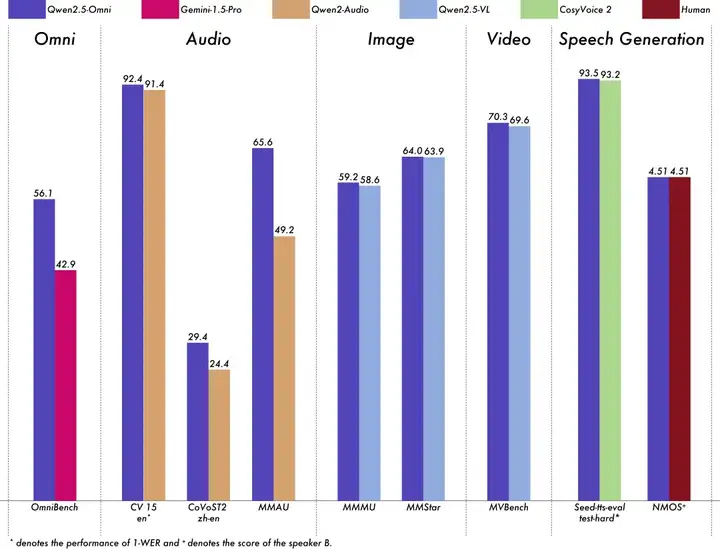
团队人员对 Qwen2.5-Omni 进行了全面评估,结果表明,该模型在所有模态上的表现均优于类似大小的单模态模型以及闭源模型,例如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro。
在需要集成多种模态的任务中,如 OmniBench,Qwen2.5-Omni 达到了最先进的水平。
此外,在单模态任务中,Qwen2.5-Omni 在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU, MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval 和 subjective naturalness)。
文章来自微信公众号 “ 机器之心 ”




【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
