# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一夜之间,CV被大模型“解决”了(狗头)。
万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。
一个男友回头表情包,可以秒变语义分割图。
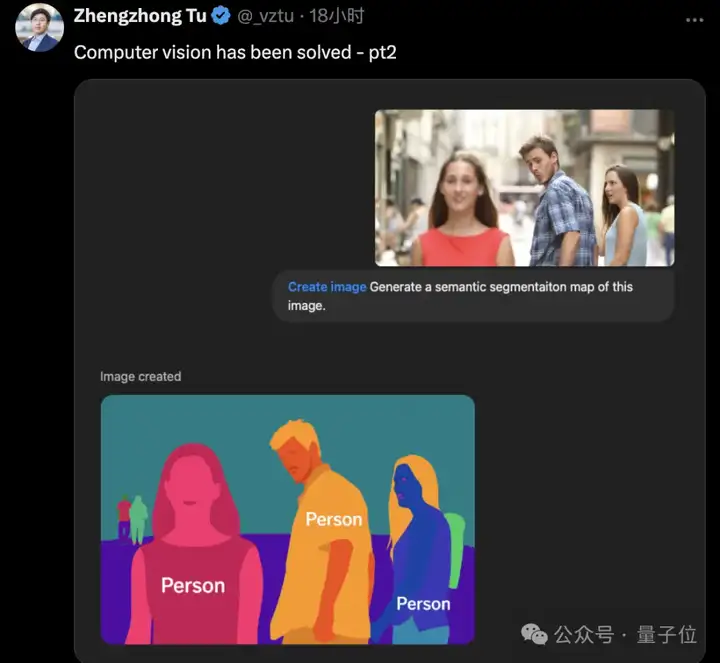
也可以秒变深度图。
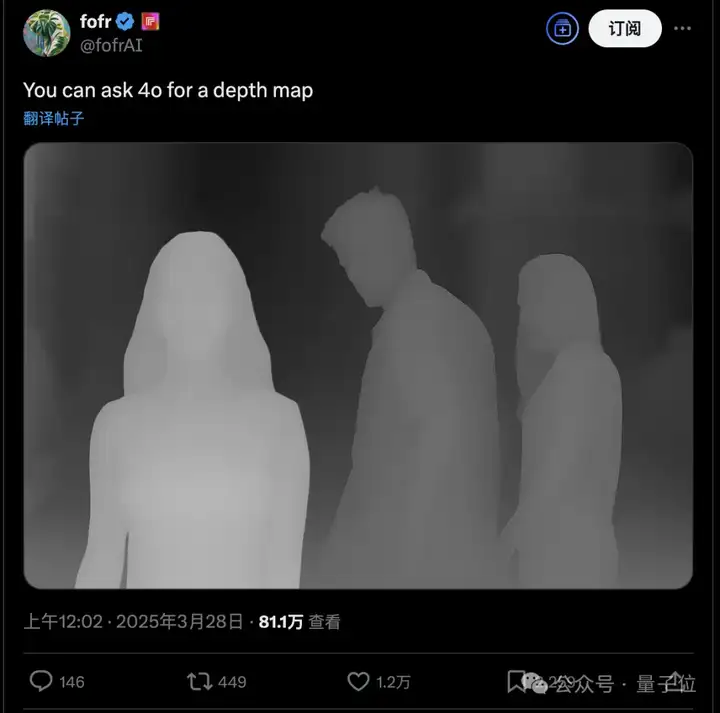
这下不光上一代AI画图工具和设计师,计算机视觉研究员也哭晕在厕所了。

这是NASA前工程师测试特斯拉自动驾驶系统的伪装“隐形墙”,在GPT-4o面前也无所遁形。

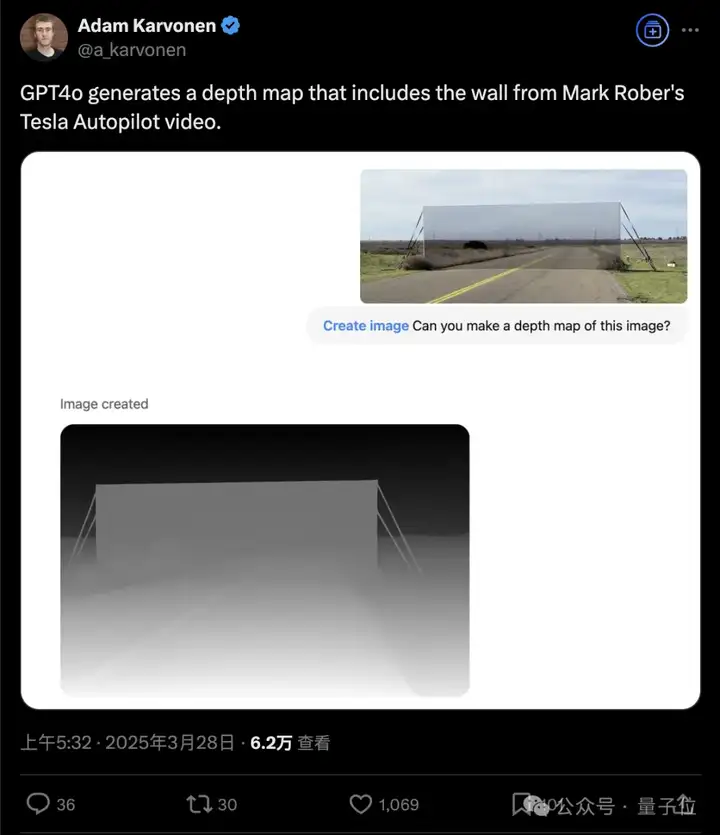
这下OpenAI应用研究主管Boris Power已经把脑筋动到了自动驾驶,称只需要训练最强大的基础模型,然后微调。

3D渲染领域也惨遭毒手,GPT-4o可以生成PBR材质(基于物理渲染的材质),纹理、法线贴图等直接来一套。
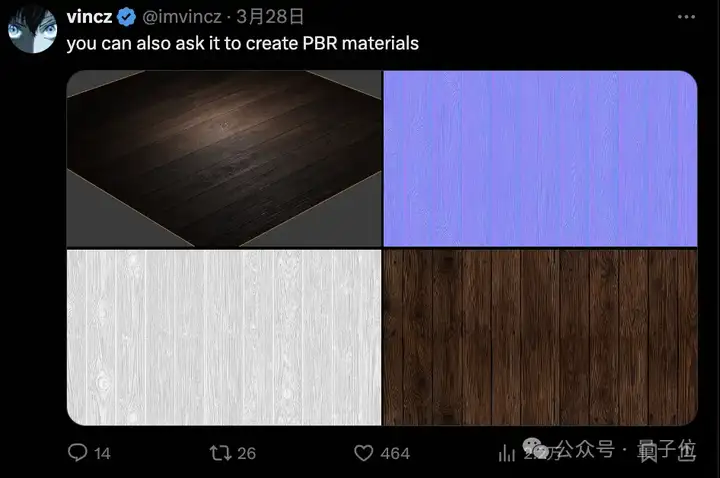
对于这些能力,也有人认为没什么大不了的,Stable Diffusion + ControlNet就可以全部实现。
但不可否认,靠扩大基础模型规模就能做到,也是令人意想不到的。
这波GPT-4o原生图像生成的技术细节,OpenAI是一点也没有公布(粗节也没有公布)。
但还是有人从System Card中发现了蛛丝马迹。
与DALL·E是一个扩散模型不同,GPT-4o图像生成是原生嵌入在ChatGPT内的自回归模型。

还有人观察图像的生成过程,发现很可能是多尺度自回归的组合,先生成一个粗略的图像,填充细节的同时,粗略图形本身也在变化。
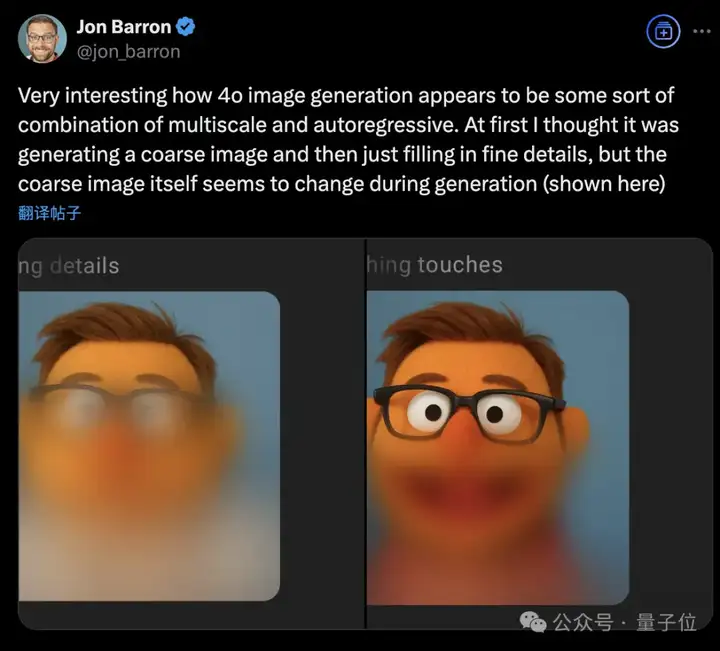
自回归模型根据之前的像素或patch预测下一个像素或patch,获得更好地遵循指令,以及图像编辑的能力。
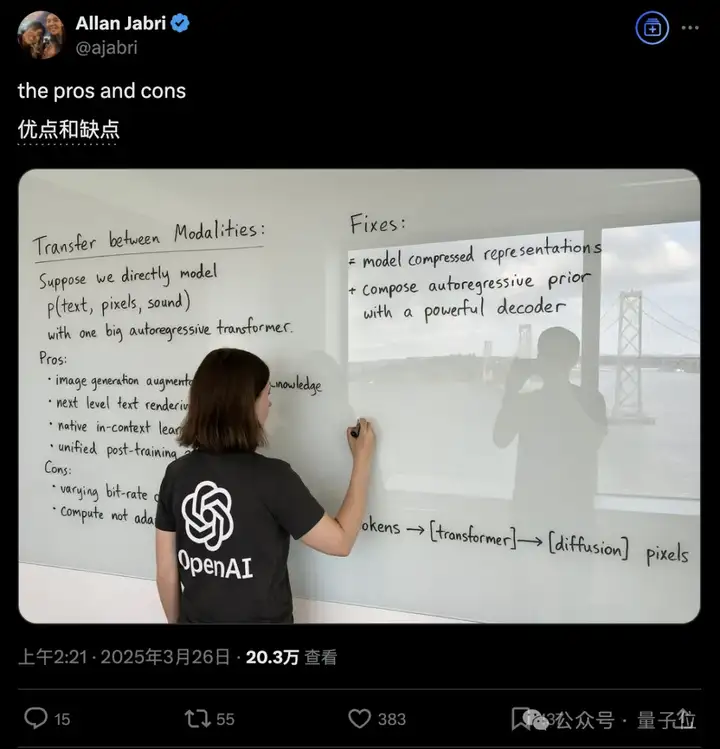
但也有人引用发OpenAI员工Allan Jabri晒出的板书图,提出在解码阶段仍然有可能用了扩散模型。
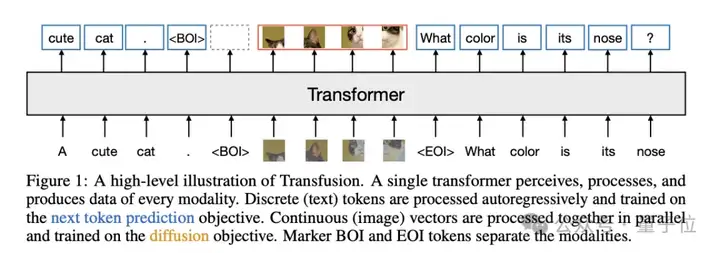
针对这一猜想,更具体的实现方法可以参考Meta等24年8月的一篇论文:使用一个多模态模型同时预测预测下一个token和扩散图像。

最后,微信评论区能发图片了,欢迎大家把更多GPT-4o有趣玩法晒出来~
GPT-4o Native Image Generation System Card
https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
https://arxiv.org/abs/2408.11039v1
参考链接:
[1]https://x.com/fofrAI/status/1905289275316326679
[2]https://x.com/a_karvonen/status/1905372299814932963
文章来自微信公众号 “ 量子位 ”,作者 梦晨




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
