# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近来风头正盛的GPT-4.5,不仅在日常问答中展现出惊人的上下文连贯性,在设计、咨询等需要高度创造力的任务中也大放异彩。
当GPT-4.5在创意写作、教育咨询、设计提案等任务中展现出惊人的连贯性与创造力时,一个关键问题浮出水面:
写一篇基于图片的短篇小说、分析一张复杂的教学课件、甚至设计一份用户界面……
这些对于人类驾轻就熟的任务,对于现有的部分多模态大模型却往往是“高难动作”。
但现有的评测基准首先难以衡量多模态大模型的输出是否具有创造性的见解,同时部分情境过于简单,难以真实反映模型在复杂场景下的创造性思维。
如何科学量化“多模态创造力” ?
为此,浙江大学联合上海人工智能实验室等团队重磅发布Creation-MMBench——
全球首个面向真实场景的多模态创造力评测基准,覆盖四大任务类别、51项细粒度任务,用765个高难度测试案例,为MLLMs的“视觉创意智能”提供全方位体检。

在人工智能的“智力三元论”中,创造性智能(Creative Intelligence)始终是最难评估和攻克的一环,主要涉及的是在不同背景下生成新颖和适当解决方案的能力。
现有的MLLM评测基准,如MMBench、MMMU等,往往更偏重分析性或实用性任务,却忽略了多模态AI在真实生活中常见的“创意类任务”。
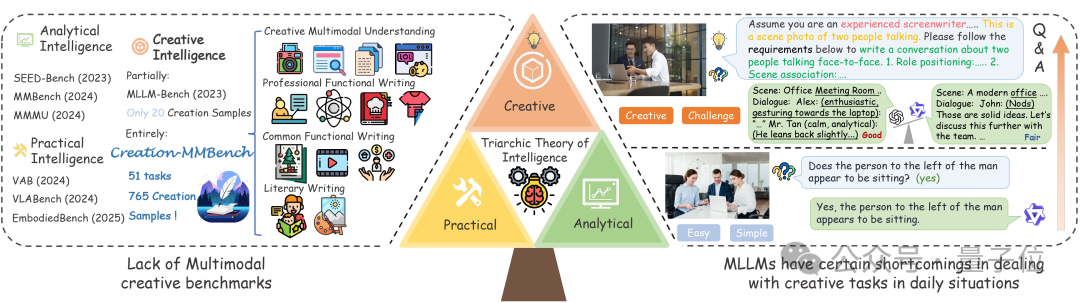
虽然存在部分多模态基准纳入了对模型创意力的考察,但他们规模较小,多为单图,且情境简单,普通的模型即可轻松回答出对应问题。
相较而言,Creation-MMBench设置的情境复杂,内容多样,且单图/多图问题交错,能更好的对多模态大模型创意力进行考察。
举个例子
让模型扮演一位博物馆讲解员,基于展品图像生成一段引人入胜的讲解词。
让模型化身散文作家,围绕人物照片撰写一篇情感性和故事性兼备的散文。
让模型亲自上任作为米其林大厨,给萌新小白解读菜肴照片并用一份细致入微的菜品引领菜鸟入门。
在这些任务中,模型需要同时具备“视觉内容理解 + 情境适应 + 创意性文本生成”的能力,这正是现有基准难以评估的核心能力。

四大任务类型:Creation-MMBench共有51个任务,主要可分为四个类别,分别是
这一类别旨在评估模型在艺术性和创造性表达方面的能力,例如生成富有情感的文字、
构建引人入胜的叙事或塑造生动的角色形象。典型人物包括故事续写、诗歌撰写等。
这类任务强调实用性,考察模型在处理真实场景中常见写作需求时的表现,例如撰写电子邮件、回答生活中的实际问题等。
这一类别要求模型具备较强的专业知识背景和逻辑推理能力,能够应对较为复杂且高度专业化的工作场景。
此类别评估模型在处理多模态信息(如文本与图像结合)时的表现,考察其是否能够从视觉内容中提取关键信息,并将其转化为有意义的创意输出。

千张跨域图像:在图像上,Creation-MMBench 横跨艺术作品、设计图纸、生活场景等近30个类别,涉及千张不同图片。
单任务最多支持9图输入,逼真还原真实创作环境。
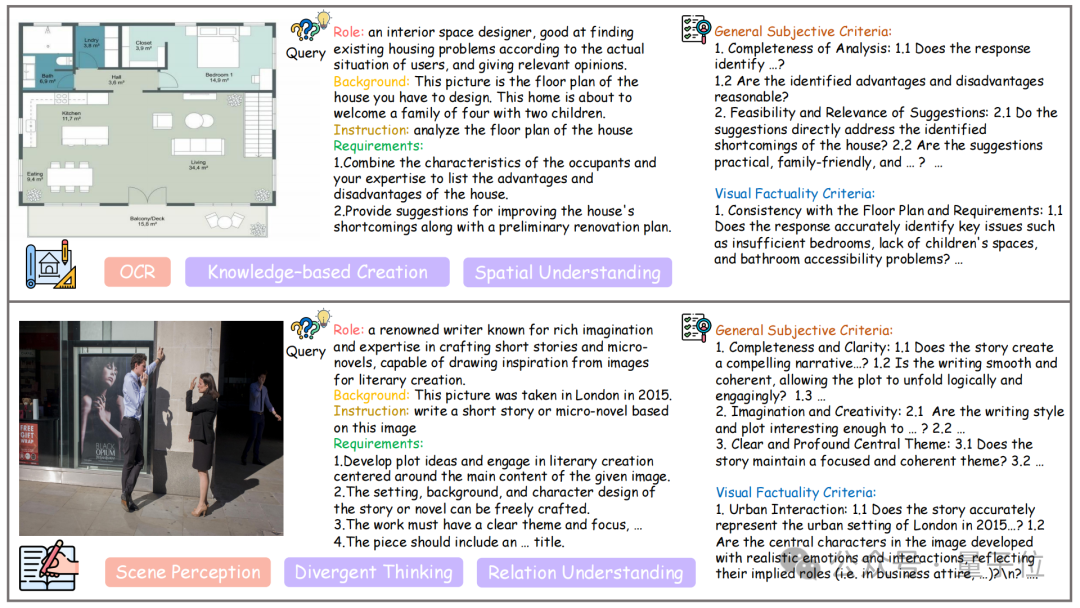
复杂现实情境:对于每一个实例,都基于真实图像进行标注,配套明确角色、特定背景、任务指令与额外要求四部分共同组成问题。
同时,相较于其他广泛使用的多模态评测基准,Creation-MMBench 具有更全面和复杂的问题设计,
大多数问题的长度超过 500 个词元,这有助于模型捕捉更丰富的创意上下文。
在评估策略上,团队选择了使用多模态大模型作为评判模型,同时使用两个不同指标进行双重评估。
视觉事实性评分(VFS):确保模型不是“瞎编”——必须读懂图像细节。
对于部分实例,需要首先对模型对图像的基础理解能力进行评估,以避免胡乱创作骗得高分。
团队对这类实例逐个制定了视觉事实性标准,对图片关键细节进行严卡,按点打分。
创意奖励分(Reward):不仅看懂图,更得写得好、写得巧!
除了基础理解能力外,Creation-MMBench更注重考察的是模型结合视觉内容的创造性能力与表述能力。
因为每个实例的角色、背景、任务指令与额外要求均存在不同,
因此团队成员对每个实例制定了贴合的评判标准,从表达流畅性、逻辑连贯性到创意新颖性等多方面进行评价。
此外,为了确保评判的公正性和一致性,GPT-4o作为评判模型,
会充分结合评判标准、画面内容、模型回复等内容,
在双向评判(即评估过程中对两个模型位置进行互换,避免评估偏差)下给出模型回复与参考答案(非标准答案)的相对偏好。
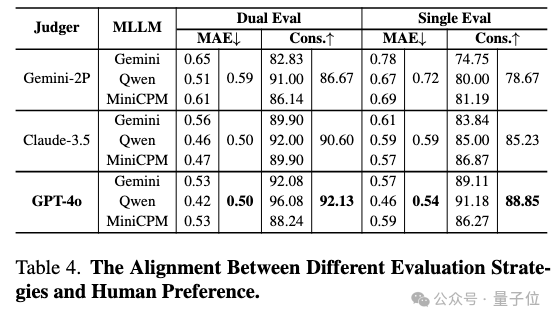
为了验证评判模型和采用的评判策略的可靠性,团队招募了志愿者对13%的样本进行人工评估,结果如上图所示。
相较于其他评判模型,GPT-4o展现出了更强的人类偏好一致性,同时也证明了双向评判的必要性。
团队基于VLMEvalKit工具链,对20多个主流MLLMs进行了全面评估,包括GPT-4o、Gemini系列、Claude 3.5,以及Qwen2.5-VL、InternVL等开源模型。
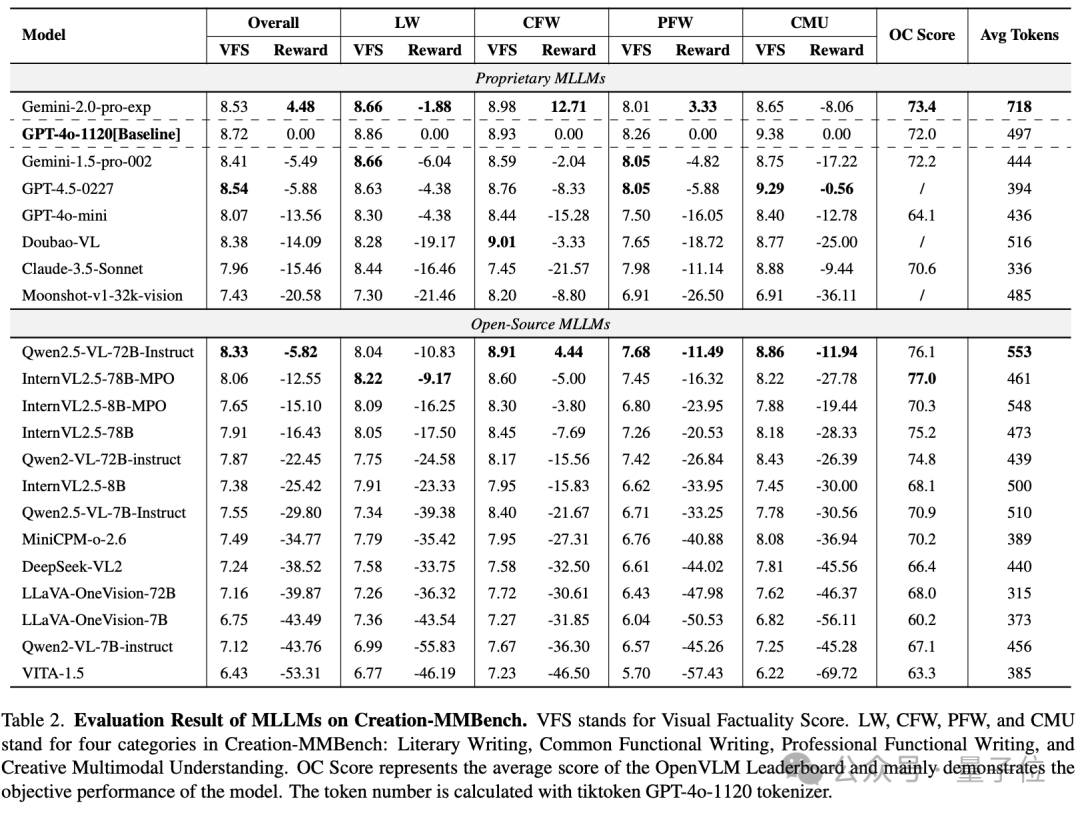
整体而言,与GPT-4o相比,Gemini-2.0-Pro 展现出了更为出众的多模态创意性写作能力,
在部分任务如日常功能性写作上能有效的整合图像生成贴合日常生活的内容。
它强大的先验知识也在专业功能性写作上极大的帮助了它,但对于部分细粒度视觉内容理解上,仍与GPT-4o存在不小的差距。
令人惊讶的是,主打创意写作的GPT-4.5的整体表现却弱于Gemini-pro和GPT-4o,但在多模态内容理解及创作任务上展现出了较为出众的能力。
开源模型如Qwen2.5-VL-72B,InternVL2.5-78B-MPO等也展现出了与闭源模型可以匹敌的创作能力,但整体而言仍与闭源模型存在一定差距。
从类别上表现来看,专业功能性写作由于对专业性知识的需求高、对视觉内容的理解要求深因而对模型的问题难度较大,
而日常功能性写作由于贴近日常社交生活,情境和视觉内容相对简单,因而整体表现相对较弱的模型也能有良好的表现。
尽管大多数模型在多模态理解与创作这一任务类型上视觉事实性评分较高,但它们基于视觉内容的再创作仍然存在一定瓶颈。
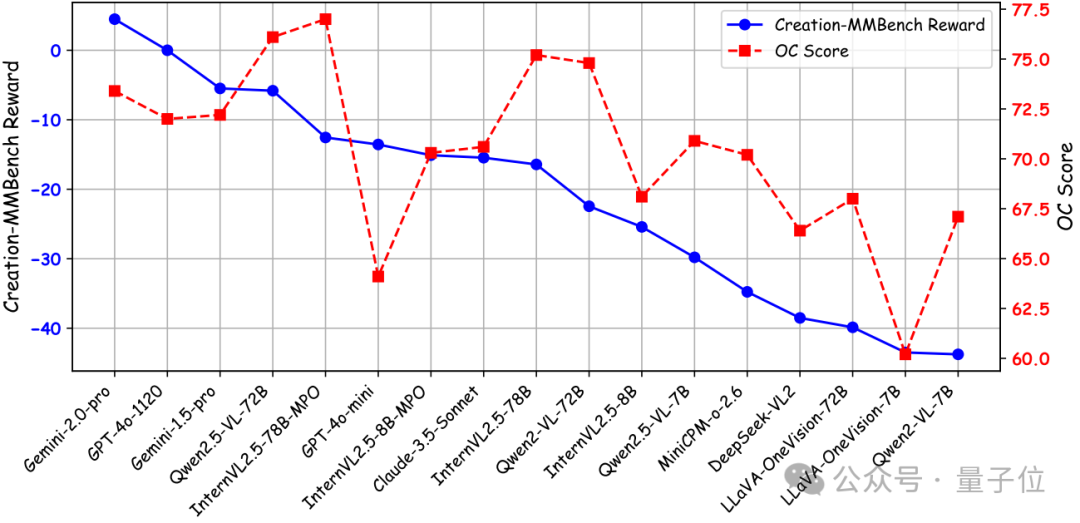
为了更好地比较模型的客观性能与其视觉创造力,团队使用 OpenCompass 多模态评测榜单的平均分 来表示整体客观性能。
如上图所示,部分模型尽管在客观性能上表现强劲,但在开放式视觉创造力任务中却表现不佳。
这些模型往往在有明确答案的任务中表现出色,但在生成具有创造性和情境相关的内容方面却显得不足。
这种差异说明传统的客观指标可能无法完全捕捉模型在复杂现实场景中的创造能力,因而证明了Creation-MMBench填补这一领域的重要性。
当前大语言模型的创作能力评判基准多集中于特定主题(如生成科研idea),相对较为单一且未能揭示LLM在多种不同日常场景中的创作能力。
因此团队使用GPT-4o对图像内容进行细致描述,构建了纯文本的Creation-MMBench-TO。
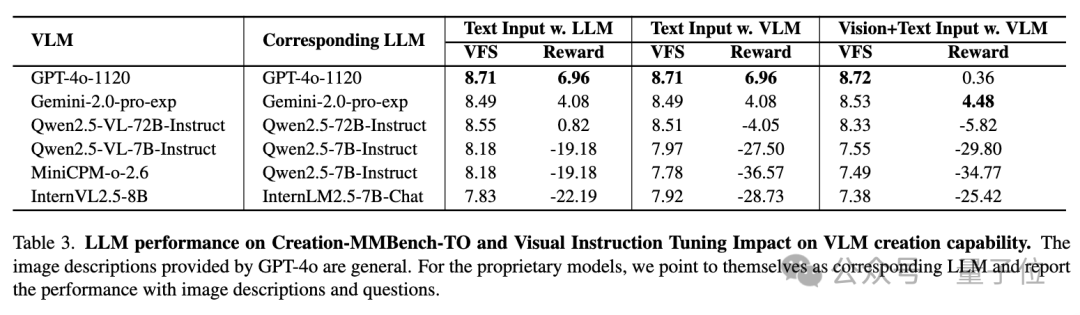
从纯语言模型的评测结果来看,闭源LLM的创作能力略优于开源的LLMs,令人惊讶的是,GPT-4o 在 Creation-MMBench-TO 上的创意奖励分更高。
这可能是因为该模型能够在描述的帮助下更专注于发散思维和自由创作,从而减少基本视觉内容理解对创造力的负面影响。
同时为了进一步调查视觉指令微调对LLM的影响,团队进行了对比实验,
结果表明,经过视觉指令微调的开源多模态大模型在 Creation-MMBench-TO 上的表现始终低于相应的语言基座模型。
这可能是由于微调过程中使用的问答对长度相对有限,限制了模型理解较长文本中详细内容的能力,
进而无法代入情境进行长文本创作,从而导致视觉事实性评分和创意奖励分均相对较低。

团队同样还对部分模型进行了定性研究,如上图所示。任务类型为软件工程图像解释,从属于专业功能性写作。
结果显示,Qwen2.5-VL 由于对特定领域知识理解不足,将泳道图误判为数据流图,从而导致后续的图表分析错误。
相比之下,GPT-4o 有效避免了这个错误,其整体语言更加专业和结构化,展示了对图表更准确和详细的解释,从而获得了评审模型的青睐。
这个例子也反映了特定学科知识和对图像内容的详细理解在这一类任务中的重要作用,表现出了开源模型和闭源模型间仍存在一定差距。
Creation-MMBench是一个新颖的基准,旨在评估多模态大模型在现实场景中的创作能力。该基准包含 765 个实例,涵盖 51 个详细任务。
对于每个实例,他们撰写了对应的评判标准,以评估模型回复的质量和视觉事实性。
此外,团队通过用相应的文本描述替换图像输入,创建了一个仅文本版本 Creation-MMBench-TO。
对这两个基准的实验全面的评估了主流多模态大模型的创作能力,并探查出了视觉指令微调对模型的潜在负面影响。
Creation-MMBench现已集成至 VLMEvalKit,支持一键评测,完整评估你的模型在创意任务中的表现。想知道你的模型能不能讲好一个图像里的故事?
来试试 Creation-MMBench 一键跑分,用数据说话。
Paper: https://arxiv.org/abs/2503.14478
Github: https://github.com/open-compass/Creation-MMBench
HomePage: https://open-compass.github.io/Creation-MMBench/
文章来自于微信公众号 “量子位”,作者 :上海AI Lab 团队



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
