# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天在各大信息渠道看到 Llama4 发布的消息,一上来就放出三个模型,具体能力这里就不在赘述,相信大家已经多少看到不少介绍了。

我比较感兴趣的是 Llama 4 Scout的上下文长度达到了 1000w token,并且可以在单 GPU 运行。
同时也查了市面上能够达到 1000w上下文的其他模型:
传统的大型语言模型通常受限于较短的上下文窗口,如8K、32K或128K。
扩展到一千万标记的上下文窗口不仅仅是线性提升,而是带来了本质上的能力突破。
当模型能够同时处理数百页文本时,它不再需要将信息分割成小块来理解,而是能够把握材料的整体结构和内容之间的复杂关联。
这种能力使AI从处理片段转变为处理完整信息体系,从而实现更深层次的理解和推理。
可以预见的是 2025 年其他大模型厂商应该会逐步跟进千万上下文 token 的基础能力,现在的基模厂商之间的竞争很有意思。
一方面每家模型大厂都要有点绝活儿,画图的,写代码的,出报告的,开源的,推理的等等。
另一方面,每当一个现象级能力得到用户认可时,几乎都会在很短的时间内跟进,越来越多的受欢迎功能作为模型的出厂能力直接端到用户面前,这个现象似乎从 DS R1后有愈演愈烈的趋势,谁都不想落后。
我记得之前是奥特曼说过一句话,做应用层的不要想着靠一时的工程能力补齐大模型的所谓短板,应该琢磨怎么好好利用最新的模型基础能力。
这句话在 Manus 身上得到了很好的验证,如今 Manus在内测初期火爆全球后,已经有5 亿美金的估值。
这基本上是一种风向。
应用侧需要输入更多的信息,要求给到大模型,在不同场景下精准的使用大模型的推理,给出更优,更长的回答。
这个完整生命周期越短,速度越快,结果质量越高,带给用户的体验就是越好,体验越好,那就会更坚定的续费月会员,年会员,商业的故事就讲的通了。
这一切,1000w token超长上下文一定是支撑AI 领域应用侧业务一个重要的因素。
我为什么在 Llama4 支持这个特性后写这篇文章?
因为不管它综合能力如何,
Llama一直是基模能力的风向标,在今天,开源的模型已经具备了这个能力,
其他闭源的大模型厂商会不跟进吗?
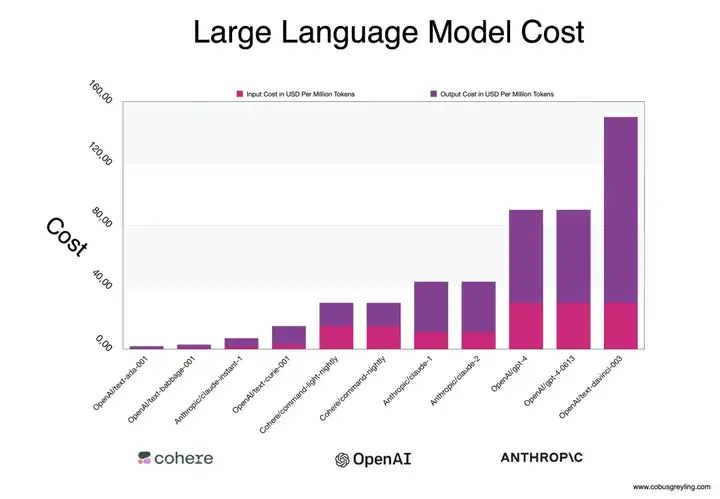
下面简单分析一下大模型达到 1000w 上下文带来的影响:
如果你的 prompt 足够优质和精确,那么现在很有可能让大模型给你一次性输出一本回忆录,小说,电影剧本。
Cursor 和 WindSurf可以不用非常频繁的因为长下文输出限制而被打断。
Manus的用户也不用傻傻的等在那里,半个小时得到一个尴尬的超出上下文而失败的结果。
视频内容通常需要分割成短片段处理,传统模型难以理解长视频的叙事结构和内容连贯性。
结合视频帧描述或字幕,千万上下文模型可以理解并分析整部电影或长视频的内容,把握叙事结构、人物发展、情节转折和视觉风格变化。
千万上下文模型可以分析极长的时间序列数据,识别长期趋势、季节性模式、异常事件和多层次周期性变化,提供更全面的时序分析。
气象学家可以上传50年的详细气象记录,模型能够发现长期气候变化模式、稀有天气事件的前兆特征以及多年周期现象。
金融分析师可以利用这种能力分析市场的长期结构性变化和宏观经济周期。
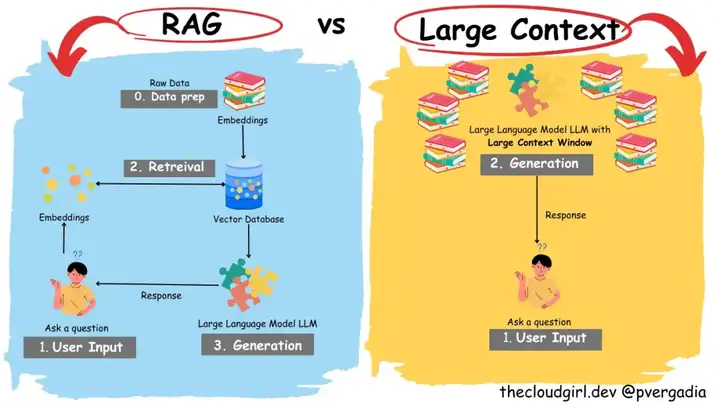
检索增强生成(RAG)是一种通过从外部知识库检索相关信息并将其添加到提示中来增强 LLM 知识的技术 。
虽然 RAG 对于访问实时信息和处理不断变化的知识仍然至关重要 , 但具有千万级 token 上下文窗口的 LLM 可以在其上下文中包含非常多的信息,以至于在许多用例中,对外部检索的需求可能会大大减少甚至消除 。
例如,可以将一个组织的所有内部文档加载到模型的上下文中,从而实现直接的、全面的信息访问 。
这简化了系统架构,提高了效率,并避免了与外部检索相关的潜在问题。
长上下文让业务行团队不再受制于因为 RAG 能力不足导致产品体验不佳,现在可以更加聚焦于业务的研发。
不过,这不代表 RAG 的消退,反而对 RAG 提出更高的要求:
如何在更复杂的prompt,更长的模型上下文中进行多路召回?
如何进行更优的 topk 重排?
如何解决长下文带来的私有知识库的暴增,向量数据库性能能跟上吗?
我之前写过一篇对比的文章,大家感兴趣的话可以读一下:
千万上下文使Agent能够从更庞大的知识库中汲取信息,不再需要频繁地访问外部资源。
Agent可以将大量专业资料、参考文献和过往案例一次性加载到工作记忆中,提供更深入、更全面的咨询服务。
传统Agent在规划和执行复杂任务时,由于上下文限制,往往需要不断重新规划和调整。
千万上下文使Agent能够制定更完善的长期计划,同时记住计划的每个细节和依赖关系,保持执行的连贯性。
传统Agent通常专注于单一环境或任务类型,难以在多种环境间无缝切换。
使Agent能够同时保持对多个环境和任务的理解,实现真正的多功能整合。
能够构建更丰富的记忆系统,不仅记住更多的历史交互,还能形成更复杂的知识结构和经验模型,增强对新情况的适应能力。
Agent 可以利用更大的上下文窗口来记住长时间的交互、用户的长期偏好、复杂的任务流程和先前采取的行动 . 这使得 Agent 能够保持状态,理解长期目标,并提供更具上下文相关性和个性化的响应 。一个智能家居 Agent 可以记住用户数周的生活习惯,并根据这些习惯自动调整环境设置 .
Agent 可以处理包含更多信息和约束的复杂任务,从而能够制定更详细和全面的长期计划 。AI 驱动的项目管理 Agent 可以分析包含数千个任务和依赖关系的项目计划,并进行智能的资源分配和风险预测 .
Agent 通常需要使用外部工具和 API 来执行任务。具有更大上下文窗口的模型可以更好地理解工具的文档、记住先前工具使用的结果,并协调多个工具的协同工作,从而实现更智能和更有效的工具集成 .
能够处理多种模态的 Agent 可以从扩展的上下文中受益,以理解和协调来自不同来源的信息 ,智能助手可以分析用户的语音指令、屏幕截图和正在处理的文档,以提供更全面的帮助 .
当应用侧真正使用更多的 token且时,也意味着更多的推理算力,更大更强的 AI Infra, 大模型各种各样的 API 就像水电煤,阳光空气水的意义一样。
当 ToB 和 ToC 的业务再也离不开它时,它就不用担心生存和成本问题了,大模型API 价格一定会像韭菜一样便宜。
2025,
AI 的进化速度是以周为单位进化的,大家擦亮眼睛,不要错过。
文章来自于“一支烟花AI”,作者“一支烟一朵花”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
