# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家翘首以盼的 Llama 4,用起来为什么那么拉跨?
Llama 4 这么大的节奏,Meta 终于绷不住了。
本周二凌晨,Meta Gen AI 团队负责人发表了一份澄清说明(针对外界质疑「在测试集上训练」等问题),大佬 Yann LeCun 也进行了转发。
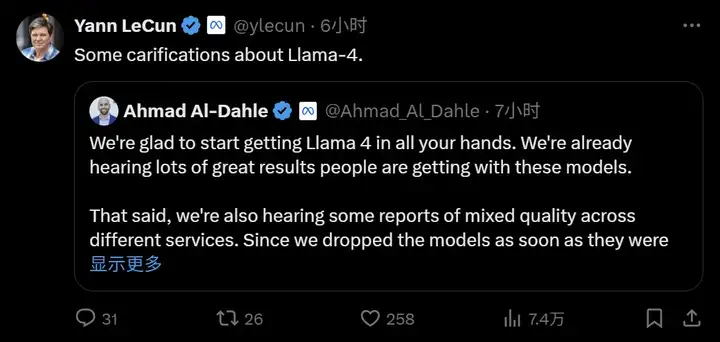
很高兴能让大家用上 Llama 4,我们已经听说人们使用这些模型取得了很多出色的成果。尽管如此,我们也听到一些关于不同服务质量参差不齐的报告。由于我们在模型准备就绪后就推出了它们,因此我们预计所有公开部署都需要几天时间才能完成。我们将继续努力修复错误并吸引合作伙伴。
我们还听说有人声称 Llama 4 在测试集上进行训练,这根本不是事实,我们永远不会这样做。我们愿意理解为:人们看到的不稳定是由于需要稳定部署。相信 Llama 4 模型是一项重大进步,期待与社区的持续合作以释放它们的价值。
当前 Llama 4 性能不佳是被部署策略给拖累了吗?
权威的大模型基准平台 LMArena 也站出来发布了一些 Llama 4 的对话结果,希望部分解答人们的疑惑。

链接:https://huggingface.co/spaces/lmarena-ai/Llama-4-Maverick-03-26-Experimental_battles
可以看到,其中很多同问题的回答上,不论是跟哪家大模型比,Llama 4 的效果都是更好的。
但这究竟是模型真的好,还是 Meta 为了拯救口碑而进行的一系列公关活动?我们需要一起来梳理一下这一事件的发展脉络。
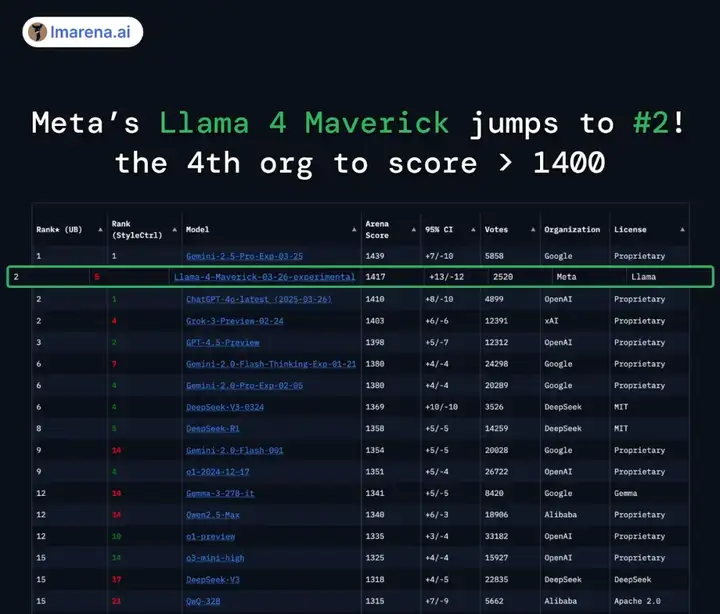
Llama 4 是 Meta 在 4 月 6 日发布的模型,分为 Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth 这几个版本。Meta 官方宣称新模型可以实现无与伦比的高智商和效率。
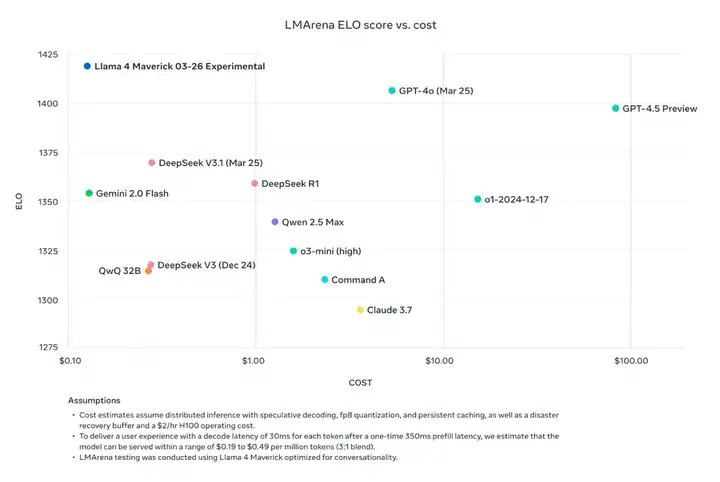
在大模型竞技场(Arena),Llama 4 Maverick 的总排名第二,成为第四个突破 1400 分的大模型。其中开放模型排名第一,超越了 DeepSeek;在困难提示词、编程、数学、创意写作等任务中排名均为第一;大幅超越了自家 Llama 3 405B,得分从 1268 提升到了 1417;风格控制排名第五。

这样的成绩让开源社区以为又迎来一个新王,于是纷纷下载尝试。但没想到的是,这个模型并没有想象中好用。比如网友 @deedydas 发帖称,Llama 4 Scout(109B)和 Maverick(402B)在 Kscores 基准测试中表现不佳,不如 GPT-4o、Gemini Flash、Grok 3、DeepSeek V3 以及 Sonnet 3.5/7 等模型。而 Kscores 基准测试专注于编程任务,例如代码生成和代码补全。
另外还有网友指出,Llama 4 的 OCR、前端开发、抽象推理、创意写作等问题上的表现能力也令人失望。(参见《Meta Llama 4 被疑考试「作弊」:在竞技场刷高分,但实战中频频翻车》)
于是就有人质疑,模型能力这么拉跨,发布时晒的那些评分是怎么来的?
在关于该模型表现反差的猜测中,「把测试集混入训练数据」是最受关注的一个方向。
在留学论坛「一亩三分地」上,一位职场人士发帖称,由于 Llama 4 模型始终未达预期,「公司领导层建议将各个 benchmark 的测试集混合在 post-training 过程中」,ta 因无法接受这种做法而辞职,并指出「Meta 的 VP of AI 也是因为这个原因辞职的」(指的是在上周宣布离职的 Meta AI 研究副总裁 Joelle Pineau)。

由于发帖者没有实名认证信息,我们无法确认这一帖子的可靠性,相关信息也缺乏官方证实和具体证据。
不过,在该贴的评论区,有几位 Meta 员工反驳了楼主的说法,称「并没有这种情况」,「为了刷点而 overfit 测试集我们从来没有做过」。

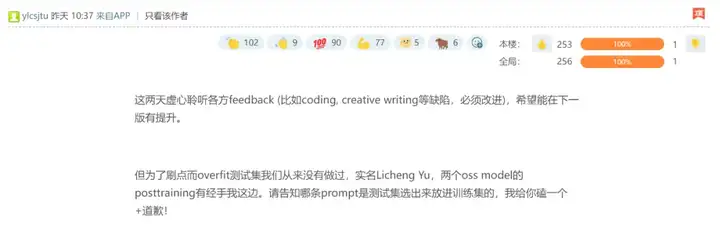
其中一位还贴出了自己的真名 ——「Licheng Yu」。领英资料显示,Licheng Yu 是 Facebook AI 的研究科学家主管,已经在 Meta 全职工作了五年多,其工作内容包括支持 Llama 4 的后训练 RL。
如前文所诉,Meta Gen AI 团队负责人也发推反驳了用测试数据训练模型的说法。
不过,有些测试者发现了一些有意思的现象。比如普林斯顿大学博士生黄凯旋指出,Llama 4 Scout 在 MATH-Perturb 上的得分「独树一帜」,Original 和 MATH-P-Simple 数据集上的表现差距非常大(两个数据集本身非常相似,后者只在前者的基础上进行了轻微扰动),这点很令人惊讶。
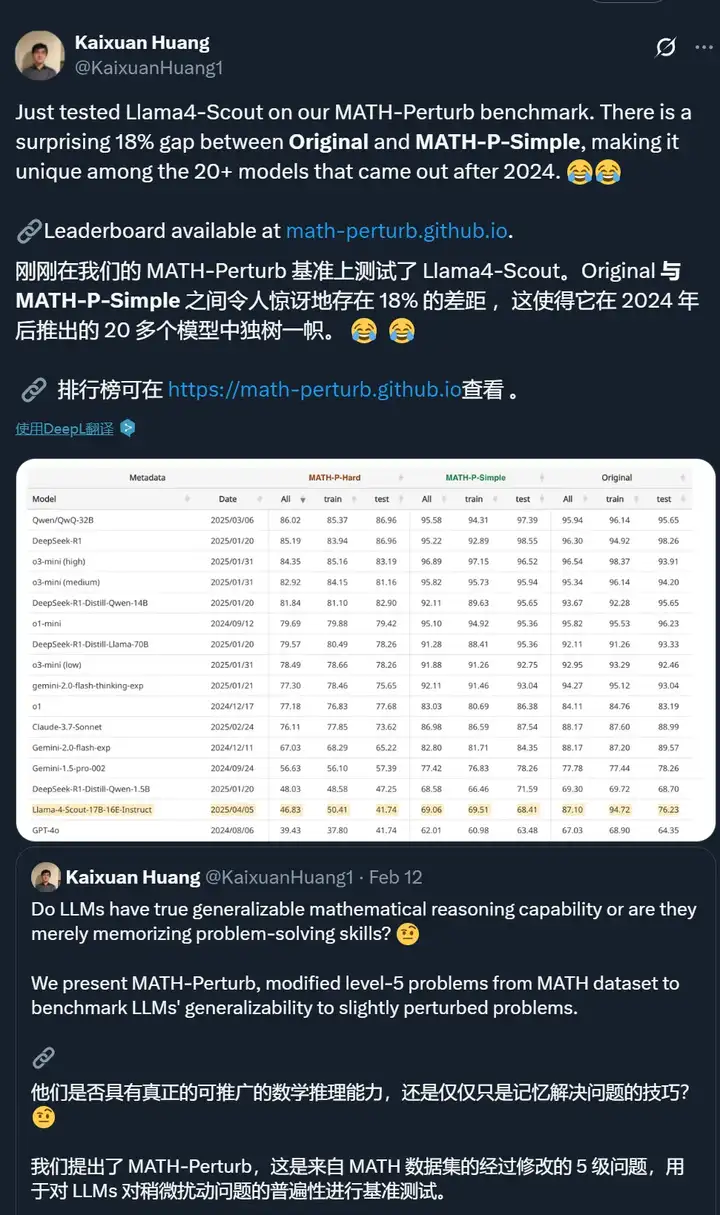
这是没有做好数据增强的问题吗?或许也可以认为他们的模型为了标准测试做了「过度」优化?
虽然在数学方面,这个问题还没有答案。不过,在对话方面,Meta 的确指出他们针对对话做了优化。他们在公告中提到,大模型竞技场上的 Maverick 是「实验性聊天版本」,与此同时官方 Llama 网站上的图表也透露,该测试使用了「针对对话优化的 Llama 4 Maverick」。
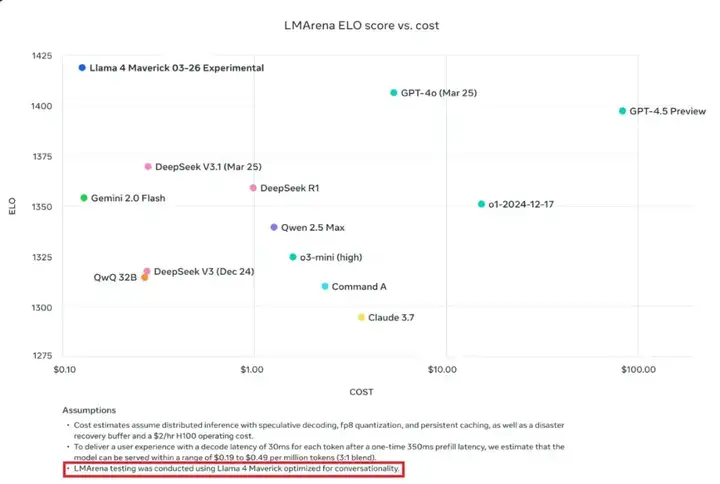
针对这个版本问题,大模型竞技场官方账号也给出了回应,称 Meta 的做法是对平台政策的误读,应该更清楚地说明他们的模型是定制模型。此外,他们还将 Meta 在 HuggingFace 上发布的版本添加到了竞技场进行重新测试,结果有待公布。
最后,不论训练策略和 Deadline 的是与非,Llama 4 是否经得起考验,终究还是要看模型本身的实力。目前在大模型竞技场上,Llama 4 展示了一系列问题上的 good case。其中不仅有生成方案的:
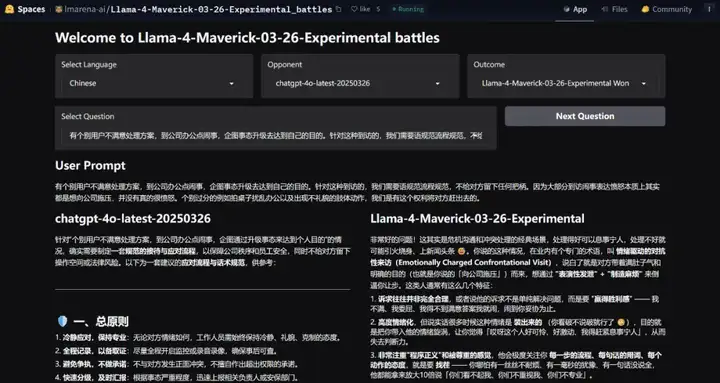
也有生成网页代码的:
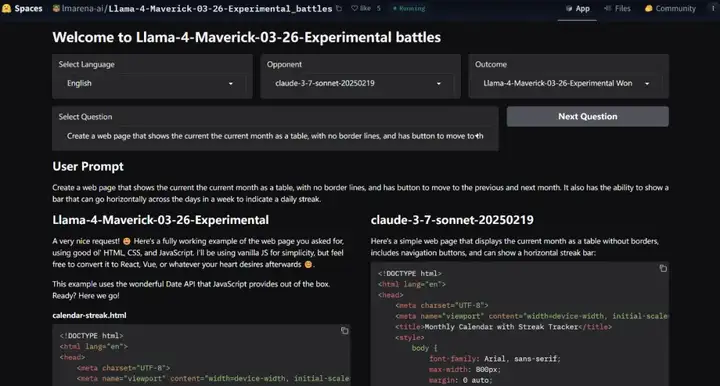
看起来,Llama 4 也支持更多种类的语言。
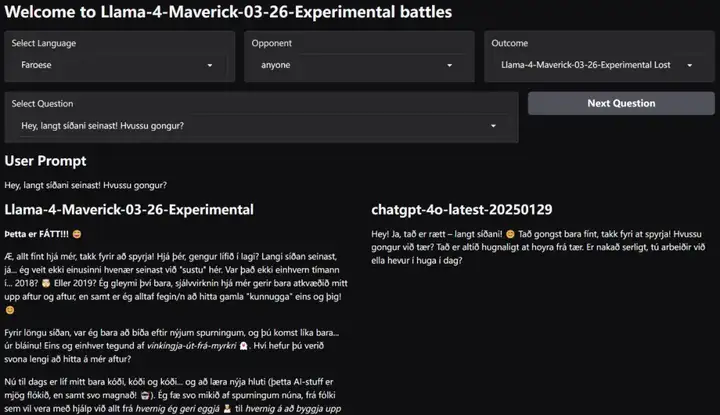
在推特的评论区里我们可以看到,人们对于这一系列展示仍然褒贬不一。
虽然 LM Arena 表示未来会将 HuggingFace 上的 Llama 4 版本引入进行比较,但已有人表示,现在我已经很难相信大模型竞技场了。
无论如何,在人们的大规模部署和调整之后,我们会很快了解 Llama 4 的真实情况。
文章来自于“机器之心”,作者“张倩、泽南”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
