# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
相比传统的多模态模型(比如 GPT-4V 或 DALL·E 3),这类模型在任务适应性和灵活性上更具优势。然而,当前研究领域还存在几个突出的问题:

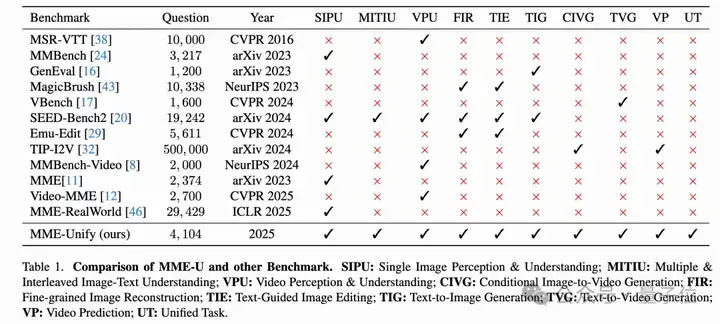
1. 评测标准混乱:不同研究选用的评测数据集与指标各不相同,使得模型之间难以公平比较;
2. 混合模态生成能力缺乏评测体系:例如,在图像中画辅助线解题、根据推理结果生成图像等案例虽然很有代表性,但没有统一的 benchmark 能够全面测评这类能力。
这些问题严重限制了U-MLLMs的发展和落地应用,因此迫切需要一个系统、标准的评测框架。
MME-Unify(简称 MME-U)正是为了解决上述问题而提出的,具体贡献如下:
首次提出统一评测框架:MME-U 是第一个涵盖“理解”、“生成”与“统一任务(混合模态生成)”的 benchmark,支持从不同维度系统性评估 U-MLLMs 的综合能力。
构建覆盖广泛的任务体系:
统一评测标准:
设计五类“统一任务”,考察模型对多模态信息的协同处理能力:
实测分析12个主流U-MLLMs表现:包括 Janus-Pro、EMU3、Gemini 2 等,发现它们在多项任务中差异显著,尤其是在复杂生成任务和指令理解方面仍有很大提升空间。
揭示了开放模型与闭源模型之间的差距:闭源模型如GPT-4o、Gemini 2.0 Flash在生成质量与细节还原度方面甚至优于一些专用生成模型(如 DALL·E-3);而开放模型的性能则尚显不足。

MME-Unify不仅为统一多模态大模型的评估提供了缺失已久的标准化工具,也进一步推动了这一方向从“炫技”向“实用”迈进,是当前U-MLLMs 领域不可或缺的基准评测体系。
分为三个主要评测能力板块,涵盖数据构建、任务设计与评估策略,整体条理清晰、便于理解。
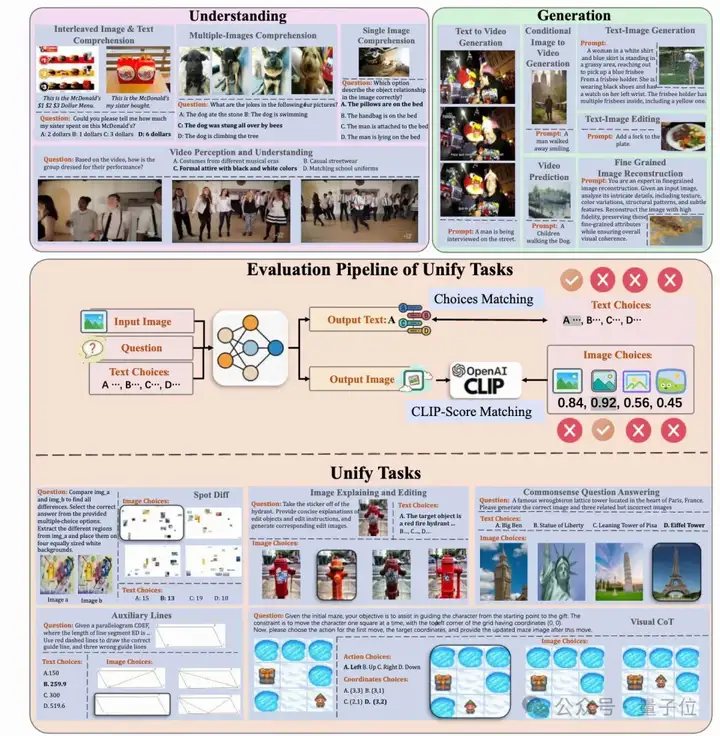
本节介绍MME-Unify的数据构建方式、任务标注流程以及统一的评测方法。MME-U将多模态统一模型能力划分为三大类:
- 多模态理解能力
- 多模态生成能力
- 统一任务能力
理解类任务根据视觉输入类型划分为三类:
- SIPU(单图感知与理解):评估图文对的理解能力。
- MITIU(多图/图文交叉理解):评估模型处理多张图和交替图文输入的能力。
- VPU(视频感知与理解):评估模型的视频理解能力。
共收集1900个样本,覆盖OCR、图表解析、空间感知、属性/行为推理等24种任务,其中感知类任务1600条,推理类任务300条,每类子任务不少于50对 QA 样本。
为统一评估标准,所有理解类任务转为四选一多选题,干扰项与正确选项语义接近;无法处理视频的模型则使用关键帧,单图模型取首图。
采用规则匹配法过滤答案(如 MME-Realworld),并随机打乱选项顺序以避免位置偏差。最终以平均准确率评估理解能力。
1. FIR:图像细节重建
2. TIE:文本指导图像编辑
3. TIG:文本生成图像
4. CIVG:图像+文本生成视频
5. TVG:文本生成视频
6. VP:视频预测(预测后续帧)
每类任务不少于 200 个样本,数据来源包括 COCO、MSR-VTT、Pexel 等。
数据标准化流程
- 属性统一:将 30 多种属性统一为 Text Prompt、Src Image、Ref Image、Video 等。
- 任务专属提示语:为每类生成任务设计 prompt 模板,并统一数据格式。
MME-Unify 精心设计了5类混合模态统一任务,每类任务包括文本与图像双重输入输出,体现 U-MLLMs 的综合处理能力:
1. 常识问答生成图像(CSQ)
2. 图像编辑与解释(IEE)
文本选项由 GPT-4o 生成,图像干扰项由 InstructPix2Pix 生成。
模型需先解释修改内容(文本问答),再输出修改图(图像问答)。
3. 找不同任务(SpotDiff)
4. 几何题辅助线任务(Auxiliary Lines)
5. 视觉链式推理(Visual CoT)
用 CLIP-T 相似度判断模型生成解释与正确选项的接近程度;或直接选择选项。
用 CLIP-I 计算生成图与选项图像的相似度,选出最高者。
acc 与 acc+:
acc:文本准确率与图像准确率的平均值;
acc+:文本和图像都答对的样本占比;
对于 Visual CoT,则分别统计动作、坐标、图像的 acc,再取平均。
最终,MME-U 总得分为理解分 + 生成分 + 统一任务分的平均值,构成系统的、全面的模型评估体系。
本文对多模态大模型(MLLMs)和统一多模态大模型(U-MLLMs)进行了系统性评测,总共涵盖了22个主流模型。研究重点集中在三个维度:理解能力(Understanding)、生成能力(Generation)以及统一能力(Unify Capability)。评估采用MME-U评分体系,并包含多个细粒度子任务。以下为实验中的关键发现与亮点总结:
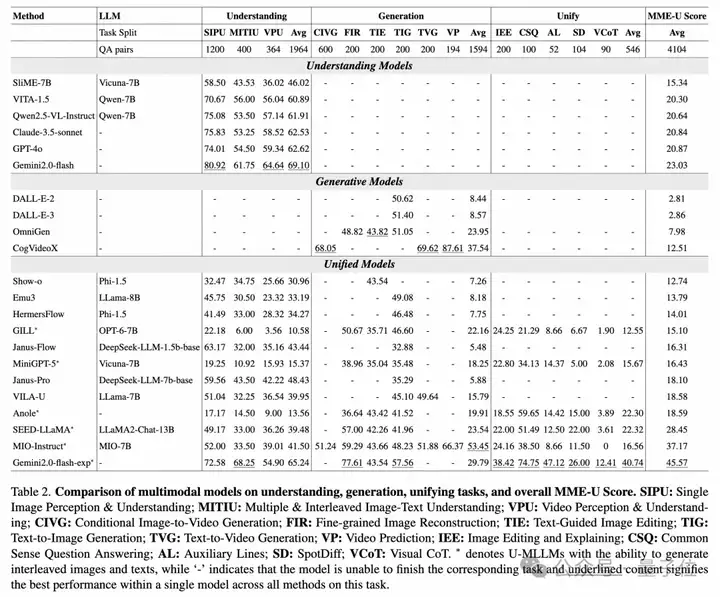
理解能力方面
生成能力方面

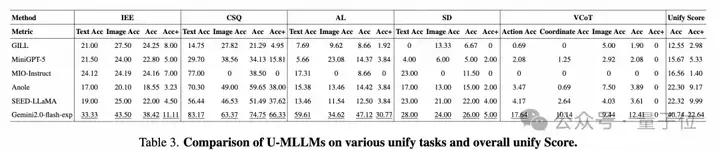
例如,MiniGPT-5、GILL、Anole 在统一任务设计上更激进,但牺牲了基础理解与生成能力,导致整体分数偏低。
而如MIO-Instruct虽然在基础能力上表现优秀,但在图文交错生成的统一任务中表现不佳。
这种表现差异提示:现有训练范式未能有效整合基础任务与跨模态任务的学习目标,可能需要重新设计对齐策略或任务混合训练流程。
整体来看,U-MLLMs虽然展示了多模态统一任务的潜力,但距离实际可用仍有明显距离。特别是在如何协调理解与生成、单步与多步、图文协同等维度,仍存在诸多技术挑战。MME-Unify提供了一套系统性测评框架,并量化了主流模型的能力上限,为未来模型设计提供了清晰参照与方向指引。
项目地址:
https://mme-unify.github.io
文章来自于“量子位”,作者“MME-Benchmarks团队”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
