# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
学术写作通常需要花费大量精力查询文献引用,而以ChatGPT、GPT-4等为代表的通用大语言模型(LLM)虽然能够生成流畅文本,但经常出现“引用幻觉”(Citation Hallucination),即模型凭空捏造文献引用。
这种现象严重影响了学术论文的可信度与专业性。
现在,加拿大滑铁卢大学与卡内基梅隆大学的华人研究团队,提出了一种名为 ScholarCopilot 的智能学术写作大模型框架,专门针对学术场景,致力于精准地生成带有准确引用的学术文本。

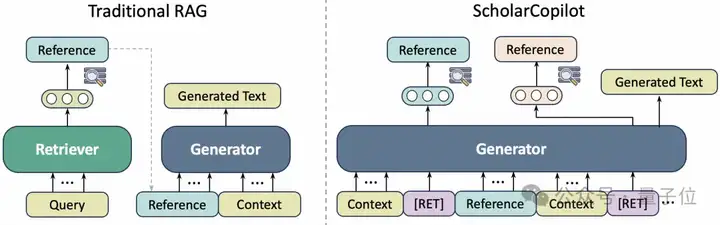
传统的检索增强生成(Retrieval-Augmented Generation, RAG)方法采用“先检索、再生成”的静态流程,这种方式存在以下问题:
针对这些局限性,ScholarCopilot提出了一种“边生成、边检索”的动态机制:
简单来说,ScholarCopilot的写作方式更接近人类真实的写作习惯:平时正常撰写论文内容,当需要引用文献时再主动检索相关文献的BibTeX信息插入引用,随后继续撰写下文。同时,模型在撰写后续内容时,也会参考已插入的引用文献,确保生成的文本与引用内容紧密相关。
研究团队以阿里云近期发布的Qwen-2.5-7B模型为基础,使用了50万篇arXiv论文进行训练,并在多个维度上进行了性能评估:
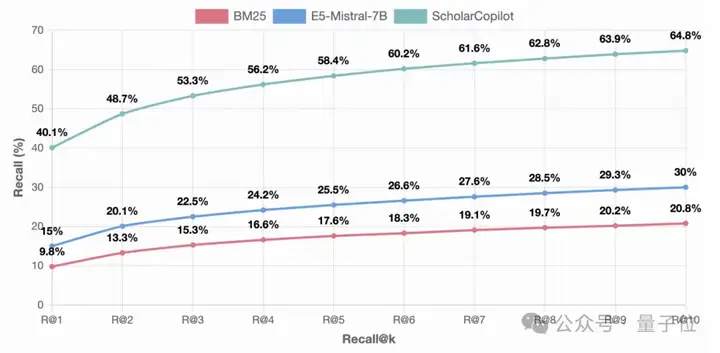
引用检索准确性(Top-1 accuracy)达到40.1%,显著超过现有的检索模型:
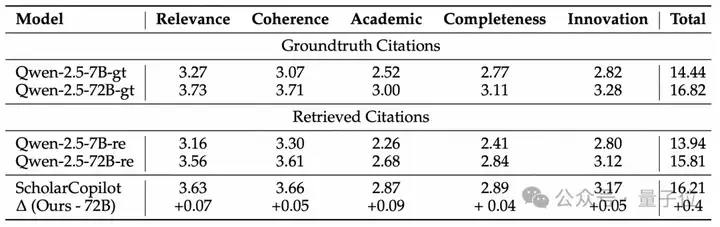
论文生成质量方面(包括相关性、连贯性、学术严谨性、完整性和创新性),综合得分为16.2(满分25),高于参数量更大的Qwen-2.5-72B-Instruct模型(15.8)和Qwen-2.5-7B-Instruct模型(13.9)。
在一项由10位拥有平均4.2年学术写作经验的学生(5名博士、4名硕士、1名本科生)参与的真人评测中:
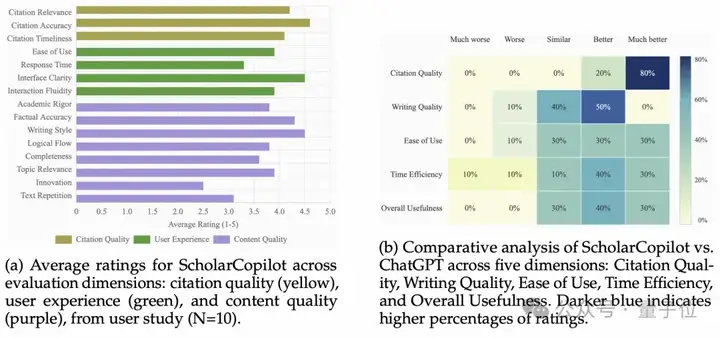
尽管取得了显著进步,ScholarCopilot仍存在一些局限性。通过上述用户调研,受访者提出了以下几点改进建议:
此外,受访者还建议未来版本可考虑:
研究团队表示,这些反馈意见为后续开发提供了明确的改进方向。
ScholarCopilot研究团队希望通过不断优化模型性能、扩展检索数据库和改进用户交互体验,让研究人员在学术写作中能更专注于研究本身,而非繁琐的文献检索与引用管理。
当前相关论文、代码与模型已经公开发布,感兴趣的读者可自行了解详细信息,进一步体验与评估该模型的实际表现:
论文链接:https://arxiv.org/pdf/2504.00824
项目网站:https://tiger-ai-lab.github.io/ScholarCopilot/
演示视频:https://www.youtube.com/watch?v=QlY7S52sWDA
文章来自于“量子位”,作者“ScholarCopilot团队”。



【开源免费】paperai是一个可以快速通过关键词搜索到真实文献并将其应用到论文写作当用的功能。
项目地址:https://github.com/14790897/paper-ai
在线使用:www.paperai.life
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
