# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌 Gemma 3 上线刚刚过去一个月,现在又出新版本了。
该版本经过量化感知训练(Quantization-Aware Training,QAT)优化,能在保持高质量的同时显著降低内存需求。

比如经过 QAT 优化后,Gemma 3 27B 的 VRAM 占用量可以从 54GB 大幅降至 14.1GB,使其完全可以在 NVIDIA RTX 3090 等消费级 GPU 上本地运行!
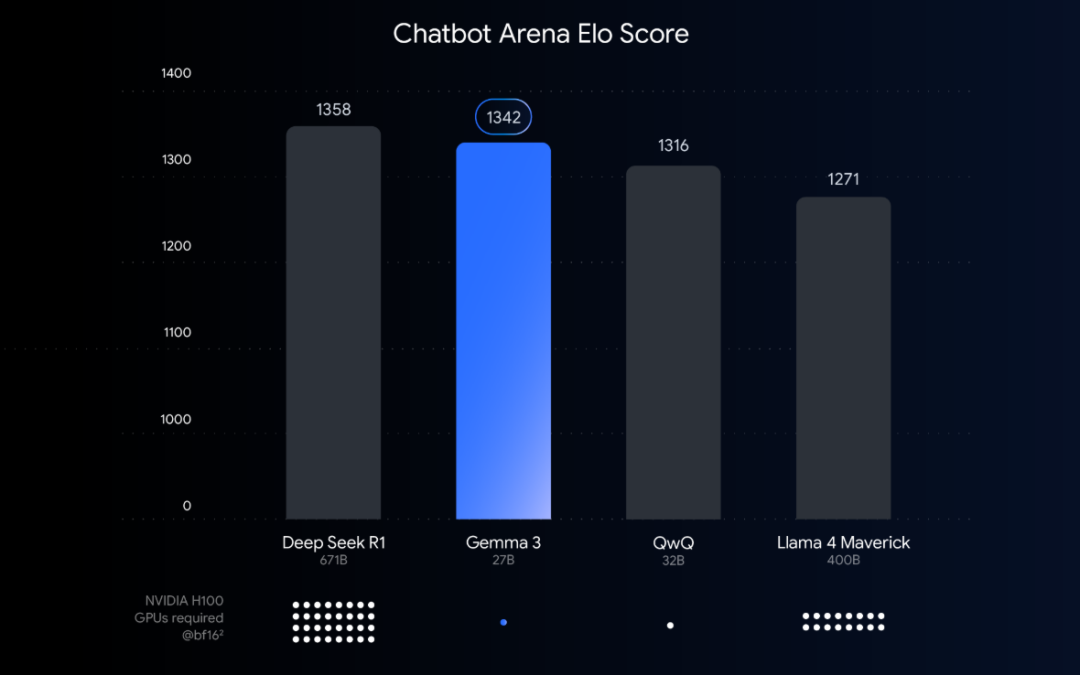
Chatbot Arena Elo 得分:更高的分数(最上面的数字)表明更大的用户偏好。点表示模型使用 BF16 数据类型运行时所需的 NVIDIA H100 GPU 预估数量。
机器之心在一台配备了 RTX 3070 的电脑上简单测试了其中的 12B 版本,可以看到虽然 Gemma 3 的 token 输出速度不够快,但整体来说还算可以接受。
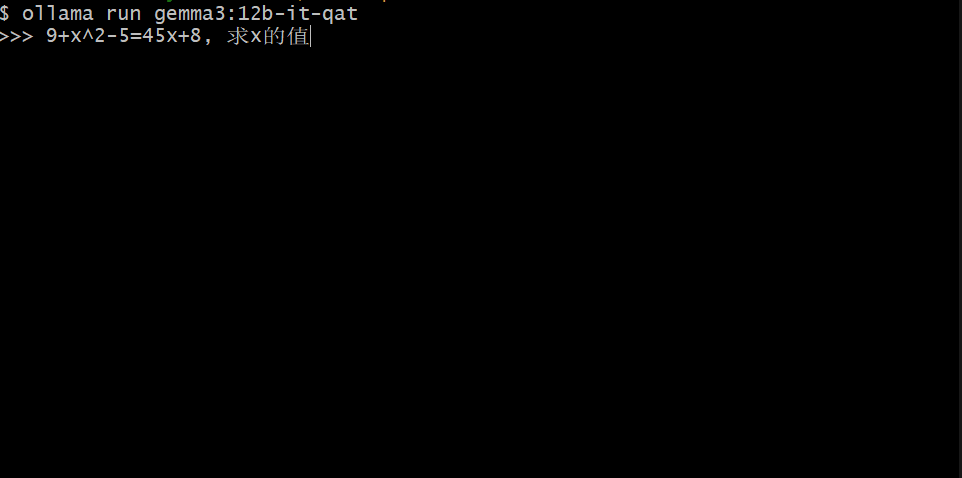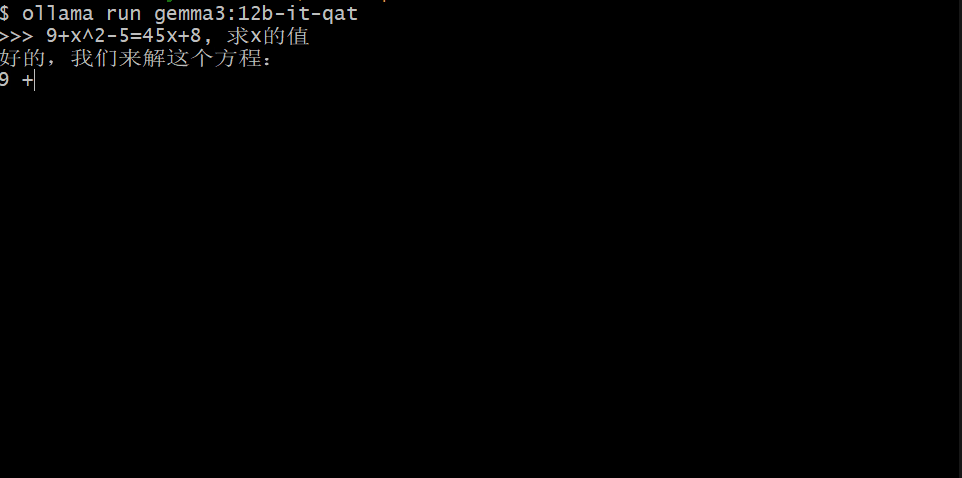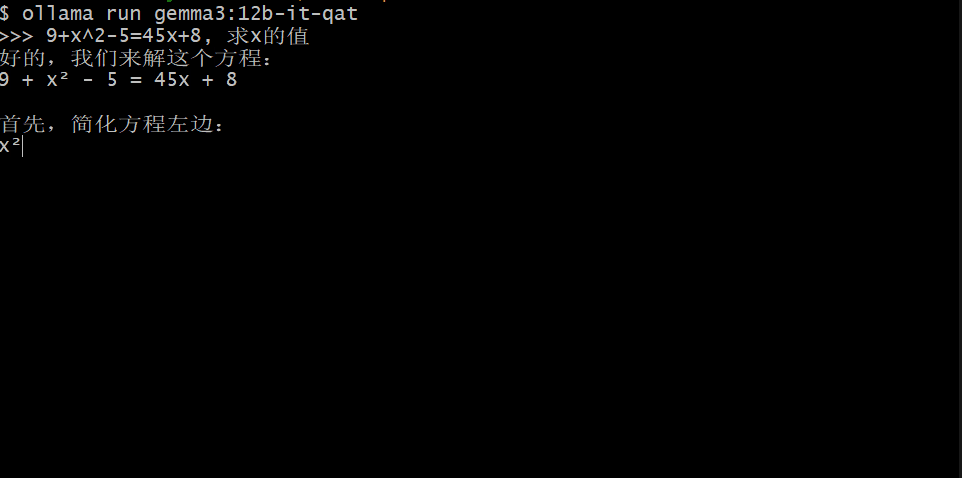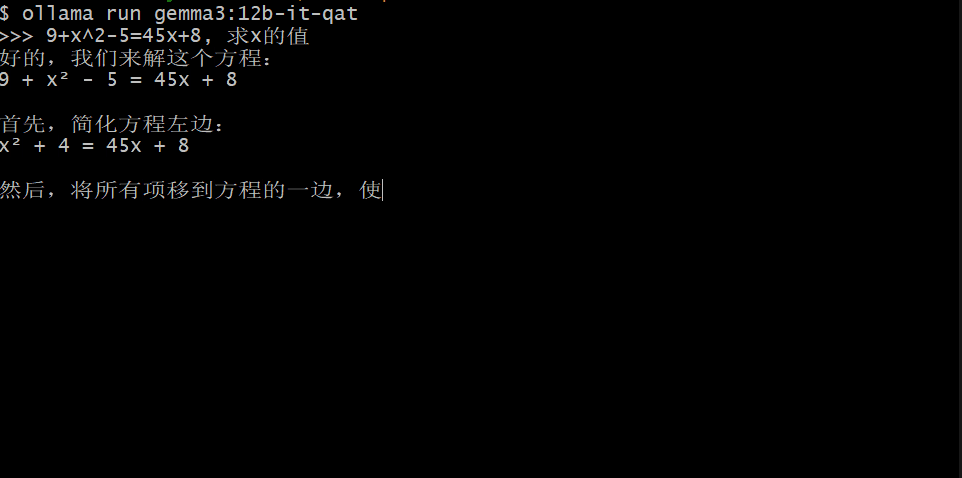
在 AI 模型中,研究者可以使用更少的位数例如 8 位(int8)甚至 4 位(int4)进行数据存储。
采用 int4 量化意味着每个数值仅用 4 bit 表示 —— 相比 BF16 格式,数据大小缩减至 1/4。
但是,这种量化方式通常会导致模型性能下降。
那谷歌是如何保持模型质量的?答案是采用 QAT。
与传统在模型训练完成后才进行量化的方式不同,QAT 将量化过程直接融入训练阶段 ——
通过在训练中模拟低精度运算,使模型在后续被量化为更小、更快的版本时,仍能保持准确率损失最小化。
具体实现上,谷歌基于未量化的 checkpoint 概率分布作为目标,进行了约 5,000 步的 QAT 训练。
当量化至 Q4_0(一种常见的量化格式) 时,困惑度下降了 54%。
这样带来的好处之一是加载模型权重所需的 VRAM 大幅减少:
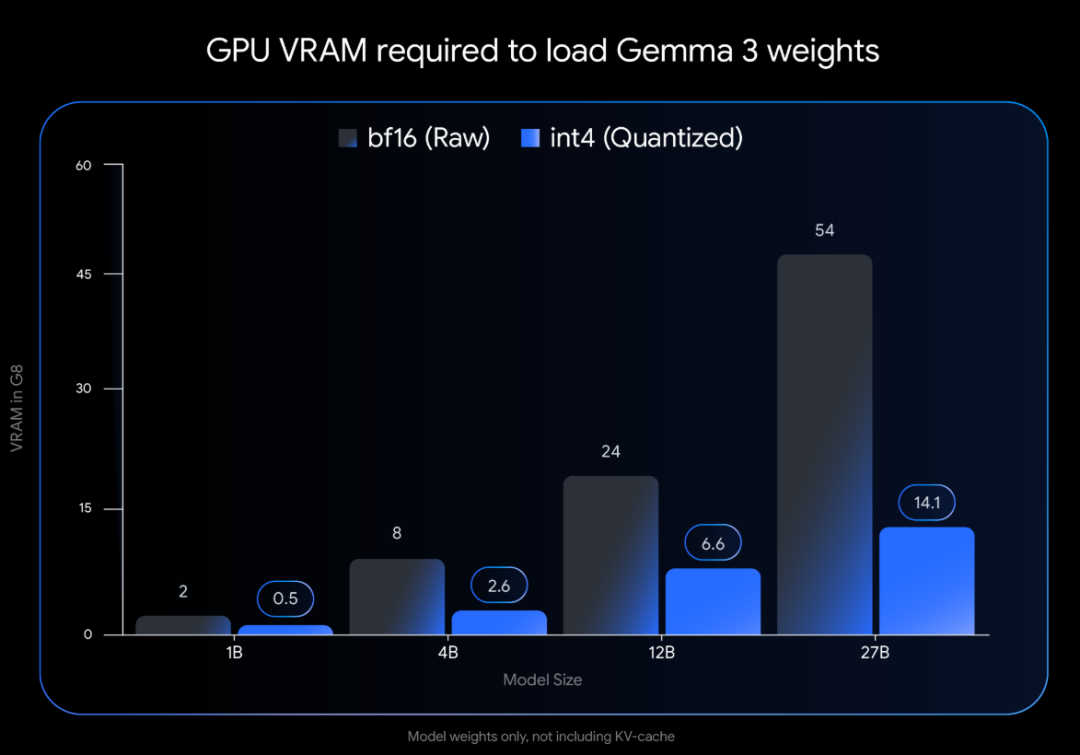
此图仅表示加载模型权重所需的 VRAM。运行该模型还需要额外的 VRAM 用于 KV 缓存,该缓存存储有关正在进行的对话的信息,并取决于上下文长度。
现在看来,用户在消费级设备上就能运行更大、更强的 Gemma 3 模型,其中:

来自 Two Minute Papers 频道的玩笑
官方 int4 和 Q4_0 非量化 QAT 模型已在 Hugging Face 和 Kaggle 上线。谷歌还与众多热门开发者工具合作,让用户无缝体验基于 QAT 的量化 checkpoint:
激动的网友已经无法抑制内心的喜悦:「我的 4070 就能运行 Gemma 3 12B,这次谷歌终于为即将破产的开发者做了一些事情。」
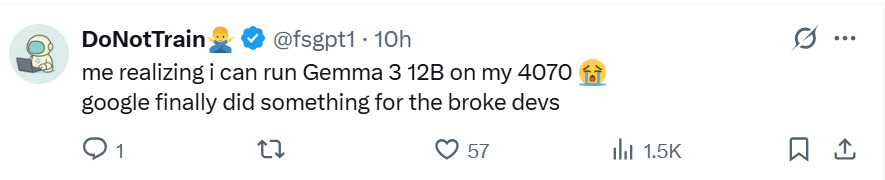
「希望谷歌朝着 1bit 量化使使劲。」

这个可以本地运行的 Gemma 3 你用了吗,效果如何,欢迎大家评论区留言。
参考链接:https://developers.googleblog.com/en/gemma-3-quantized-aware-trained-state-of-the-art-ai-to-consumer-gpus/?linkId=14034718
文章来自于微信公众号 “机器之心”,作者 :机器之心编辑部




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
