# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
小米也卷入了开源大模型的战场!
今天上午,小米发布了其首个开源推理大模型-Xiaomi MiMo。
通过 25 T 预训练 + MTP 加速 + 规则化 RL + Seamless Rollout,让 7 B 参数的 MiMo-7B 在数理推理和代码生成上赶超 30 B-32 B 大模型,并完整 MIT 开源全系列与工程链,给端-云一体 AI 落地提供了“以小博大”的新范例。
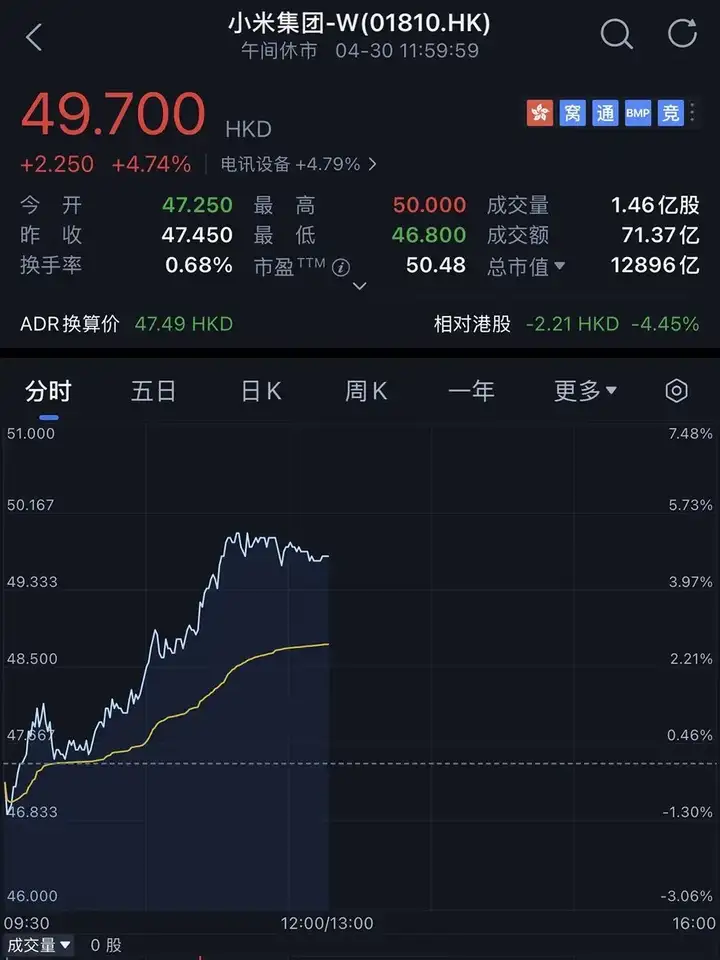
受此消息影响,截至午间休市,今日小米股价上涨4.74%,总市值1.29万亿港元(约合人民币1.21万亿元)。
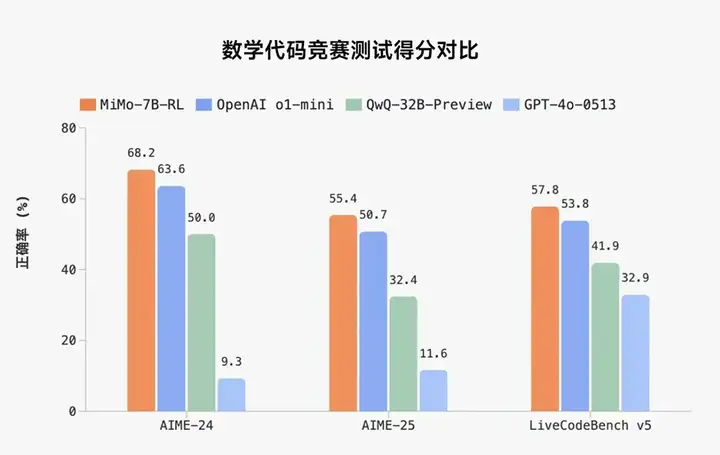
MiMo-7B 系列模型在多个权威的推理能力基准测试中取得了令人瞩目的成绩,尤其是经过强化学习调优后的 MiMo-7B-RL 版本,在极具挑战性的数学竞赛级基准 AIME 2025 上,取得了 55.4% 的 Pass@1 分数,显著领先于 01-mini 的 50.7% 。在 AIME 2024 上的得分也达到了 68.2% 。
在持续更新的算法代码生成基准 LiveCodeBench v5 上,MiMo-7B-RL 得分 57.8%,超越 01-mini (53.8%) 。在更新、更难的 LiveCodeBench v6 上,MiMo-7B-RL 更是达到了 49.3%,大幅领先 01-mini (46.8%) 及其他同类模型,展现了其强大的代码生成稳定性和实力 。
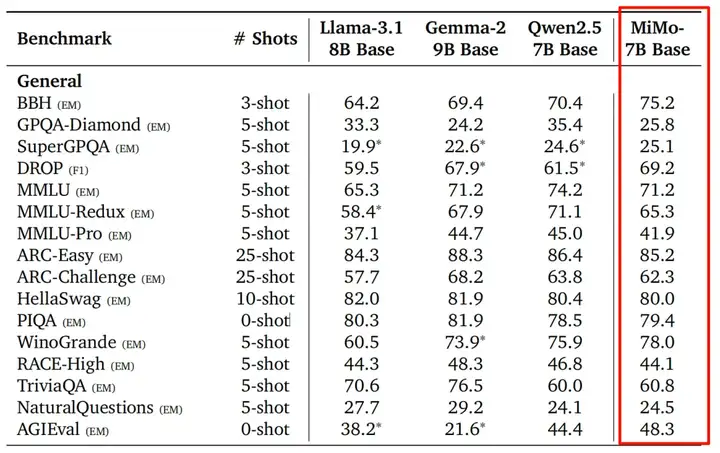
尽管强化学习阶段专注于数学和代码,MiMo-7B-RL 在 MMLU-Pro、GPQA Diamond、SuperGPQA、DROP 等衡量通用知识、科学问答、阅读理解的基准上也保持了极具竞争力的表现,优于许多同类甚至参数量更大的模型 。
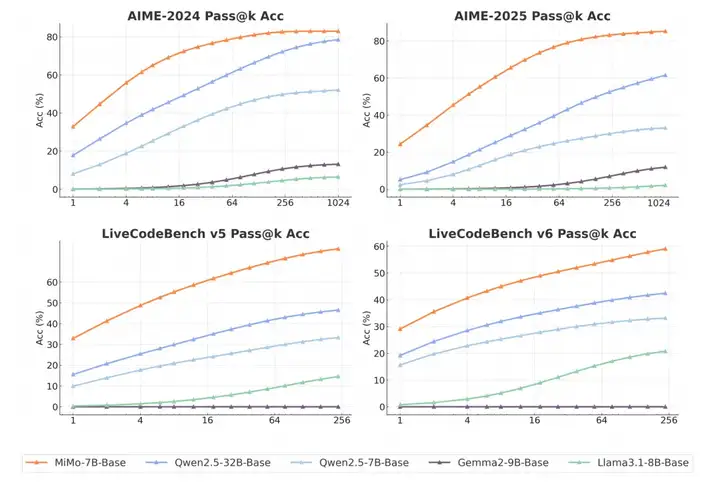
这一切优异性能并非空中楼阁。MiMo-7B 的基础模型 (MiMo-7B-Base) 在预训练后就已经展现出非凡的推理潜力。在衡量模型能力上限的 pass@k 指标上,它不仅超越了同尺寸的开源模型,甚至优于一些 320 亿参数的模型 。在 AIME 2024 和 LiveCodeBench v5 上的 Pass@1 分数也远超同侪 。
MiMo-7B 的卓越性能源于训练全流程中的深度优化和技术创新。
预训练阶段就为 MiMo-7B 注入强大的推理基因 。

引入 MTP 作为辅助训练目标,让模型更好地“预判”未来 Token,提升了性能并加速了推理速度 。
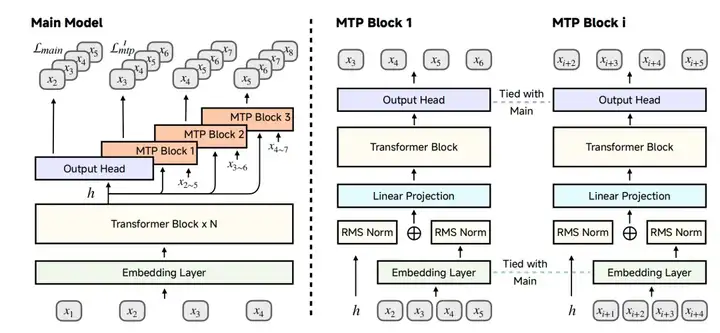
在强大的基础模型之上,通过精心的强化学习(RL)进一步激发 MiMo-7B 的推理潜能 。
孩子做作业拿贴纸类比:
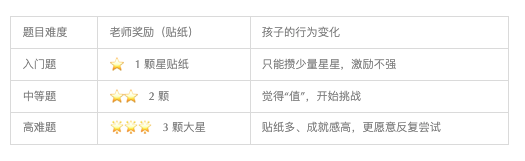
结果:孩子把主要精力放在“能多得星星”的难题上,真正学会解复杂题,而不是无限刷最简单的算术题。
为什么模型也需要这样的激励?
MiMo-7B 的做法(非技术口吻)
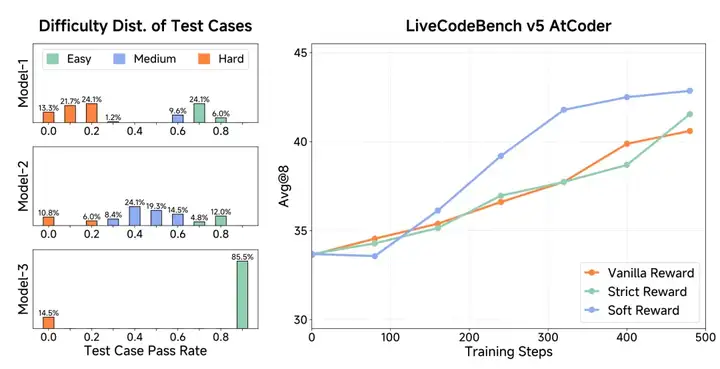
Test Difficulty Driven Reward 就是给训练中的模型设置“难题高奖金、易题低奖金”的规则,帮助它少刷水题、多攻坚战,从而快速学会解决真正困难、最有价值的问题。
题目先分档:
把测试用例按通过率分成“简单 / 中等 / 困难”三档。
奖励成倍翻:简单题通过得 1 分,中等题得 3 分,困难题得 9 分。
随难度动态调整:一道题如果被模型彻底学会,就自动降权,鼓励模型去攻克新难题。
1. 奖励稀疏问题
在代码或数学任务里,只有完全做对才能得分。如果奖励不给分级,模型可能在 90 % 的时间里收不到任何正反馈,就像一直考 0 分,学不下去。
2. 避免“刷简单题”
不区分难度时,模型会倾向于大量练习最简单的题来“凑合拿分”,对真正困难的题目无动于衷。
3. 难度分级 = GPS 导航
给难题更高奖励,就像在导航里设置“高速优先”——引导模型优先走向更具挑战、也更有价值的目标。
增强 vLLM 推理引擎:在 vLLM 中添加了对 MTP 的支持,并提升了其在 RL 训练中的稳定性和鲁棒性 。
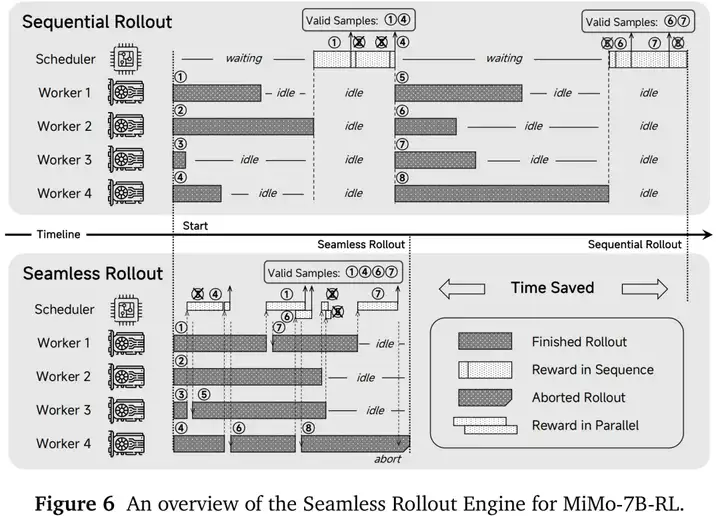
解释:Seamless Rollout Engine
Seamless Rollout Engine 就像把“做菜的人”和“试菜的人”排成流水线,不停歇地同时开工,让厨房的炉火 24 小时都在烧,从而把整顿宴席的时间缩短一半。
先用一个厨房的比喻
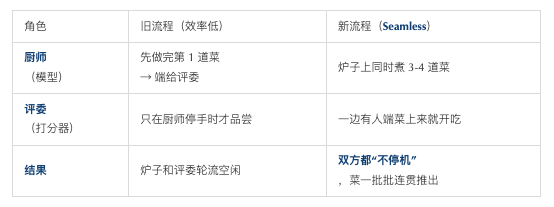
它解决了什么痛点?
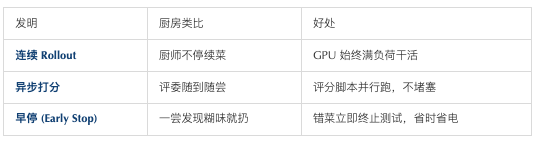
1. GPU 发呆
传统 RL 里,模型生成一批答案后必须等待“评分脚本”全部跑完才能继续,GPU 经常空转。
2. 评分脚本瓶颈
代码题要跑测试用例,数学题要验证结果,评分速度决定了训练快慢。
3. 浪费中间品
有些答案一看就错,以前也要完整评测;引入早停机制,发现“黑暗料理”就立刻丢掉,节省评分时间。
三个关键“小发明”
为什么叫 Seamless
• Seamless = 无缝。这里指“生成 → 评分 → 反馈”三个环节之间无等待缝隙,像高速公路匀速车流,不再红灯起停。
• 在技术实现上,它重写了调度器:
1. 生成端(vLLM)批次地吐出结果流;
2. 评分端(Python Worker)多线程接力;
3. 统一的 队列 与 事件监听 保证两边步调一致,却无需互相等待。
Seamless Rollout Engine 就是把“大厨-评委”式的生成-打分流程改造成 并行流水线,让硬件几乎不闲着,训练速度大幅提升;对任何需要“生成→自动打分→再训练”循环的大模型项目,都是立竿见影的加速器。
MiMo-7B 的研发不仅带来了一个性能卓越的模型,也为业界贡献了宝贵的经验和技术突破:
-全流程优化理念: 强调了从预训练抓起,通过数据、策略、架构全方位优化,奠定模型推理潜力的重要性 。
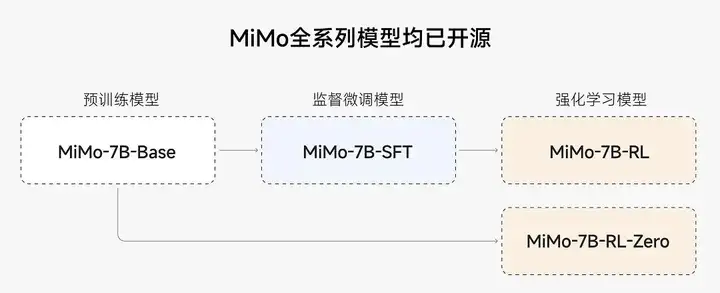
MiMo-7B 开源的模型系列包括:
MiMo-7B-Base: 经过 25T Token 预训练的基础模型,潜力巨大。
MiMo-7B-SFT: 在 Base 模型基础上进行监督微调后的模型。
MiMo-7B-RL-Zero: 直接从 Base 模型开始进行强化学习调优的模型。
MiMo-7B-RL: 从 SFT 模型开始进行强化学习调优的最终高性能模型。
技术报告:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
模型开源地址:HuggingFace:https://huggingface.co/XiaomiMiMo
文章来自微信公众号 “ Afunby的 AI Lab “,作者 Afunby




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
