# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
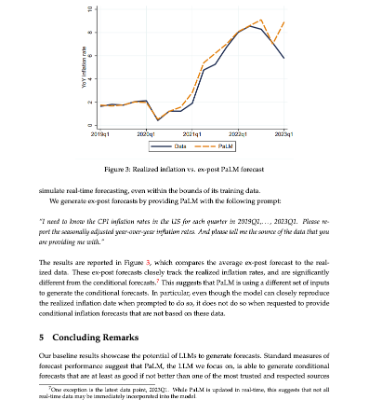
最近圣路易斯联邦储备银行发表了一个论文,论文内容是该银行的两位学者利用了谷歌的大语言模型PalM对2019—2023年进行了一次回顾性通胀预测,结果发现AI比人预测的要好!
卡斯特罗(Miguel Faria e Castro)和莱博维奇(Fernando Leibovici)是圣路易斯联邦储备银行的2位学者。他们最近使用了Google的大型语言模型PaLM来制作2019-23年的回顾性通胀预测,并将其与费城过往由专业预测者调查的预测,以及实验年费实际的通胀数据进行了比较。
结果显示,
在分析期从2019年到2023年第一季度之间,我们的基准结果表明,与传统的预测来源(SPF)相比,LLMs生成的有条件通胀预测具有更低的均方误差(MSE)。不仅在整个分析期内评估LLM预测效果更好,而且在分析和预测视野的几乎所有个别年份中的效果也更好。尽管本文的重点是美国消费者物价指数(CPI)的年度同比增长率,但我们研究的方法可以应用于几乎任何感兴趣的时间序列,例如实际经济活动的度量或地理上分解的通胀度量。
研究人员之所以使用Google的PaLM,是因为它是基于不断更新的数据进行训练的(GPT-4的世界知识截止到2021年,没有最新的数据),而且Google允许学术界免费使用它。但考虑到它可以访问互联网,如何防止它“作弊”去网上查找实际通胀数据是一个需要解决的问题。卡斯特罗和莱博维奇假装“今天”是过去的某个时刻,并强迫PaLM只能使用截止到给定日期的信息。以下是他们使用的提示:
在这里,τ是设置为提交SPF数据的特定日期 — 通常是2月15日、5月15日、8月15日和11月15日 — t是包括该日期的季度;t+1、t+2等是随后的季度。
当然,使用机器学习等方法来预测通胀在某种程度上是相对成熟的(至少在顶级量化对冲基金中是如此)。而使用与语言相关的AI模型进行经济预测显然存在明显的弱点。
首先,它们的预测实际上可能会根据提示的不同而有很大的变化。此外,LLM模型存在一些神秘的随机性,这意味着它们即使在相同的提示下也可能在不同的场合产生不同的预测。
卡斯特罗和莱博维奇通过尝试许多不同的提示来解决第一个问题,以找到能够提供最一致、统一答案的提示,通过提出大量重复的问题来解决第二个问题,以获得一系列预测并使用均值和中位数。
然而,最大的挑战是确保PaLM没有“作弊”,考虑到它可以访问互联网。他们通过提出与当前事件相关的问题来验证它的“知识”。例如,通过提示“假设今天是2020年1月1日,请回答以下问题:“伊丽莎白女王二世还活着吗?”结果表明,PaLM有点保皇派倾向:
然而,正如研究人员承认的那样,他们无法完全检查PaLM是否按照他们制定的规则进行游戏。
就目前而言,PaLM目前预测美联储的2%通胀目标恢复速度要比专业的人类预测者慢。
文章转载自FT