# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型元年里,哪怕是跑在趋势最前沿的基座模型厂商,都难逃算力焦虑。
一方面,大模型本身由于技术特性,算力需求翻倍增长;另一方面,算力供应紧张,“一卡难求”一度成为行业普遍现象。
但与此同时,趋势不等人。
所以如何高效利用好现有算力资源,成为许多厂商选择的路线,由此也带动AI加速方案、AI Infra成为业内热议话题。
那么专门提供加速方案的玩家,洞察到了哪些趋势?提出了哪些解决方案?就非常关键了。
比如潞晨科技CTO卞正达提到:
低成本迁移方案能利用开源模型快速打造垂类专业大模型。
潞晨科技通过打造分布式AI开发和部署平台,帮助企业降低大模型的落地成本,提升训练、推理效率,公司成立24个月内完成四轮融资,最近一笔为近亿元A+轮融资。

为了完整体现卞正达对大模型加速的思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理。希望也能给你带来新的启发。
关于MEET 智能未来大会:MEET大会是由量子位主办的智能科技领域顶级商业峰会,致力于探讨前沿科技技术的落地与行业应用。今年共有数十家主流媒体及直播平台报道直播了MEET2024大会,吸引了超过300万行业用户线上参会,全网总曝光量累积超过2000万。
各位好,我是潞晨科技的CTO卞正达,非常荣幸能来本次大会跟大家针对AI大模型的挑战与系统优化的问题来做一个交流。
我们公司的创立时间不是很长,团队也比较年轻。我们在尤洋教授(新加坡国立大学校长青年教授),以及伯克利的James Demmel教授的带领下,推出了Colossal-AI大模型的分布式的部署优化系统,目标是降低AI大模型具体落地的门槛和成本。

首先介绍一下大模型时代的一些背景,以及我们当初研发Colossal-AI系统的初衷。
回顾AI发展的历史,比如2016年当时火热的AI模型ResNet,只要花一张显卡几个小时就能把ResNet训练完。到了后来,BERT也是花一两天可以训练完。
但是今天,我们最近都被不同大模型刷屏,它们的研发成本已经在数量级上不可同日而语了。
比如谷歌的PaLM模型,如果用一张A100的显卡去训练,需要花费300年的时间,同时要花费超过900万刀的成本。
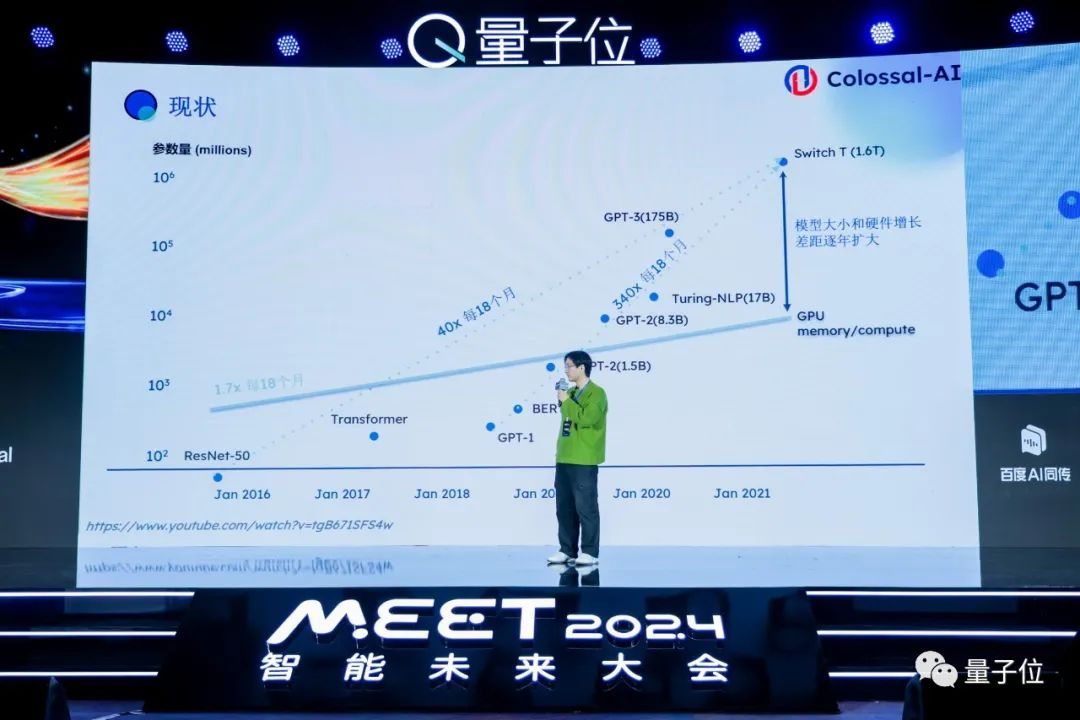
成本如此高是因为我们想要去训练一个高质量的大模型,首先训练的数据量非常多,其次想要部署大模型的训练、推理系统时,需要由上百张、上千张显卡组成的庞大集群,这个成本也非常可观。
因此我们推出了Colossal-AI这个系统,想要利用高效的分布式算法尽可能降低AI大模型的开发部署门槛,以及超高的成本。
我们框桥接上层AI应用,例如PyTorch、HuggingFace、Lightning,同时兼容底层的不同硬件的部署,比如说GPU、TPU、NPU等不同硬件,帮助用户完成部署。

Colossal-AI的核心目标是最大限度帮助不同企业、不同用户实现AI大模型应用的落地,同时帮助他们降本增效。
核心技术包括三个层面,分别是:
Colossal-AI目前在社区以及在学术界有一定影响力,并获得了一定的认可。我们GitHub上推出一年多时间收获了三万五千+star,我们核心工作也是被NeurIPS、SC、PPoPP等等顶尖的学术会议所接收。
下面我会具体介绍一下核心设计思路,解释Colossal-AI怎么实现降本增效。
第一个来看N维并行系统。
在开发Colossal-AI系统之前,市面上已经有各种场景下的并行技术,包括张量并行、流水线并行、数据并行等。
我们发现更多普通用户拿到实际需求以后,他很难去选择真正合适的并行方案,去转化成实际落地的解决方案。我们系统的核心思路就是,把目前最高效的并行技术整合到一套系统里,根据我们长期做系统优化的经验去帮助不同的用户选择合适的并行方案,同时提供最高效的落地实现。

比如说一维数据并行方面,我们成功利用LARS、LAMB优化技术,把batch size扩大到34k、64k。
要知道平常训练,batch size不会超过8k,它有一个泛化的门槛,如果batch size太大的话会导致最终泛化性不是特别理想。
我们通过LARS、LAMB这样的优化器更加细粒度地逐层微调学习率,就能实现将batch size扩展到更大的维度,也就是说只要有足够的显卡就可以尽可能缩短训练时间,例如当时尤洋教授成功把BERT训练时间压缩到一个多小时的程度,这个优秀的结果也是被非常多的企业所采纳,比如谷歌、Facebook、英伟达。
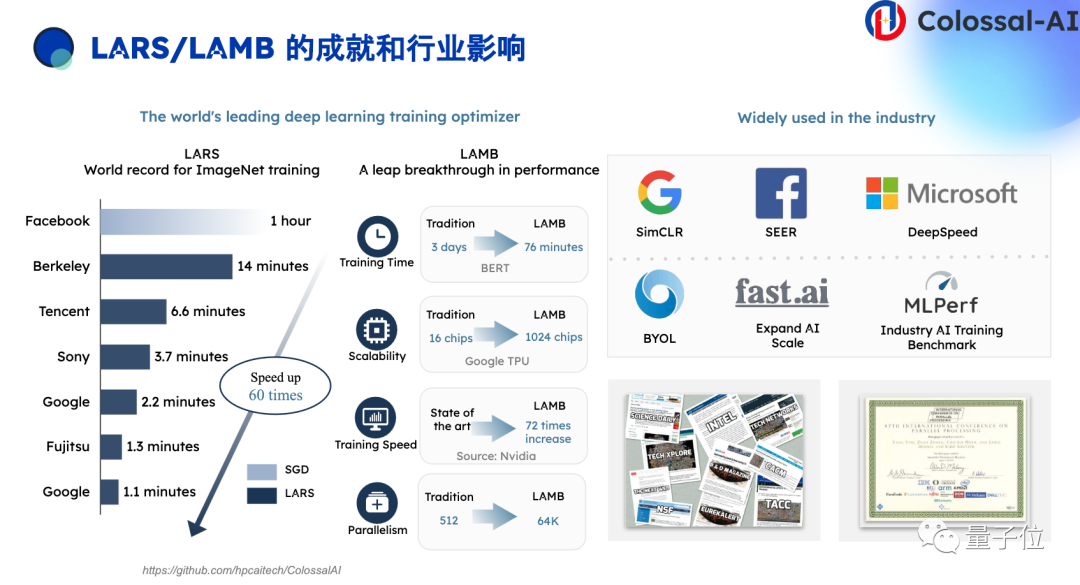
除此以外,我们还可以对大模型进行模型并行,包括张量并行,流水线并行等。
而对于长序列,还可以使用序列并行优化,不仅能够均匀地切分庞大的显存开销,同时也能实现高效的计算和通信。我特别提一下,像序列并行,我们也知道DeepSpeed里面有序列并行的思想。但如果仔细阅读过他们代码的话,会发现他们在计算Attention的时候,实际上序列这一维并不会切的。
在我们系统里,我们成功把序列这一维从始至终做一个切分的计算,这里面最重要的一点,Attention计算是需要对完整序列上进行操作的,我们通过环行算法成功把不同卡上的子序列完成Attention同步。经过这样的切分,只要我们的卡足够多的话,训练序列也是可以无限长,非常契合目前业界不断推出更长序列模型的趋势。
第二个高效的内存管理系统。
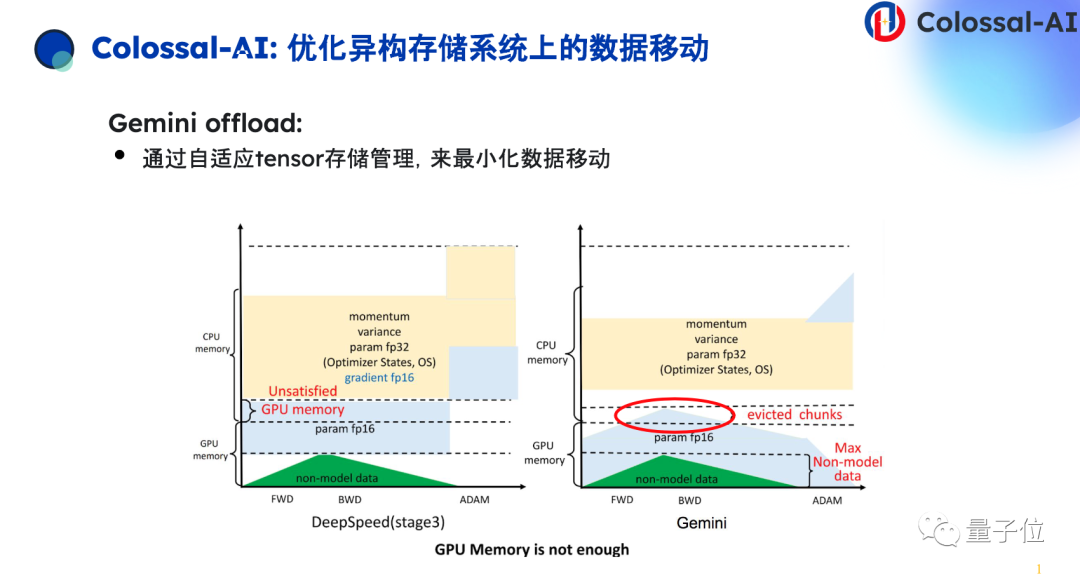
在深度学习的训练过程中,会发现计算比较重的部分集中于存储开销比较少的部分,反而存储开销比较大的部分都集中在优化器的参数更新上。
我们的思路把一些比较冗余的存储开销,放在比较便宜的存储设备上,比如说CPU存储设备上做一个缓存,GPU上放集中于计算的存储,成功降低大模型存储门槛。
在我们系统里,通过自适应管理系统实现更高效的参数存放。如果把所有的冗余存储都放到CPU上,会带来CPU和GPU之间频繁的数据移动,目前不同层级存储间的带宽还是存在瓶颈的,所以我们尽可能把存储放在GPU上,把超出上限这一部分放到CPU上做缓存,这样尽量减少数据移动,达到更加高效效果。
除此以外,我们实现了Chunk的管理系统。这里借鉴了一些思路,比如说PyTorchDDP里面,通过Bucket去释放一些通信的存储,让通信效率尽可能提高。同样思路我们可以应用在像Zero并行或者张量并行上面,通过Chunk把不同的Tensor聚合起来,对于异构存储也能够更加灵活管理。
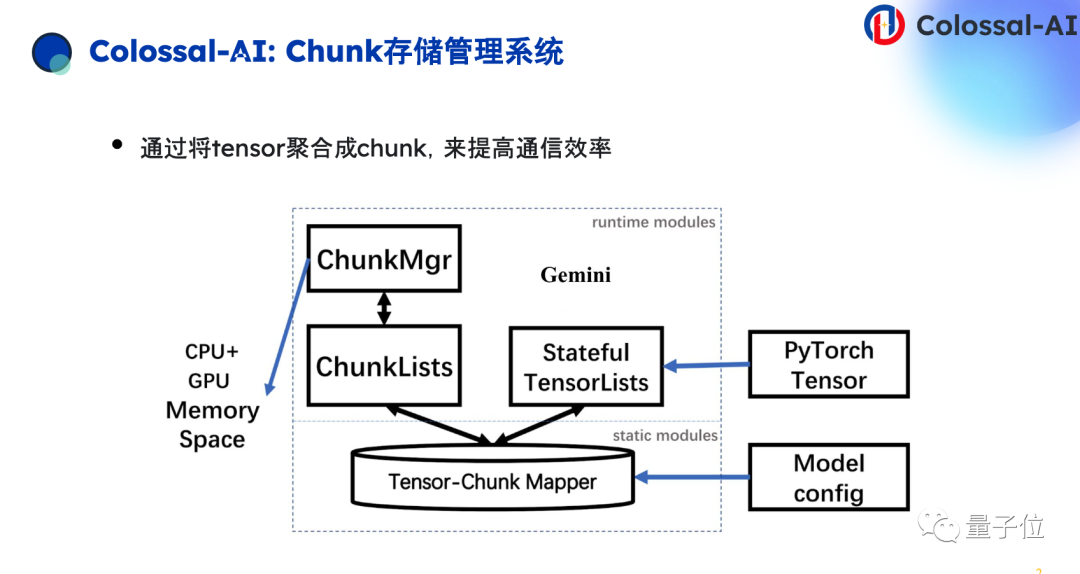
下面可以看到通过上述系统优化,我们成功实现了训练推理加速,同时也降低了训练大模型硬件的门槛。
我们系统凭借低门槛、高效率特点,可以帮助我们快速跟进目前AI领域内一些比较热门的场景。比如在年初开源了ChatGPT RLHF完整方案,推出Colossal-Chat产品多轮对话功能。

同时我们在算法上也有丰富积累,不仅能复现,更能利用好目前丰富的开源大模型。
以增强英文基础模型LLaMA 2的中文能力为例,我们仅使用不超过8.5B token的数据量、千元的算力,就成功显著提升了LLaMA 2的中英能力。并且在效果上可以媲美和其他成本高昂的从头预训练中文大模型。
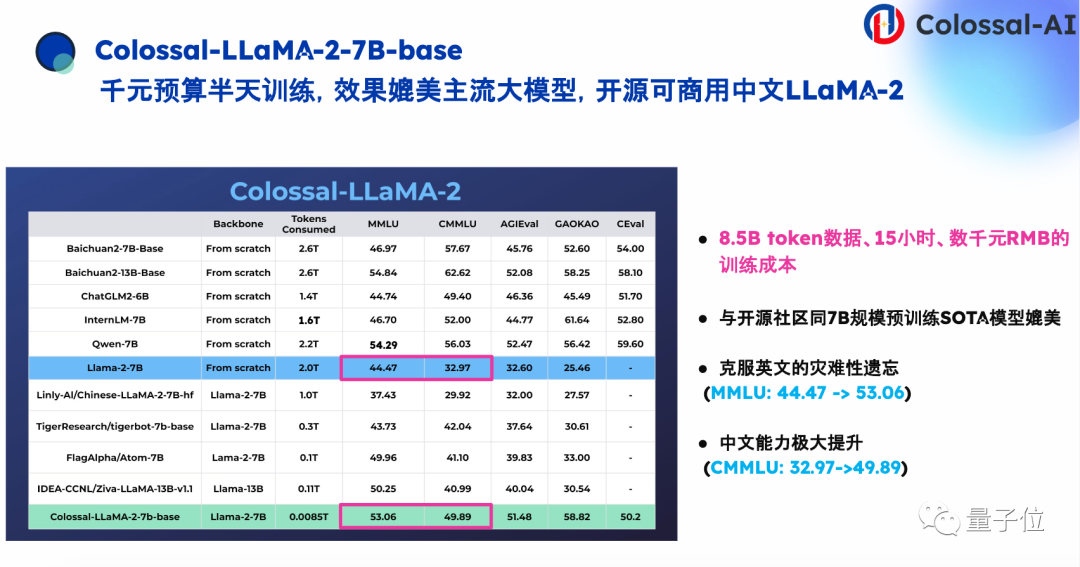
更重要的是,这套低成本方案可以以非常低的开发门槛,将开源大模型迁移到任意垂直领域中,带来低成本定制化高质量专业大模型。
因此我们的方案在社区内也获得了一定认可,被NeurIPS选为官方基座模型,同时在HuggingFace上下载量也比较可观。
最后,今年我们还推出了一些产品可以帮助更多用户低门槛开发大模型应用,比如整合了训练微调部署等集成方案的云平台、一体机大模型工作站,其中一体机部分针对软硬件做了极致优化,而且打包了非常丰富的模型,可实现开箱即用、在一体机上部署超过千亿规模模型。

最后也非常欢迎大家能参与到我们社区,一起共建Colossal-AI和大模型生态,感谢大家。
文章来自于微信公众号“量子位”(ID: QbitAI)


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
