# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去短短两年内,随着诸如 LAION-5B 等大规模图文数据集的开放,Stable Diffusion、DALL-E 2、ControlNet、Composer ,效果惊人的图片生成方法层出不穷。图片生成领域可谓狂飙突进。
然而,与图片生成相比,视频生成仍存在巨大挑战。首先,视频生成需要处理更高维度的数据,考虑额外时间维度带来的时序建模问题,因此需要更多的视频 - 文本对数据来驱动时序动态的学习。然而,对视频进行准确的时序标注非常昂贵。这限制了视频 - 文本数据集的规模,如现有 WebVid10M 视频数据集包含 10.7M 视频 - 文本对,与 LAION-5B 图片数据集在数据规模上相差甚远,严重制约了视频生成模型规模化的扩展。
为解决上述问题,华中科技大学、阿里巴巴集团、浙江大学和蚂蚁集团联合研究团队于近期发布了 TF-T2V 视频方案:

论文地址:https://arxiv.org/abs/2312.15770
项目主页:https://tf-t2v.github.io/
即将开源代码地址:https://github.com/ali-vilab/i2vgen-xl (VGen 项目)
该方案另辟蹊径,提出了基于大规模无文本标注视频数据进行视频生成,能够学习丰富的运动动态。
先来看看 TF-T2V 的视频生成效果:
文生视频任务
提示词:生成在冰雪覆盖的土地上有一只冰霜般的大生物的视频。

提示词:生成一只卡通蜜蜂的动画视频。

提示词:生成包含一辆未来幻想摩托车的视频。

提示词:生成一个小男孩快乐微笑的视频。

提示词:生成一个老人感觉头疼的视频。

组合式视频生成任务
给定文本与深度图或者文本与素描草图,TF-T2V 能够进行可控的视频生成:
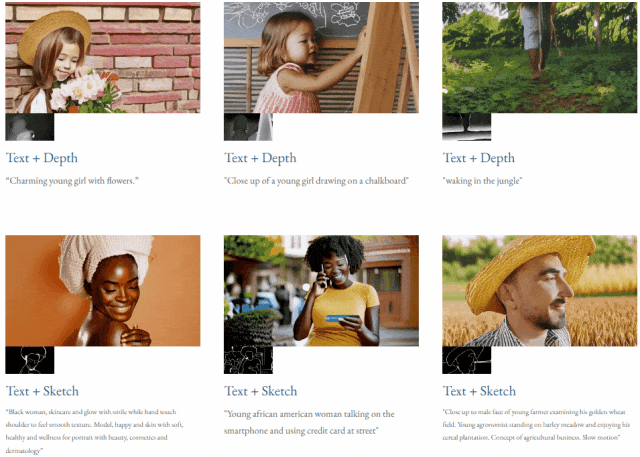
也可以进行高分辨率视频合成:
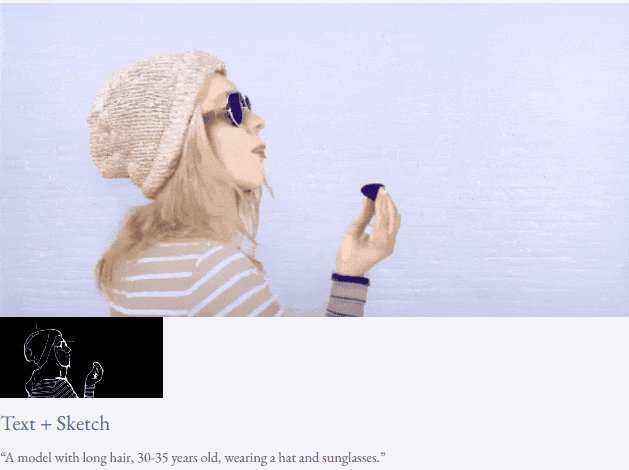
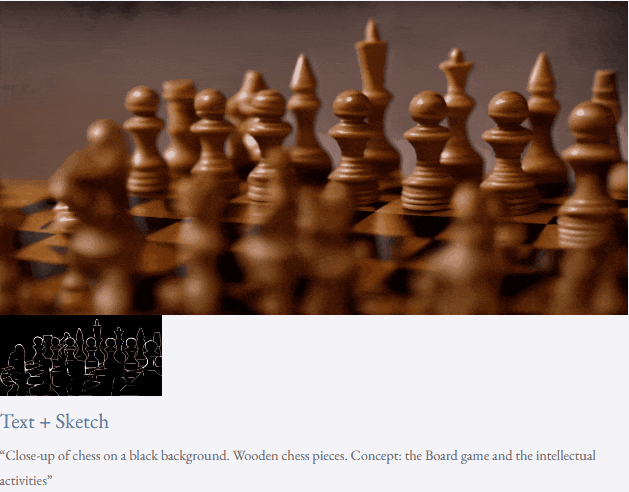
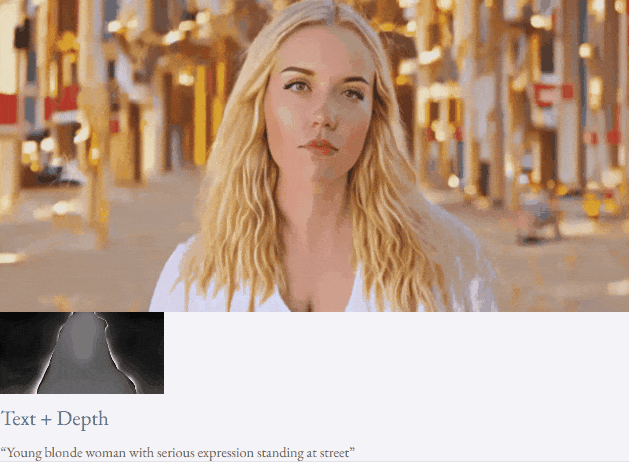
半监督设定
在半监督设定下的 TF-T2V 方法还可以生成符合运动文本描述的视频,如 「人从右往左跑」。


TF-T2V 的核心思想是将模型分为运动分支和表观分支,运动分支用于建模运动动态,表观分支用于学习视觉表观信息。这两个分支进行联合训练,最终可以实现通过文本驱动视频生成。
为了提升生成视频的时序一致性,作者团队还提出了一种时序一致性损失,显式地学习视频帧之间的连续性。
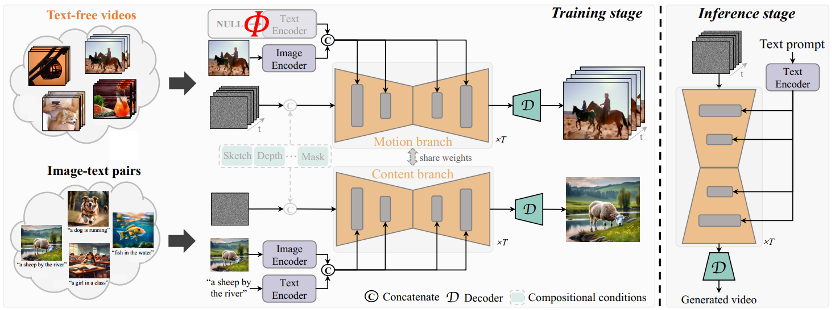
值得一提的是,TF-T2V 是一种通用的框架,不仅适用于文生视频任务,还能应用于组合式视频生成任务,如 sketch-to-video、video inpainting、first frame-to-video 等。
具体细节和更多实验结果可以参考原论文或者项目主页。
此外,作者团队还把 TF-T2V 作为教师模型,利用一致性蒸馏技术得到了 VideoLCM 模型:

论文地址:https://arxiv.org/abs/2312.09109
项目主页:https://tf-t2v.github.io/
即将开源代码地址:https://github.com/ali-vilab/i2vgen-xl (VGen 项目)
不同于之前视频生成方法需要大约 50 步 DDIM 去噪步骤,基于 TF-T2V 的 VideoLCM 方法可以只需要进行大约 4 步推理去噪就生成高保真的视频,极大地提升了视频生成的效率。
一起来看看 VideoLCM 进行 4 步去噪推理的结果:


具体细节和更多实验结果可以参考 VideoLCM 原论文或者项目主页。
总而言之,TF-T2V 方案为视频生成领域带来了新思路,克服了数据集规模和标注难题带来的挑战。利用大规模的无文本标注视频数据,TF-T2V 能够生成高质量的视频,并应用于多种视频生成任务。这一创新将推动视频生成技术的发展,为各行各业带来更广阔的应用场景和商业机会。
文章来自于微信公众号 “机器之心”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
