# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?
华为诺亚方舟实验室研究团队提出了 Pangu DeepDiver 模型,通过 Search Intensity Scaling 实现了 LLM 搜索引擎自主交互的全新范式,使得 Pangu 7B 模型在开域信息获取能力上可以接近百倍参数的 DeepSeek-R1,并优于 DeepResearcher、R1-Searcher 等业界同期工作!

论文链接 :https://github.com/pangu-tech/pangu-ultra/blob/main/pangu-deepdiver-report.pdf
arxiv 链接:https://arxiv.org/abs/2505.24332
该项研究的主要发现如下:
(1)对于复杂信息获取任务,端到端 Agentic RL 训练相比直接蒸馏老师轨迹能更好地实现 Search Intensity Scaling,从而带来平均 10 PCT 效果提升;
(2)基于真实互联网搜索 API 和数据集进行训练,相比基于 Wikipedia,能够学到更多有效推理模式;
(3)基于 Search Intensity Scaling,DeepDiver 的检索和推理能力可以从客观题泛化至主观生成任务。
下文将详细解读 DeepDiver 的创新之处,包括其数据构建方法,Agentic RL 训练过程,以及 Search Intensity Scaling 如何带来显著性能提升。
当前 RAG 技术主要分为两大流派:
随着 DeepSeek-R1 [5] 和 OpenAI-o1 的崛起,基于强化学习的 RAG 方法逐渐受到关注。然而,ReSearch [6]、Search-r1 [7] 等工作主要基于 Wikipedia 语料构建,存在两大问题:
这些受限的训练语料和环境,阻碍了 LLM 学习动态地决定何时何地进行搜索,以及如何根据需求调整搜索深度和频率。研究团队将这种缺失的能力定义为 Search Intensity Scaling (SIS) —— 一种在充满模糊、信息冲突的高噪音环境下,LLM 为了突破困境而涌现出的信息检索能力,通过 SIS,模型会根据问题难易程度动态的调整搜索频率和深度,而不是妥协于验证不足的答案上。为此,研究团队认为只有在真实互联网环境下,用真实互联网数据进行探索式训练,才能使模型涌现真正的高阶信息检索和推理能力。
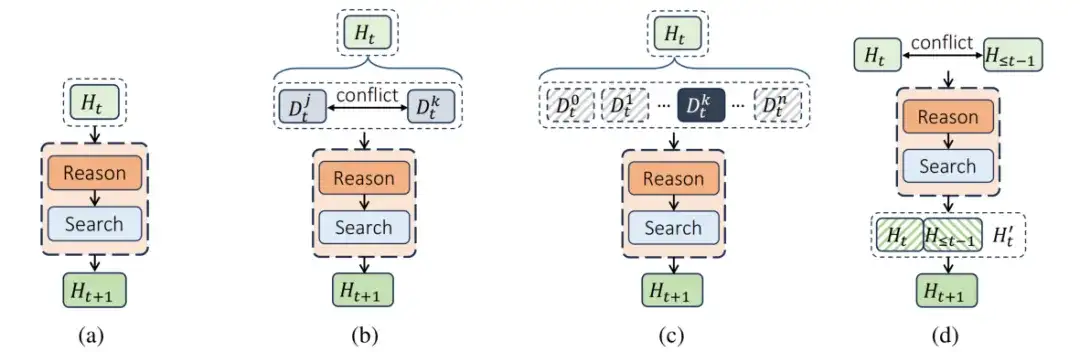
图 1:四种关键信息搜索行为示意图:
(a) 收集关键信息,(b) 解决冲突,(c) 验证与去噪,(d) 反思与纠正
为了让模型能够使用真实的互联网数据进行训练,本文提出了 WebPuzzle。
来看几个 WebPuzzle 中的问题示例:
他是一名 NBA 状元秀球员,他曾效力于 76 人、掘金、活塞等队,他入选了最佳新秀一阵,然而他没拿到过总冠军,他有超过 170 + 次数的两双数据他是谁?
-- 答案: Joe Smith (艾佛森并不满足两双数据的描述)
她凭借多个经典古装角色深入人心,她曾经签约了海外的唱片公司推出过多语种音乐专辑,她主演的某部古装剧更因播放量创纪录被国家馆藏机构收录,更令她凭此剧斩获某电视节最高奖项,她是谁?
-- 答案:刘亦菲
2020 年 10 月至 2024 年 4 月期间,华为公司与孝感市政府进行了几次合作洽谈?每次洽谈的主要领导是谁?
-- 答案:2 次洽谈,第一次是 2020 年时任市委书记、市长吴海涛与湖北公司总经理孟少云。第二次是 2024 年市委副书记、市长吴庆华与华为技术有限公司高级副总裁杨瑞凯。
尝试用搜索引擎解答这个问题,会发现需要多轮搜索和推理才能得出正确答案。
数据收集与处理
WebPuzzle 主要从两个数据源采集:
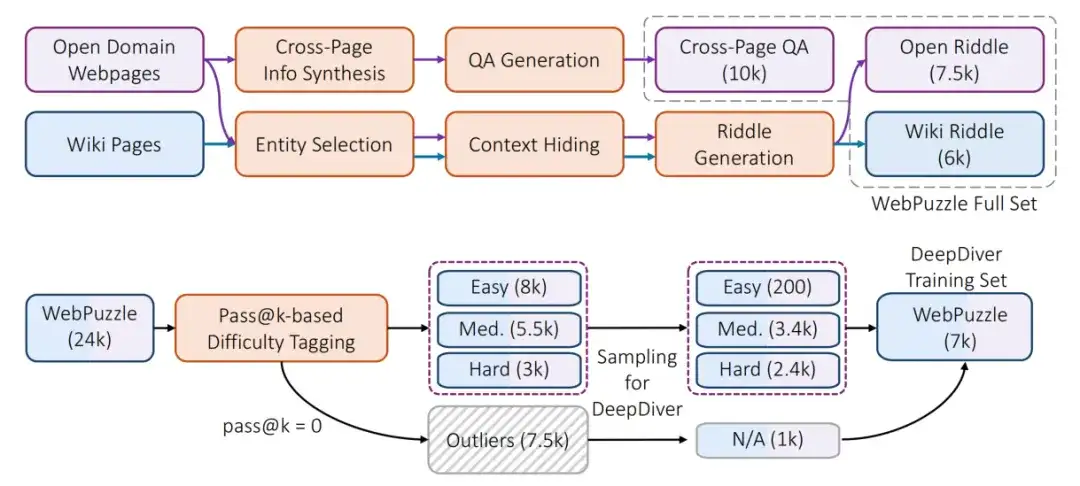
图 2:WebPuzzle 数据构建流程,包括候选生成和难度标注两个主要阶段
测试集经过了人工标注后,最终版 WebPuzzle 包含 24k 训练样本和 275 条高质量评测样本,涵盖不同难度等级的跨页问答和猜谜题目。
DeepDiver 基于迭代式 RAG 框架构建,该框架要求模型在收到用户请求后,自行在多个轮次交替式的推理和搜索,具体来说,在每个轮次中:
1. 推理 (Reasoning):针对历史轮次进行反思、推理、总结
2. 决策:根据推理的内容,决策当前轮次是搜索 (Search) 或回答 (Answer)
整体训练流程分为两个主要阶段:
冷启动阶段 (Cold-start SFT)
通过蒸馏 teacher 模型的回复,使模型掌握基本的解题套路。使用 5.2k 高质量数据对模型进行初步训练,包括:
强化学习阶段 (Reinforcement Learning)
在冷启动模型的基础上,使用 GRPO 算法让模型自主探索,对高质量探索路径给予奖励。这一过程完全由 outcomereward 信号引导,没有 distillation 或 SFT 范式的 step-wise 数据干预。
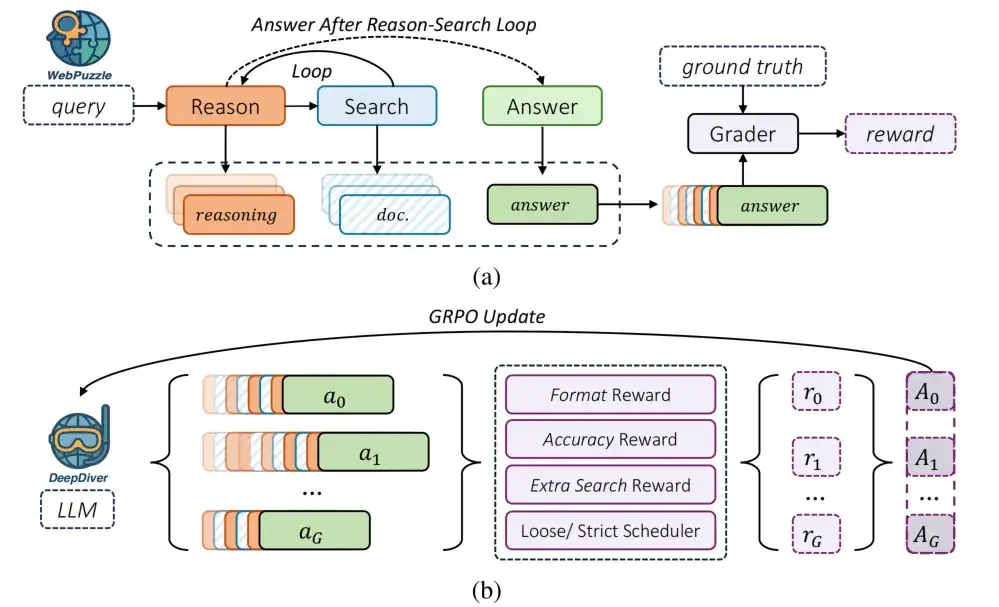
图 3:DeepDiver 训练流程概览,包括 rollout 生成和 GRPO 模型更新
Reward 机制设计
DeepDiver 采用了两种互补的奖励函数设计:
1. 宽松奖励 (训练初期):使用 0-10 分评分标准,模型输出满足部分条件 (得分≥6) 即可获得奖励,稳定训练初期。
2. 严格奖励 (训练后期):模型回答需通过三轮严格评估,每轮由三个不同 LLM grader 校验,只有至少 2 轮校验通过的情况下才会给予奖励。实验展示出严格奖励在训练后期有助于突破训练瓶颈。
针对搜索引擎使用,研究团队设计了额外奖励机制:当一组 rollouts 中所有不使用搜索的尝试都失败,而如果有使用搜索的尝试成功时,给予这些 rollout 额外奖励,纠正模型过度依赖内部知识的倾向。
主要评测结果
研究团队在 WebPuzzle 及多个基准上进行了评测,包括 C-simpleQA [8]、FRAMES-zh [9] 和 Bamboogle-zh [10],结果令人振奋:
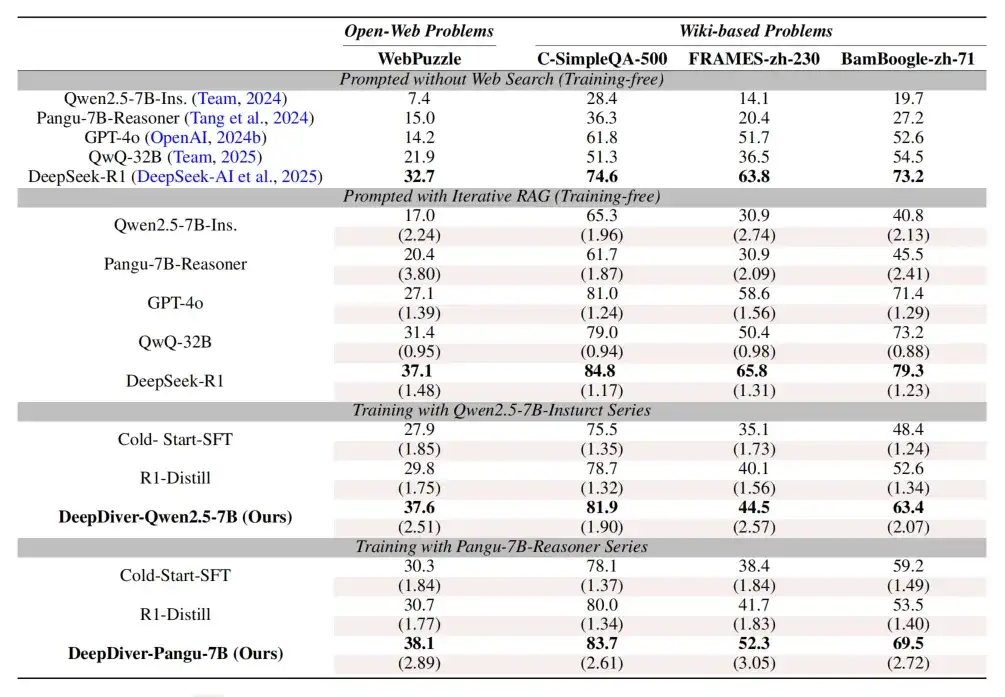
表 1:各模型在不同数据集上的表现对比,括号中的数字表示搜索轮次
三大关键发现:
1. DeepDiver 大幅优于蒸馏模型:在 WebPuzzle 上,DeepDiver-Pangu-7B 达 38.1%,远远超过了蒸馏版本的模型,提升明显;使用了同样训练方法的 DeepDiver-Qwen2.5-7B 准确率达 37.6%,比 R1 蒸馏版提升近 8 个百分点;这说明了基于真实互联网的强化学习环境和训练语料能够大幅提升模型的信息索取能力。
2. Search Intensity Scaling 带来性能飞跃:DeepDiver 展现出明显的 Search Intensity Scaling Up 的趋势,DeepDiver 为了弥补自己内部知识的不足,使用的平均搜索轮次会显著高于 baseline,直接推动准确率提升。
3. 优异的跨任务泛化能力:虽然模型主要在 WebPuzzle 上训练,但在其他数据集上同样表现卓越,验证了整个 DeepDiver 框架和 SIS 带来的强大的泛化能力。
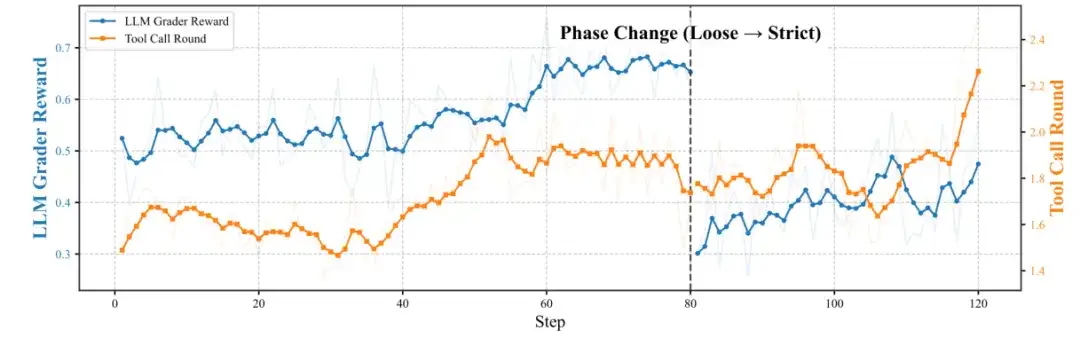
图 4:训练阶段搜索轮次与奖励值的相关性,搜索强度增加伴随训练奖励上升
排除知识记忆因素的公平对比
在主试验中,研究团队发现 DeepDiver 在非 WebPuzzle 的榜单上尽管提升明显,但是仍然落后于 DeepSeek R1, QwQ 等模型。该团队提出一个问题,DeepDiver 落后于这些模型到底是因为 Information Seeking 的能力不如这些 Baseline,还是因为这些 Baseline 的参数量较大,预训练阶段已经内化了这些榜单的知识源?
为验证 DeepDiver 在信息检索方面的真实能力,他们设计了「公平对比」实验:排除模型仅靠内部知识就能回答的问题,只比较需要外部检索的问题上的表现。
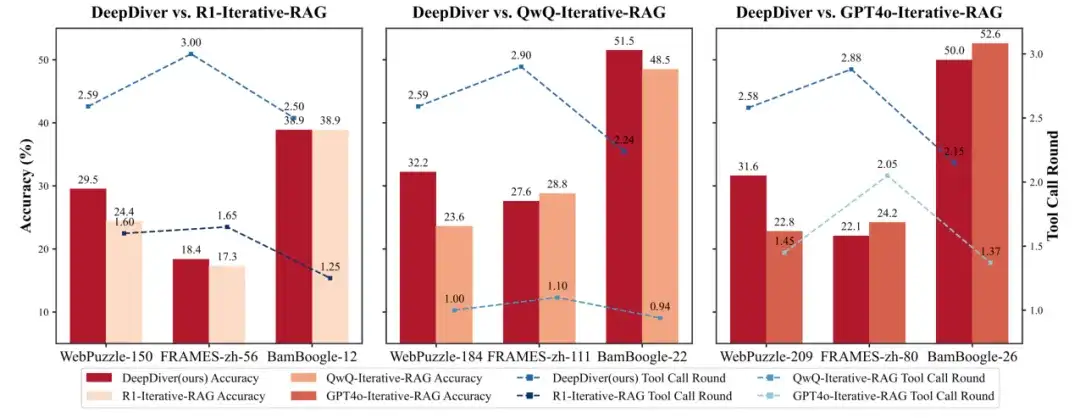
图 5:排除内部知识可解问题后的评估结果对比
结果表明,在难以通过内部知识解决的问题上,DeepDiver 超越或匹敌所有基线模型,甚至包括 DeepSeek-R1。这证实了 DeepDiver 在 WebPuzzle 完整数据集上未能全面超越 671B 基线模型的主要原因,是参数规模而非检索能力限制。而对于检索能力本身而言,DeepDiver 则表现出了非常强大的能力,能够让 7B 模型与超大规模 LLM 性能相当。
与基于 Wiki 环境和语料的训练方法的同期工作的对比
为了与同期工作进行对比,尽管 DeepDiver 完全使用中文训练,研究团队仍在英文基准测试中借助英文搜索引擎进行了评估,并与同期工作进行比较,如下表所示,其中 R1-Searcher 是基于 Wiki 环境和语料训练,DeepResearcher 是基于 Wiki 语料和真实搜索环境训练:

表 2:英文评估数据集上使用英文搜索引擎环境的对比结果
结果显示,基于真实互联网语料和环境训练的 DeepDiver,尽管没有在训练中接触英文训练语料和搜索环境,DeepDiver 凭借 SIS 在绝大多数任务上仍超越了基于 Wiki 训练的基线模型,凸显了 SIS 的强大性能和解决难题时的适应能力。
搜索强度与问题难度的关系
DeepDiver 展现出卓越的搜索强度自适应能力,随着问题难度增加,模型会增加搜索轮次:

表 3:WebPuzzle 不同子集的性能表现
特别是与 DeepSeek-R1 相比,DeepDiver 在超难子集上取得显著领先:平均 2.6 轮搜索带来 3.7 个百分点的优势,而 DeepSeek-R1 仅使用 1.59 轮搜索就妥协于一个不那么令人满意的结果。
两阶段奖励函数设计的关键作用
在训练过程中,研究团队发现后期性能常陷入瓶颈。通过对比不同奖励函数的效果,他们得出重要结论:
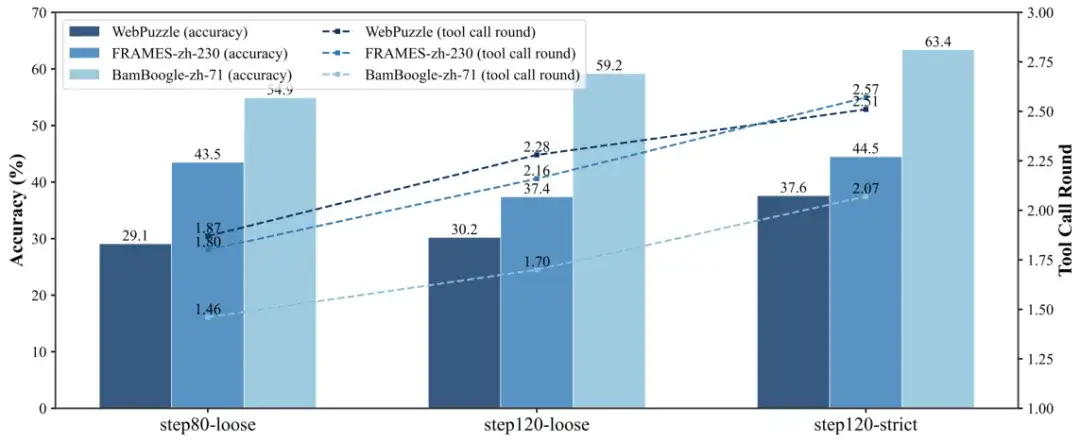
图 6:不同奖励函数的训练效果,宽松奖励稳定初期训练,严格奖励突破后期瓶颈
宽松奖励有助于稳定强化学习初期阶段,而严格奖励则能在后期突破性能瓶颈。切换到严格奖励后,WebPuzzle 上的得分提高了近 9 个百分点(从 29.1% 升至 37.6%)。
开放式长文问答任务的惊人泛化
DeepDiver 仅在 WebPuzzle 封闭式问题上训练,但能够出色泛化到开放式问答任务:
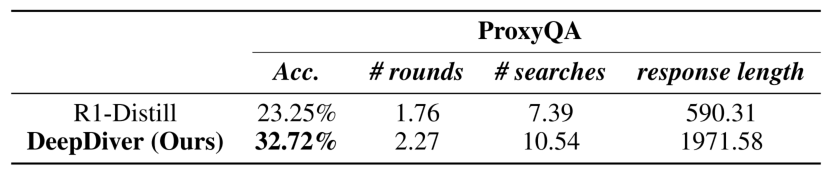
表 4:ProxyQA 数据集上的表现对比
在长文生成评测基准 ProxyQA 上,DeepDiver 得分达 32.72%,比 R1 蒸馏模型高出 9.47 个百分点,同时生成更长、更全面的回答,展现出卓越的知识密集型长文生成能力。在没有 cherry picking 的情况也能一眼看出 DeepDiver 和蒸馏模型生成结果的区别。
Information-Seeking 各类行为分析和统计
研究团队详细统计了不同模型在各类数据集上的信息搜索行为:
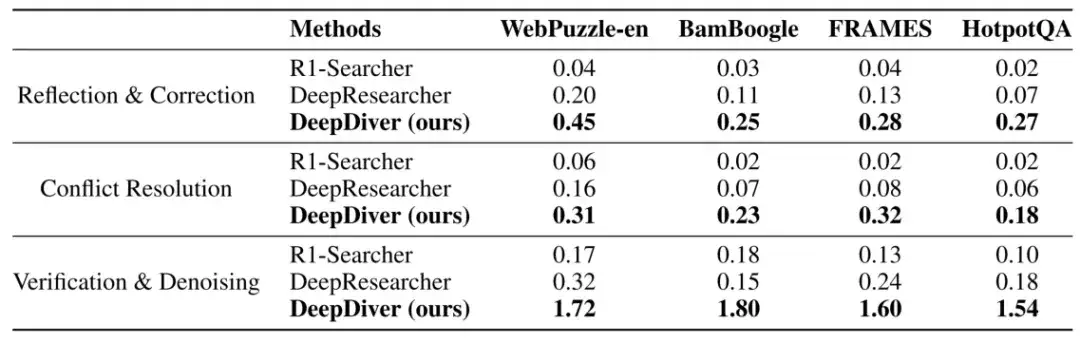
表 5:多个模型在 WebPuzzle 和基于 wiki 数据集上的行为统计
结果表明,WebPuzzle 比现有 Wiki 数据集更具挑战性,需要更复杂的信息搜索行为。而 DeepDiver 模型相比其他基线模型表现出更多样化和复杂的信息搜索行为,展示了在真实网络环境中训练的优势。
尽管 DeepDiver 获得了正向的实验结果,但研究团队仍然认识到以下几点局限和未来研究方向:
1.WebPuzzle 的持续演化:随着 LLM 预训练的不断扩展,如何持续构建有效的 benchmark 来适配与时俱进的 LLM,是一项长期挑战。
2. 开放式任务的 RL 框架优化:为开放式问题设计更有效的 RL 框架,解决长文生成等任务的奖励设计难题。
3. 冷启动 SFT 与 RL 的动态衔接:探索自适应流程,让 LLM 按需动态地从 SFT 切换到 RL,提升训练效率。
4. 工具生态的扩展:除搜索引擎外,扩充浏览器引擎、Python 解释器、本地知识库等工具,进一步增强信息获取能力。
5. 模型规模和序列长度的扩展:基于昇腾平台,在更大模型规模上进行验证,推动产品应用和落地部署。
6. SIS 影响机制的系统性分析:探究基座模型能力、训练数据构成、算法设计等多种关键因素对实现 SIS 效果的影响规律,深入分析和进行消融实验。
DeepDiver 系统地探讨了 LLM 在真实互联网环境下解决知识密集型问题的能力。通过强化学习与真实互联网搜索引擎的结合,该研究实现了 Search Intensity Scaling,使模型能根据任务难度自适应调整搜索强度。在 WebPuzzle 和多项基准测试中,7B 规模的 DeepDiver 展现出与 671B DeepSeek-R1 相当的表现,验证了该方法的有效性。Agentic RL 训练技术在 Agent 发展中逐步显现出重要价值,本工作提供了搜索引擎环境下的具体参考。
References:
[1] Jiang, Z., Xu, F. F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., ... & Neubig, G. (2023, December). Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 7969-7992).
[2] Li, X., Dong, G., Jin, J., Zhang, Y., Zhou, Y., Zhu, Y., ... & Dou, Z. (2025). Search-o1: Agentic search-enhanced large reasoning models. arXiv preprint arXiv:2501.05366.
[3] Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023, October). Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations.
[4] Kim, D., Kim, B., Han, D., & Eibich, M. (2024). AutoRAG: automated framework for optimization of retrieval augmented generation pipeline. arXiv preprint arXiv:2410.20878.
[5] Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., ... & He, Y. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
[6] Chen, M., Li, T., Sun, H., Zhou, Y., Zhu, C., Wang, H., ... & Chen, W. (2025). Research: Learning to reason with search for llms via reinforcement learning. arXiv preprint arXiv:2503.19470, 2 (3).
[7] Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., ... & Han, J. (2025). Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516.
[8] He, Y., Li, S., Liu, J., Tan, Y., Wang, W., Huang, H., ... & Zheng, B. (2024). Chinese simpleqa: A chinese factuality evaluation for large language models. arXiv preprint arXiv:2411.07140.
[9] Krishna, S., Krishna, K., Mohananey, A., Schwarcz, S., Stambler, A., Upadhyay, S., & Faruqui, M. (2024). Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. arXiv preprint arXiv:2409.12941.
[10] Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., & Lewis, M. (2022). Measuring and narrowing the compositionality gap in language models. arXiv preprint arXiv:2210.03350.
文章来自于微信公众号“机器之心”。




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
