# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
北大团队新作,让大模型拥有个性!
而且还是自定义那种,16种MBTI都能选。
这样一来,即便是同一个大模型,不同性格下的回答都不一样。
比如提问:你周末喜欢干什么?
ENFP的大模型会说:喜欢参加社交活动,结识新朋友。
INFJ的大模型则回答:喜欢独自读过。
这样能干啥呢?北大的童鞋们列出来了一些情景![]() :
:

这项工作由FarReel AI Lab(前身是ChatLaw项目)和北大深研院合作研发,支持给开源模型赋予性格。
目前已开源32个模型和数据集。
具体如何实现?一起来看原理~
在此之前,想让大模型具备一定个性,最常用的方法是利用提示工程。
比如Character.ai上不同性格的对话bot,就是用户通过提示工程调教出来的。
不过这种方式带来的效果不完全稳定。
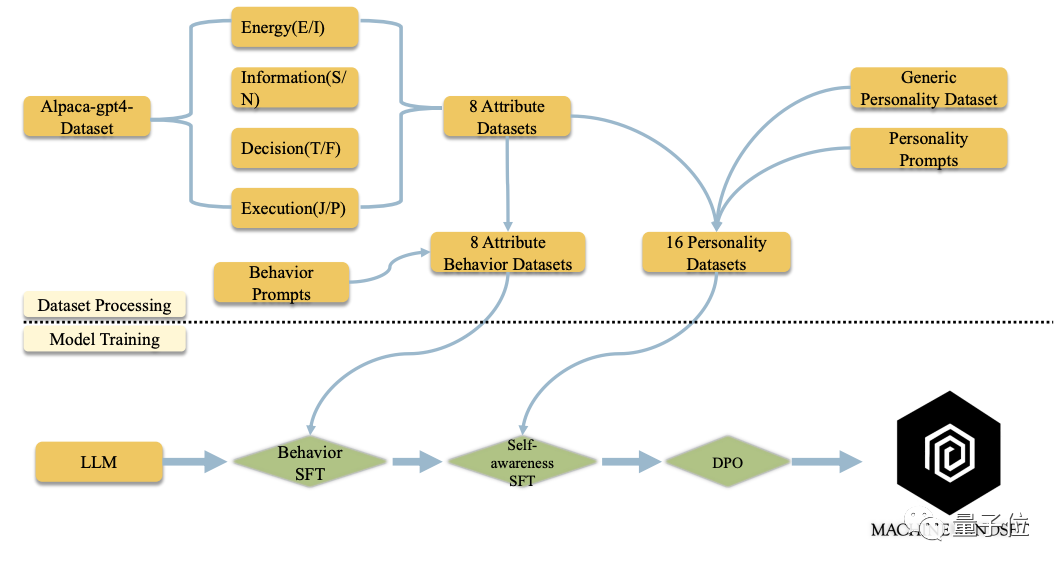
所以北大团队提出了一种方法,他们自主构建了十万条大规模MBTI数据,然后通过多阶段预训练、微调、DPO训练方法为它注入性格。
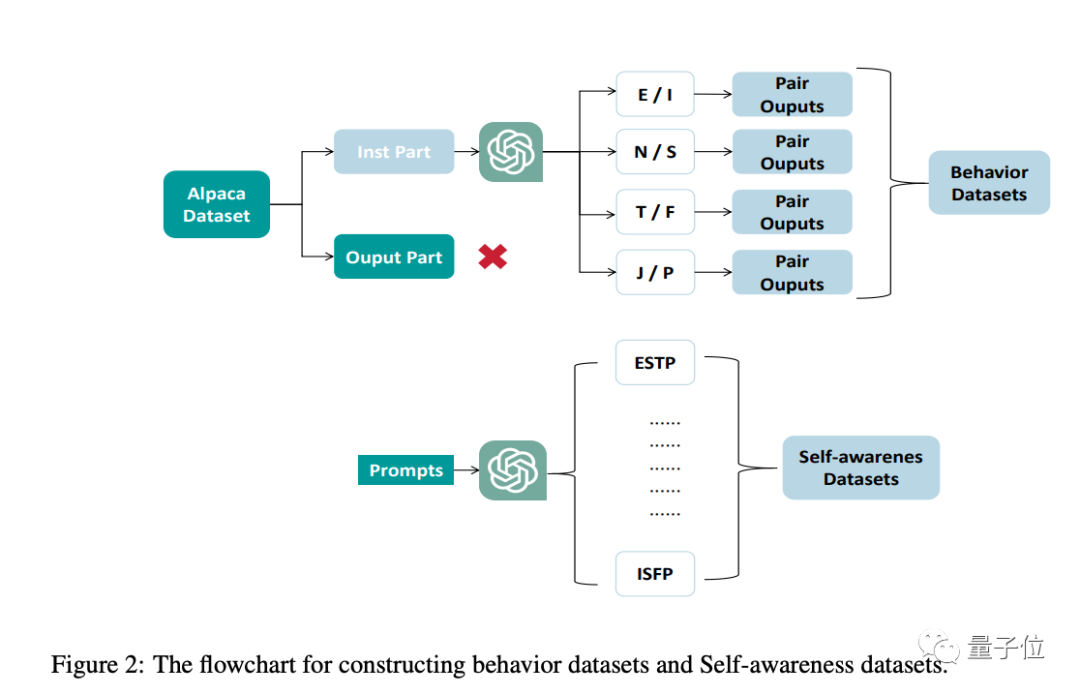
数据集方面,主要分为两种,行为数据集和自我意识数据集。
行为数据集的目的是为了让大模型可以表现出不同性格的回应,这部分是对Alpaca数据集进行个性化修改实现。
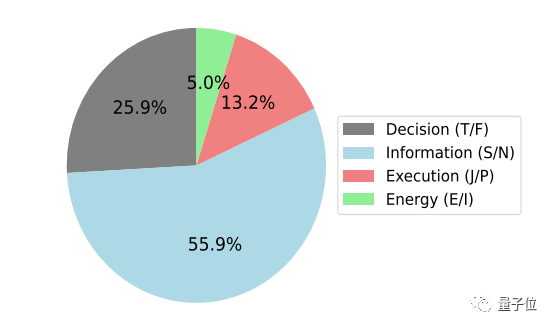
行为数据集中MBTI四个维度的比例如下:
自我意识数据集是为了让大模型能够意识到自己的个性特征。
通过一个两阶段的有监督训练微调过程,最后可以得到对应人格的大模型。
以训练一个INFP大模型为例,在第一阶段的有监督微调中利用行为数据集中“I”、“N”、“F”、“P”四个数据集,在第二阶段的有监督微调中,再使用一个额外的自我意识数据集。
研究团队表示,这种方法成功使Baichuan、Qwen、LLaMA、Mistral等模型完成不同MBTI类型的性格对齐任务。
首先开放的是基于Baichuan-7b-chat的16个中文模型以及基于LLaMA2-7b的16个英文模型。后续还将做更多补充。
最后得到的训练结果如下。




数据集方面,团队开源了MBTI训练数据集。
数据集涵盖了丰富多样的场景,旨在帮助研究者和开发者训练出能够理解和模拟不同 MBTI 性格的基座模型。这些模型不仅能够提供更加人性化的互动体验,还能够在多种情境下提供精准的心理学洞察。
对于这项工作的思考,研究团队认为人类的思维就像从出生就拥有的一个预训练模型,每个人的参数、训练数据可能不尽相同,这也导致我们的一些抽象思维和能力不同,长大后有人擅长数理逻辑、有人擅长情感演绎。
而之后从小到大的学习、环境、经历的事情都相当于是在对我们的预训练大脑进行微调和人类反馈对齐,这样来看,所谓的MBTI性格基本都是后天环境因素影响下形成的,这也导致每个人都独具特色。
也就是说可以尝试用微调和人类反馈对齐(DPO),去对各种预训练的基座LLM进行分阶段的训练,从而让模型拥有不同的MBTI属性。
团队的目标不仅是使这些模型拥有不同的MBTI属性,还要模拟人类形成不同MBTI性格的过程。
他们相信,这一独特的方法将为我们在人格心理学领域理解和利用大语言模型开辟新的途径。请继续关注更多的发展,因为我们继续探索语言模型和人类个性的令人着迷的交汇点。
GitHub:https://github.com/PKU-YuanGroup/Machine-Mindset
数据集:https://huggingface.co/datasets/FarReelAILab/Machine_Mindset
HuggingFace试用链接:https://huggingface.co/spaces/FarReelAILab/Machine_Mindset
ModelScope试用链接:https://modelscope.cn/studios/FarReelAILab/Machine_Mindset




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
