# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这篇文章测评三个AI大模型能力:

常见生成对话式大模型APP,除最早OpenAI发布的ChatGPT外,还有百度文心一言、谷歌Bard等。
今天从代码生成角度,测评三大模型的能力。
为什么选择这个角度?
而不是其他角度?如写周报,写诗等。
因为这些能力怎么判断对错呢?没有统一、明确的评判标准,测评就不会客观了。
相反,代码生成能力不一样,错一点都不行,并且判断标准统一、明确,主要两点:
明确测评标准后,找一个稍微有些测评技术含量的问题:Python编写一个贪吃蛇游戏。
此游戏的实现逻辑相对复杂,即便有经验的程序员要想满足上面两点,一次写完通过也是很有难度的。我们看看机器的表现如何。
三大AI模型,全部使用各家最好模型。
首先问问ChatGPT,这是其中部分回答截图:
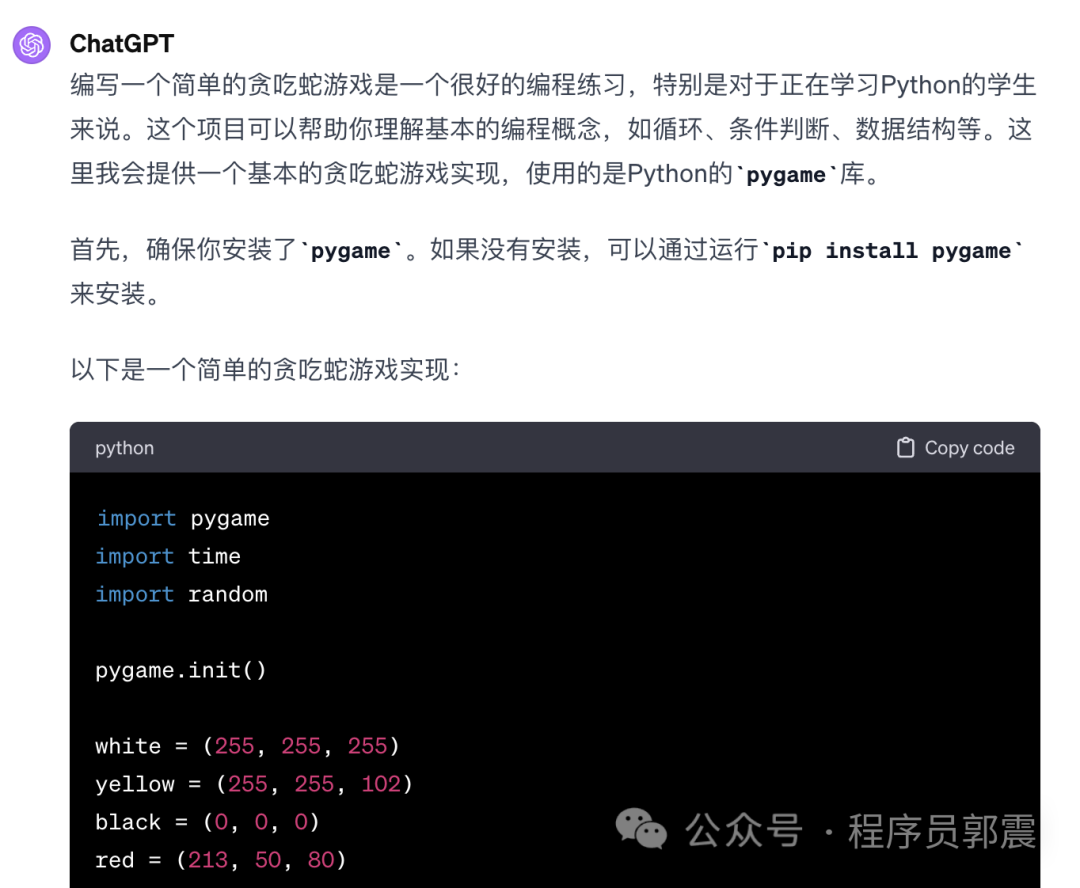
复制代码到PyCharm (Python最常用的集成开发环境)中,运行结果如下所示:

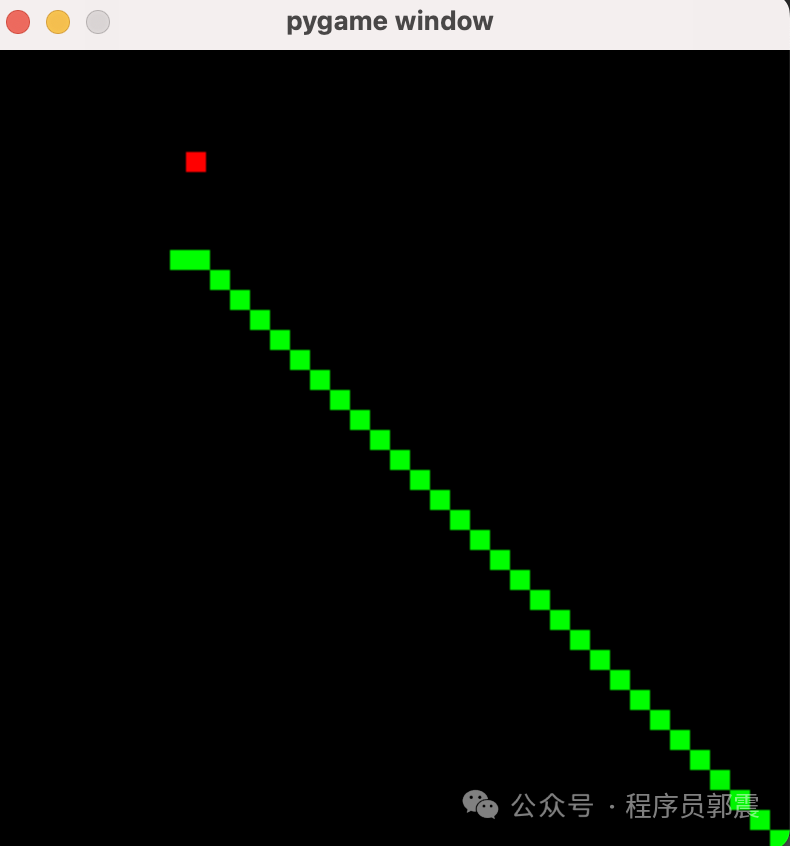
玩玩游戏,看看有无bug,测试3次,结果表明:
文心一言是百度大模型。提问它编写贪吃蛇游戏,返回的代码部分截图,共58行(写过贪吃蛇游戏的应该也知道,这些代码肯定不完整)

复制到PyCharm中,运行代码,结果显示这样,很明显有问题,且无交互能力:
再给文心一言一次机会,重新生成一遍答案,这次与上次一样代码未写完就终止,这次生成59行终止,继续追问它,它回复未回答完:

稍微有些出乎意料第二次还没回答完,第三次回答终于完成。复制所有代码到PyCharm,运行结果是这样,之后程序异常退出:

Bard是谷歌研发的大模型,同样问题提问它:
Bard没有效仿ChatGPT打字机的回复形式,而是思考片刻后,一下全部发我代码(最后部分代码截图),速度很快:
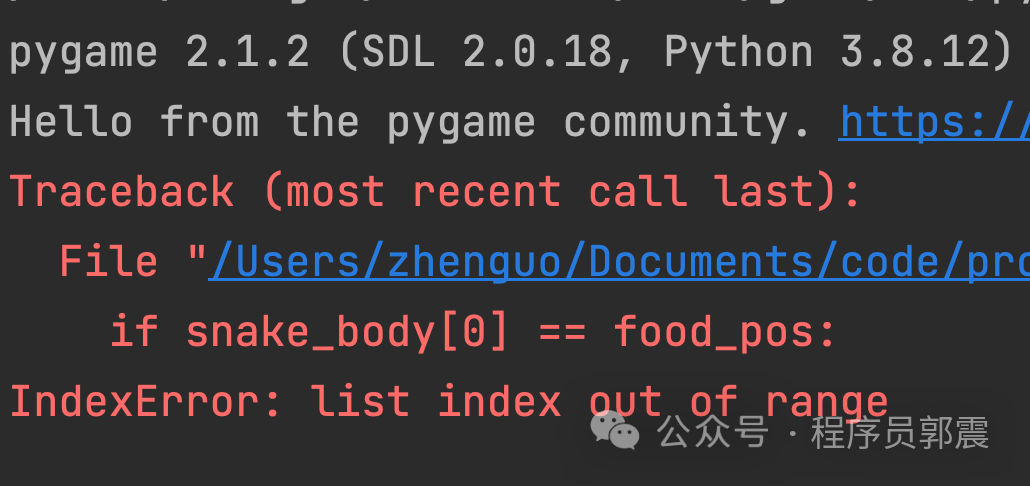
同样复制代码到PyCharm中,第一眼竟然出现没有导入random模块:
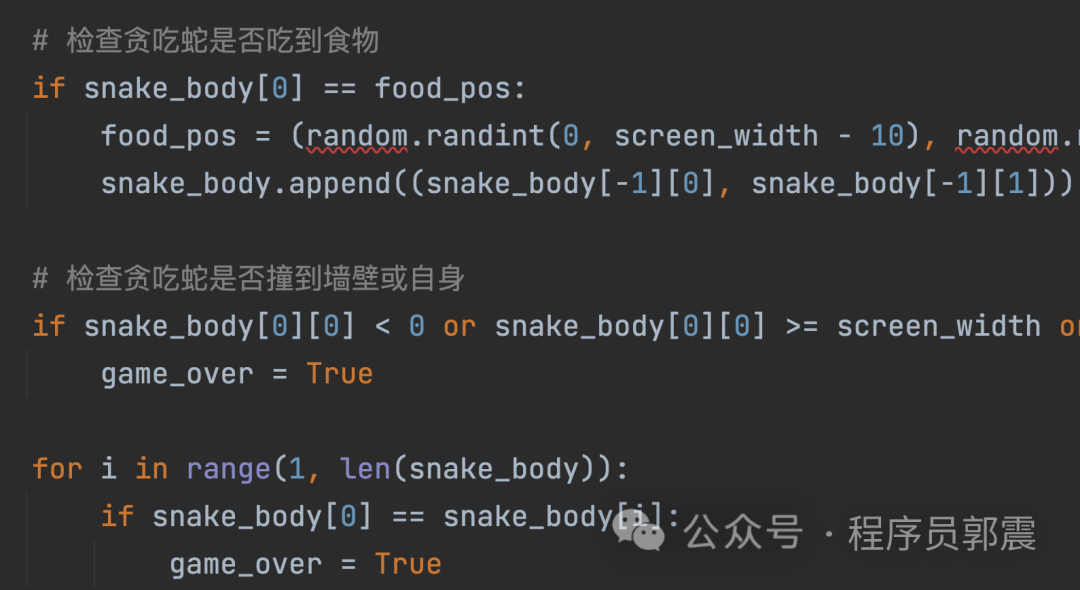
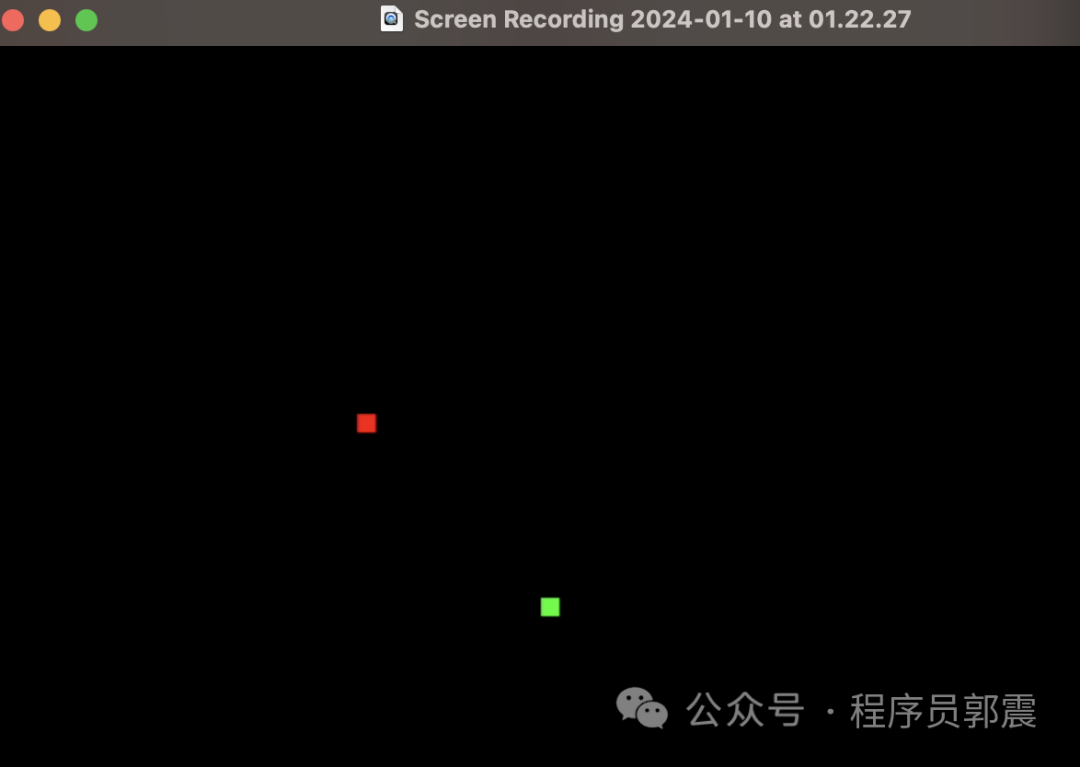
我手写导入random模块,然后运行程序,贪吃蛇的界面出现两个不同颜色的小方块,1秒钟后程序闪退:
通过录制运行视频,截取帧,找到那转瞬即逝的一帧:
测试总结
初步结论:ChatGPT目前生成能力是最好的
ChatGPT 2个月用户就破亿,也印证了这点,如果国内再能直接使用上,估计还会更快。
大家知道零基础学习某个技术,刚开始,难以判断生成答案对错。如果答案再有错误,那无疑会增加学习的难度。这就是如今为什么资料那么多,但是却迟迟无法真正掌握一门技术的重要原因之一。
学技术,认准一个最好的,保证在竞争中不输在工具使用上,这是对于我们个体而言,比较重要的一点!
最后说下个人看法,当今AI技术强如Google,大家看到,他们的Bard依然无法生成像ChatGPT那样准确无误的代码。ChatGPT确实独树一帜,其他大模型想超越它,难度不小。
你们觉得呢?欢迎留言
访问网址:http://zglg.work
文章来自于微信公众号“算法刷题日记”,作者 “郭震”



