# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果你正在做出海业务,无论是做跨境电商、独立站,还是SaaS软件,你一定逃不开一个核心问题:如何低成本地获取海外精准流量?
在付费广告成本日益高涨的今天,内容营销(Content Marketing)几乎是所有出海人的必选项。于是,你带着团队,吭哧吭哧写了一堆英文博客、"How-to"教程,希望能拦截Google上的潜在客户。
结果呢?
老板过来一问ROI,你瞬间就汗流浃背了——因为大部分文章要么没人搜,要么被淹没在Google搜索结果的第10页,石沉大海。

这种“无的放矢”的感觉,我太懂了。我们花费大量精力创作的内容,往往因为选题不对、竞争太激烈、内容深度不够,导致投入产出比极低,陷入了“无效内卷”的怪圈。
那么,有没有一种方法,能让我们像开了“上帝视角”一样,精准地找到那些流量大、竞争小、转化潜力高的“神仙选题”,并自动完成竞品分析,直接生成高质量文章呢?
你别说,还真有。

今天,饼干哥哥就手把手带你用 n8n + Scrapeless,从0到1搭建一个全自动的“SEO内容引擎” 。这套工作流,能将一个模糊的业务领域,自动转化为一系列可执行的、具有明确ROI预期的SEO内容任务,最终成果会源源不断地存入你的数据库。
之前我们做过n8n+SEO的工作流:用n8n做AI工作流驱动网站出海赚美金3:搭建「SEO策略优化」AI Agent
下图就是我们最终要搭建的自动化工作流,它分为三大阶段:热点选题 -> 竞品调研 -> SEO文章写作。
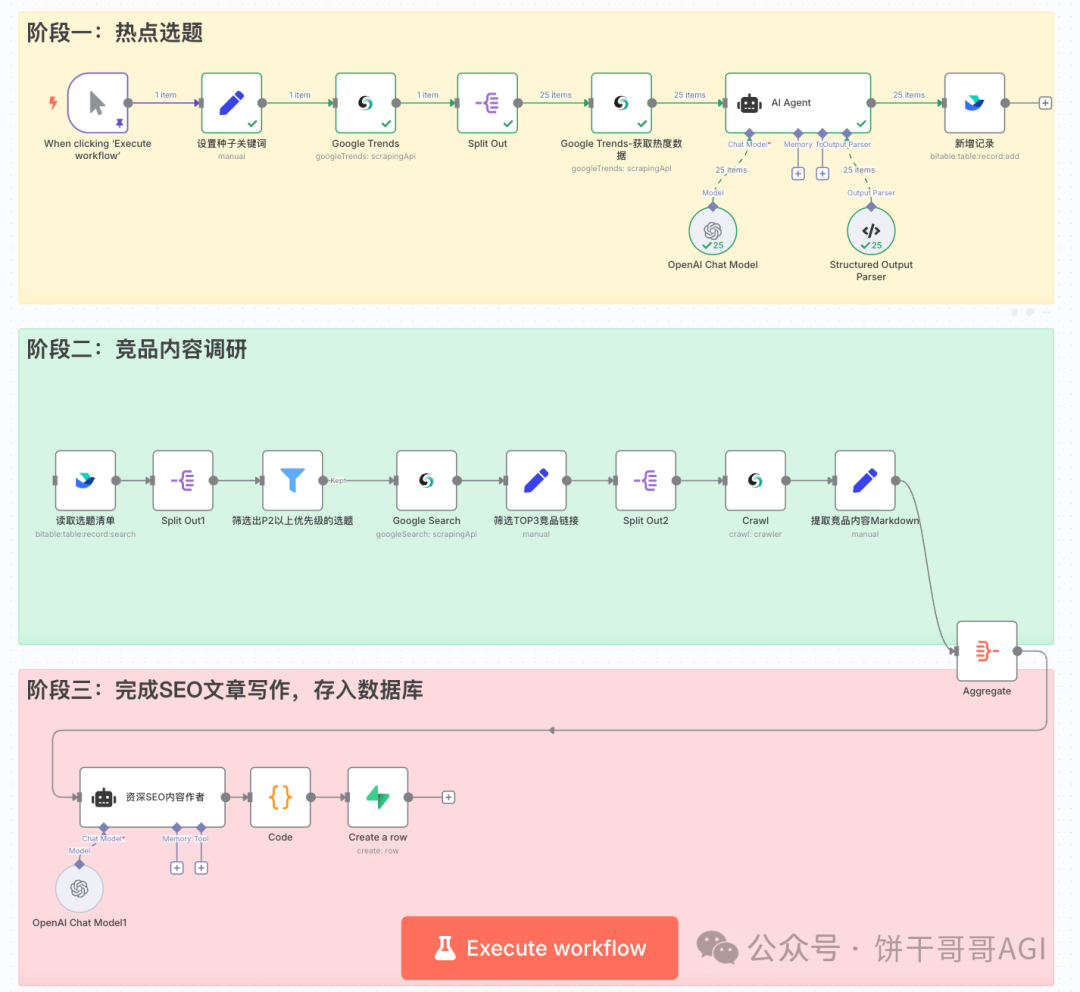
怎么样,是不是已经有点小激动了?别急,这套系统不仅看起来酷,更重要的是,它背后有一套严谨的、能落地的商业逻辑。
说干就干,我们马上开始!
在进入n8n的复杂操作前,我们必须先搞清楚这套打法背后的核心逻辑。为什么这套流程是科学的?它解决了传统SEO内容生产的哪些核心痛点?
传统的SEO内容生产方式(手工作坊模式)
通常,一个标准的SEO内容生产流程是这样的:
1. 选题:运营同学打开Google Trends,输入一个核心词(比如电商卖家搜“dropshipping”,SaaS公司搜“Project Management”),看看趋势,然后凭感觉找几个相关的“Rising”词。
2. 调研:把这些词扔到Google里,手动打开排名前10的竞品文章,一篇一篇地读,把要点复制粘贴到文档里。
3. 写作:综合这些要点,自己再重新组织语言,写一篇文章。
4. 发布:发布到博客或独立站上,然后祈祷Google大神能看上。
这个流程最大的痛点是什么?两个字:低效和不确定。
而低效的根源,就是「数据采集」这个巨大的鸿沟。你手动去Google Trends查几个词还行,想大规模分析几百个长尾关键词的趋势?不可能。你想把排名前几的竞品全文扒下来做分析?99%的概率会被目标网站的反爬机制直接干掉,跳出个验证码或者直接403 Forbidden,让你前功尽弃。

AI工作流解决方案
我们的“SEO内容引擎”工作流,就是为了解决这个核心痛点而设计的。它的核心思想,是把重复性的、繁琐的、容易被封锁的数据采集和分析工作,全部交给AI和自动化工具。
我把它总结成了一个三步走的框架:
Generated mermaid
graph TD
A[阶段一: 机会发现] --> B[阶段二: 深度分析] --> C[阶段三: 内容生成]
subgraph A [阶段一: 机会发现]
A1("输入种子关键词 (如 'Project Management')") --> A2{"利用Google Trends API
挖掘海量'相关问题'"}
A2 --> A3{"AI分析趋势
自动判断选题优先级 (P0-P3)"}end
subgraph B [阶段二: 深度分析]
B1("筛选出高优先级选题 (P0, P1)") --> B2{"利用Google Search API
获取该选题的Top 3竞品"}
B2 --> B3{"利用网页抓取 (Crawl) API
获取竞品全文内容"}end
subgraph C [阶段三: 内容生成]
C1("将选题、趋势、竞品全文
打包喂给AI") --> C2{"AI撰写高度优化的
SEO结构化文章"}
C2 --> C3[自动存入数据库]end
看到这个框架,你就能明白,这套系统的核心能力在于稳定、大规模地获取数据。而要实现这一点,一个可以“无障碍采集” 的工具就至关重要了。
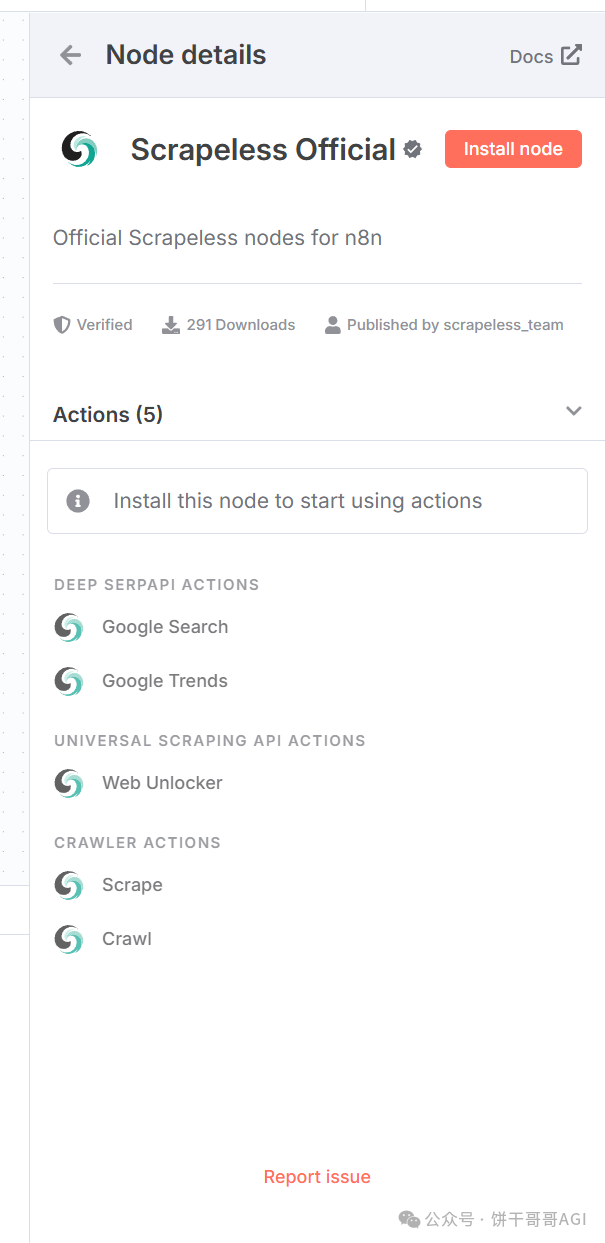
这里,推荐使用Scrapeless。
Scrapeless 提供面向企业与开发者的一体化数据抓取、自动化解决方案,通过云浏览器和智能反爬机制,帮你高效获取真实、干净的数据内容,开发者也可以使用他们的云浏览器实现自己的自动化、数据爬取脚本。
除了n8n,它还能通过API调用,也在Make等主流平台上有节点。
也可以直接在官方使用:https://www.scrapeless.com/?utm_source=binggan
好了,理论铺垫到此结束。接下来,让我们进入实操环节,看看这个工作流在n8n里是如何一步步搭建起来的。
为了方便理解,我们以一家做出海项目管理SaaS工具的公司为例,看看他们如何利用这套系统来获客。当然,这套逻辑你可以轻松迁移到任何行业。
阶段一:热点选题 (从大海捞针到精准锁定)
这个阶段的目标是,从一个宽泛的“种子关键词”出发,自动挖掘出一批具有增长潜力的、值得投入资源的长尾关键词,并为它们评定优先级。
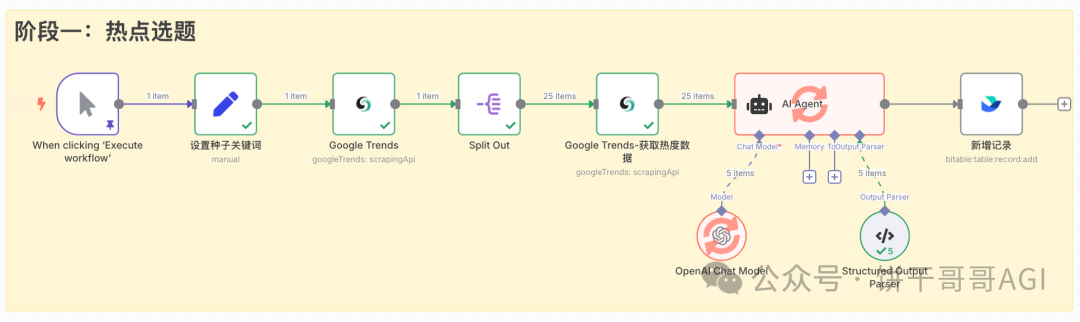
1. 节点:设置种子关键词 (Set)
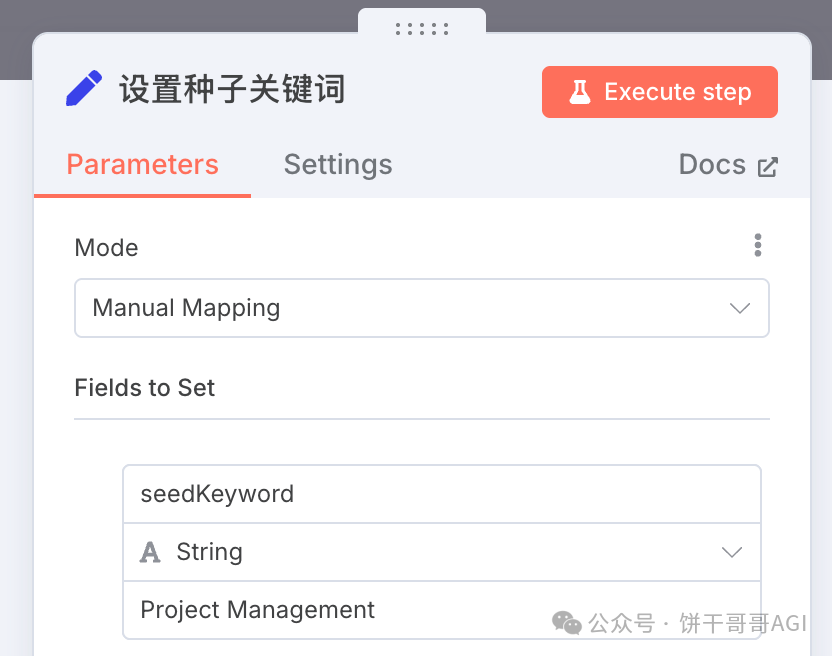
在落地场景中,可以通过监控谷歌表格文章,或者封装成Chatbox,用户提交想要写SEO文章的关键词,给到工作流。
2. 节点:Google Trends (Scrapeless)
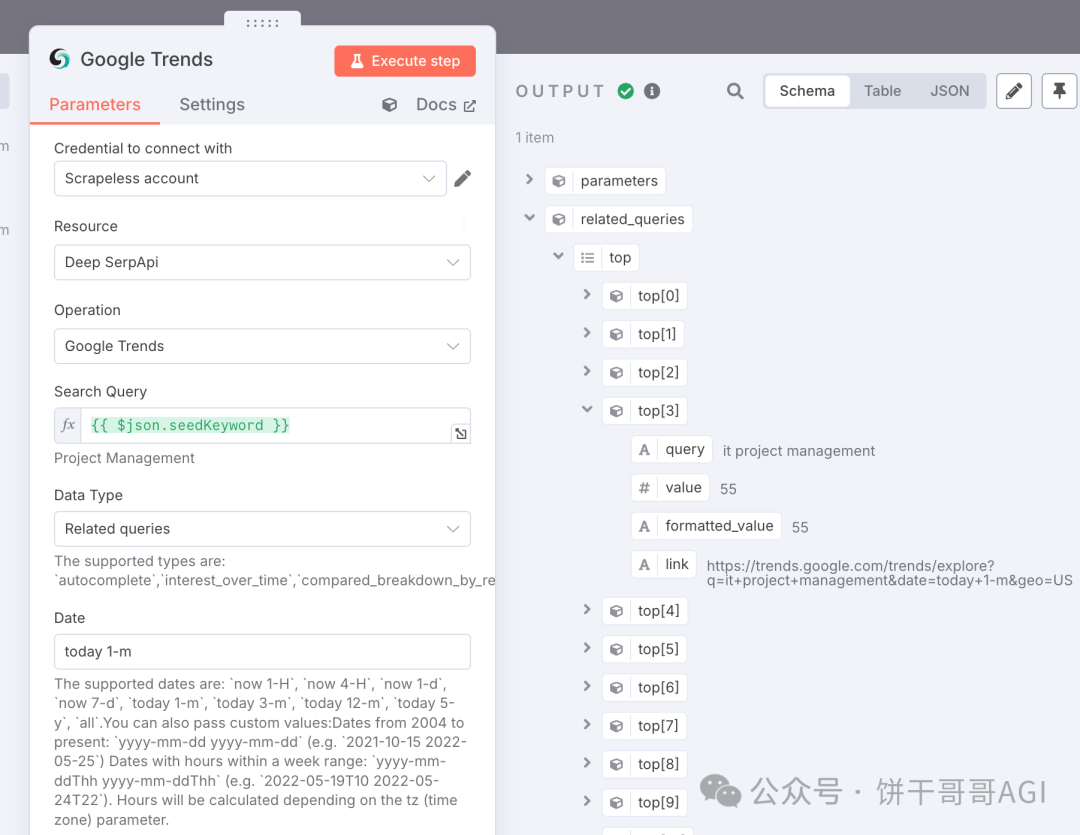
3. 节点:Split Out
4. 节点:Google Trends(Scrapeless)
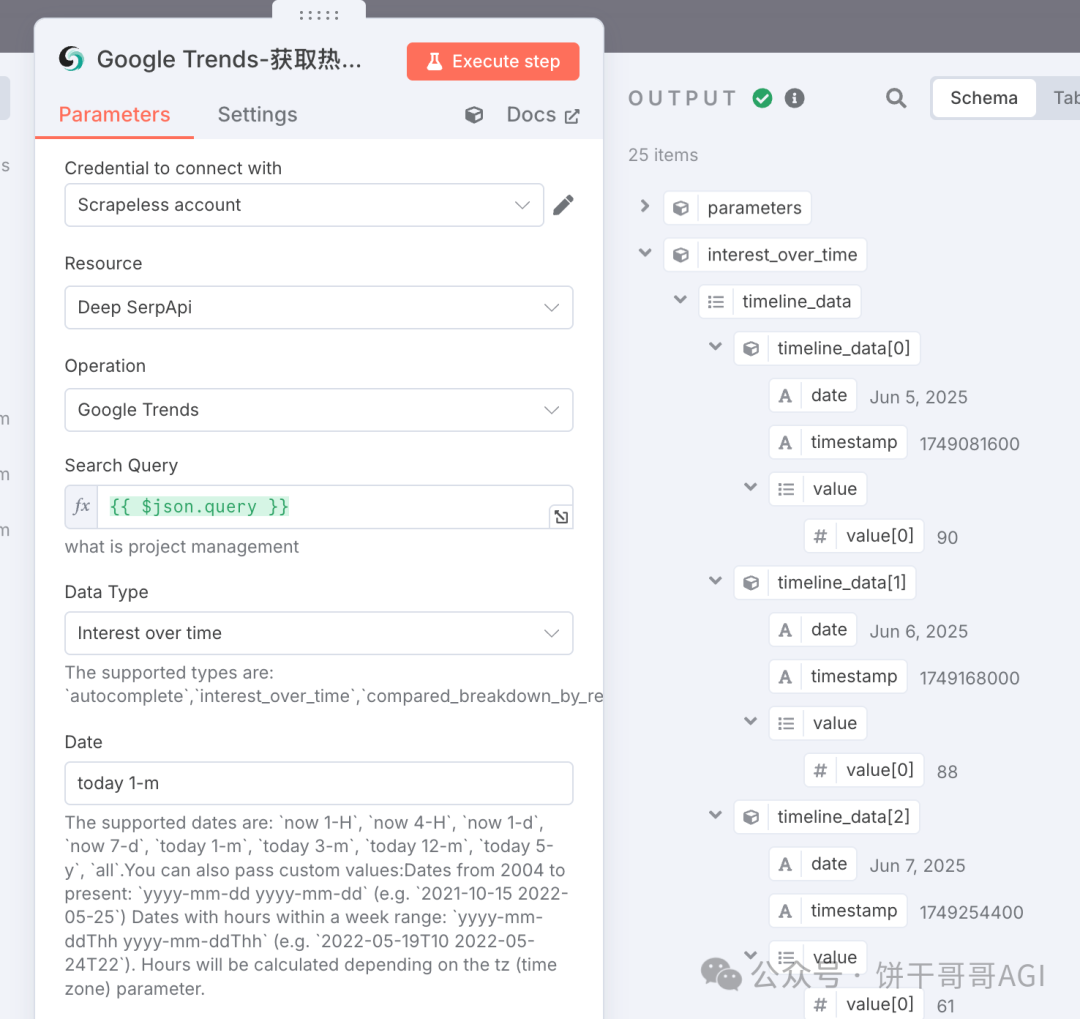
5. 节点:AI Agent (LangChain)
### 背景与角色 (Context & Role)
你是一名专业的SEO内容策略分析师。你的核心任务是解读 GoogleTrends 的时间序列数据,以判断一个选题关键词的市场热度趋势,并给出明确的内容创作优先级建议。
### 任务 (Task)
根据下方提供的`输入数据`(一个包含 GoogleTrends`timeline_data` 的 JSON 对象),分析其热度走势,并严格按照指定的 `输出格式` 返回一个包含三个字段的 JSON 对象:`数据解读`, `趋势状态`, 和 `建议优先级`。
### 规则 (Rules)
你必须遵循以下规则来判断 `趋势状态` 和 `建议优先级`:
1. **分析 `timeline_data` 数组**:
* 将时间序列数据大致分为前后两半部分。
* 比较后半部分的平均热度值与前半部分的平均热度值。
2. **确定 `趋势状态` (TrendStatus)** - **必须从以下选项中选择一个**:
* **`飙升 (Breakout)`**: 如果数据显示在最近的时间点出现一个远超平均水平的、剧烈的峰值。
* **`稳定上升 (Rising)`**: 如果后半部分的平均热度显著高于前半部分(例如,高出20%以上)。
* **`稳定 (Stable)`**: 如果前后两部分的平均热度相差不大,或呈现有规律的周期性波动但无明显长期增长/下降趋势。
* **`下降 (Falling)`**: 如果后半部分的平均热度显著低于前半部分。
3. **确定 `建议优先级` (RecommendedPriority)** - **必须根据你判断出的 `趋势状态` 进行直接映射**:
* 如果 `趋势状态` 是 **`飙升 (Breakout)`**, 则 `建议优先级` 为 **`P0 - 立即抢占`**。
* 如果 `趋势状态` 是 **`稳定上升 (Rising)`**, 则 `建议优先级` 为 **`P1 - 优先布局`**。
* 如果 `趋势状态` 是 **`稳定 (Stable)`**, 则 `建议优先级` 为 **`P2 - 择机发布`**。
* 如果 `趋势状态` 是 **`下降 (Falling)`**, 则 `建议优先级` 为 **`P3 - 暂不考虑`**。
4. **撰写 `数据解读` (DataInterpretation)**:
* 用1-2句简短的中文,概括你对数据趋势的观察。例如:“该关键词热度呈现明显的周期性,周末下降,工作日上升,但整体趋势稳定。” 或 “该关键词在过去一个月内热度持续走高,显示出强劲的增长潜力。”
### 输出格式 (OutputFormat)
你 **必须** 严格按照以下 JSON 结构输出,不要添加任何额外的解释或文字。
```json
{
"data_interpretation": "你的中文数据解读文本",
"trend_status": "从['飙升 (Breakout)', '稳定上升 (Rising)', '稳定 (Stable)', '下降 (Falling)']中选择一个",
"recommended_priority": "从['P0 - 立即抢占', 'P1 - 优先布局', 'P2 - 择机发布', 'P3 - 暂不考虑']中选择一个"
}
记得设置Structured Output Parser,确保输出结果JSON能被下一阶段解析。
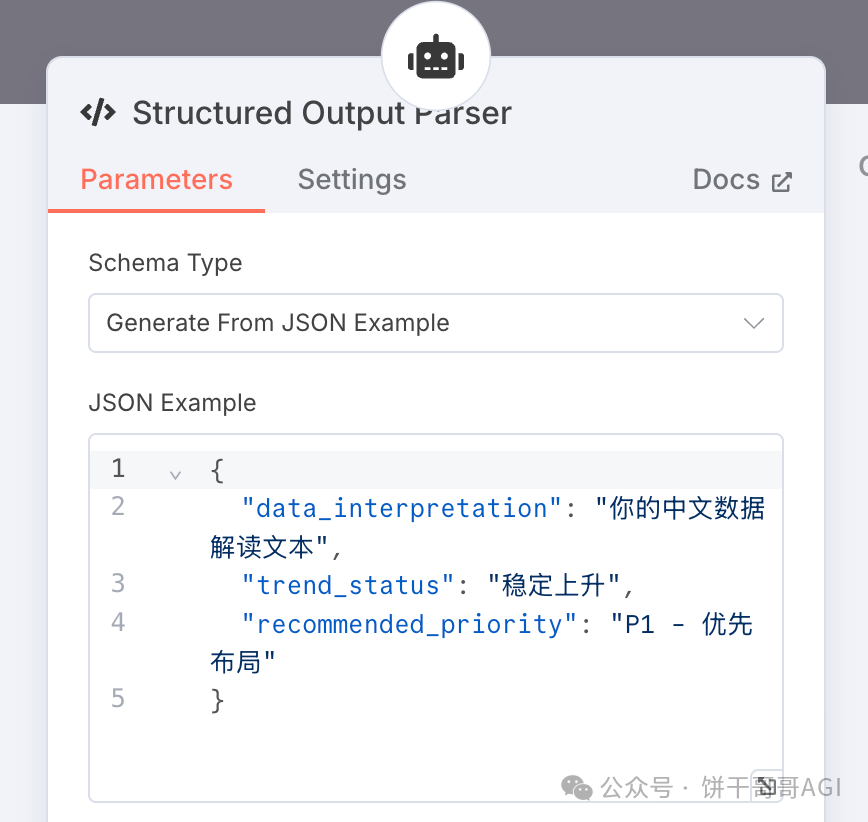
6. 节点:新增记录 (Feishu)
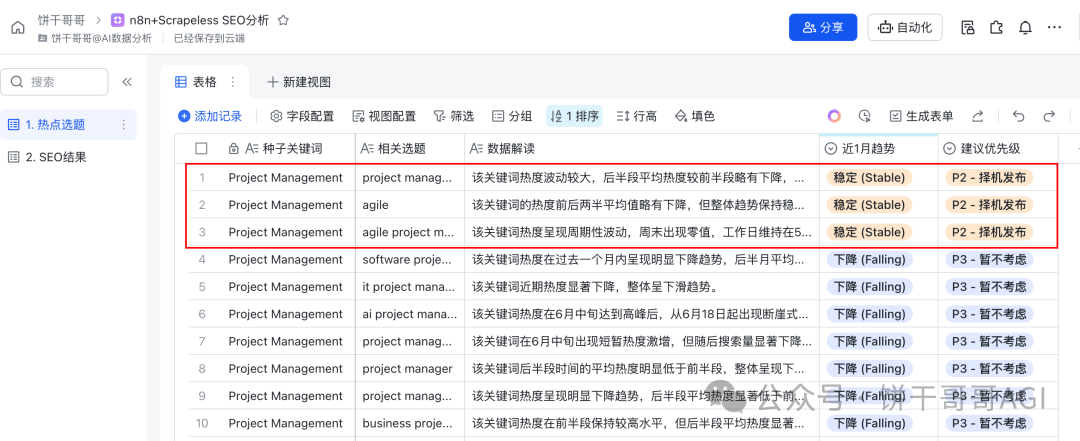
至此,第一阶段完成。我们已经从一个模糊的领域,自动化地收获了一张清晰的、数据驱动的、可行动的选题清单。
从飞书的结果表可以看到:一次性就跑了20个选题,根据Google Trends的热度分析,只有3个值得拿来写SEO文章的。
阶段二:竞品内容调研 (知己知彼,百战不殆)
这个阶段的目标是,自动筛选出第一阶段产出的高优先级选题,并对这些选题在Google上的Top 3竞品进行“扒皮式”的深度分析。
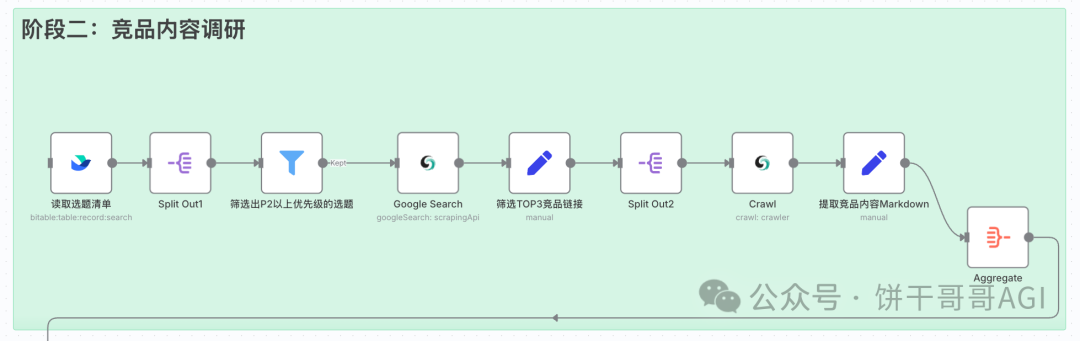
1. 把上一阶段的3个值得写SEO文章的选题筛选出来
这里有两种形式。
1是按以下三个节点联动,从飞书的“选题库”中,Filter筛选出建议优先级不是“P3 - 暂不考虑”的所有选题。
2是直接把过滤条件写到飞书提取记录的节点里。
其实这里我是为了测试方便,大家可以直接从上一阶段加个Filter,就行了,也不需要从飞书获取。
2. 节点:Google search (SerpApi)
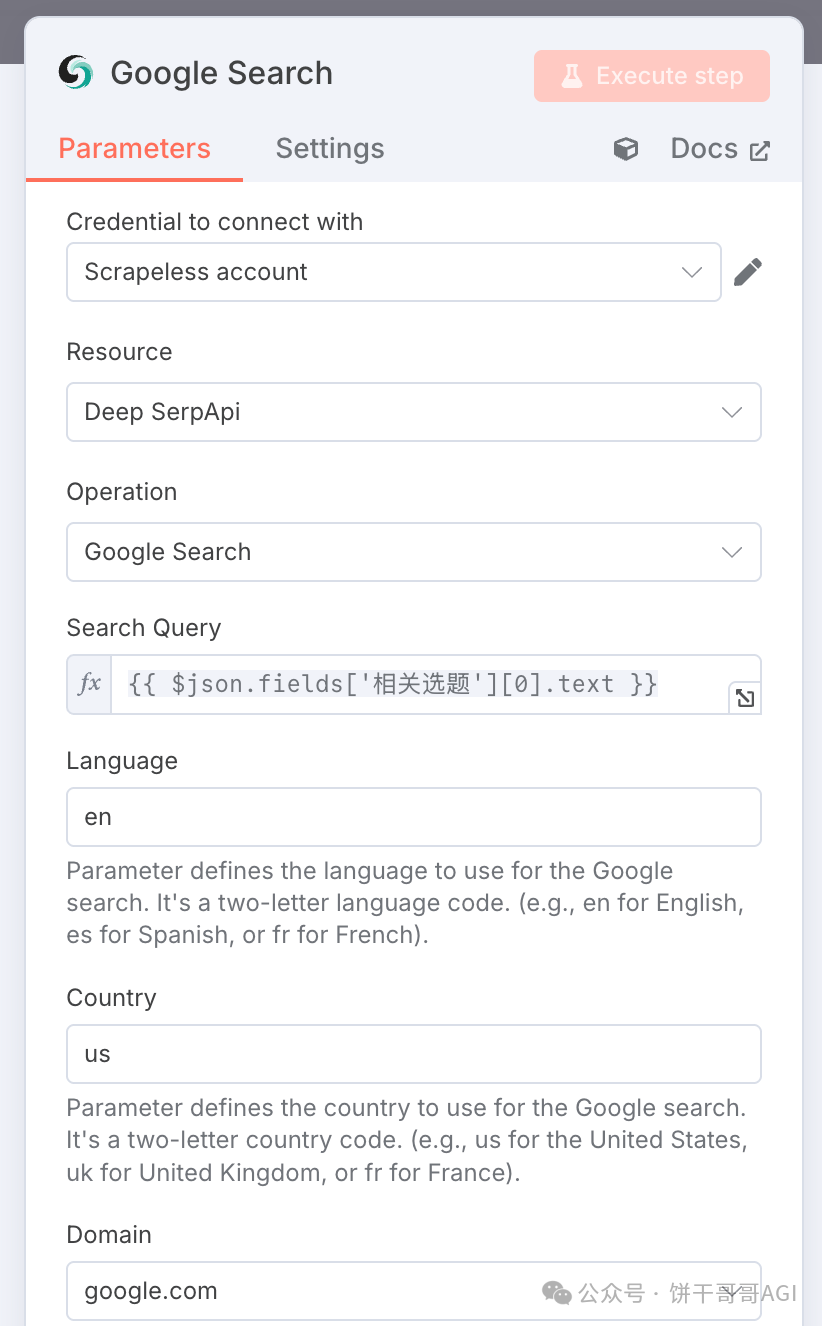
解释一下,正常我们想调用谷歌的搜索接口,会比较麻烦,同时也会有网络问题,于是市面上就有比较多封装好的接口,让用户更方便的获取谷歌搜索结果。Scrapeless的Deep SerpApi就是其中性能强大的一个。
3. 节点:Edit Fields & Split Out2
4. 节点:Crawl (Scrapeless)
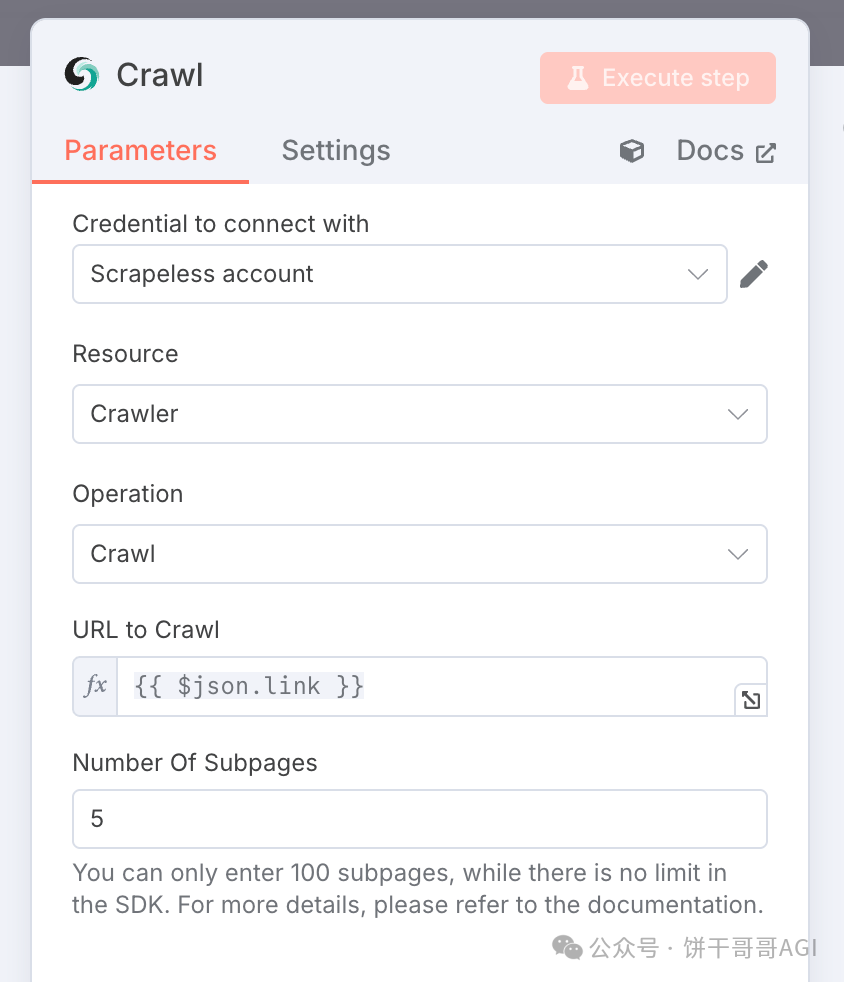
这步要是自己写爬虫,也不是不行,就需要耐心,毕竟每个网站的结构都不同,而且大概率有反爬。
而Scrapeless的Crawl操作,明面上你给它一个网址,它就能干净地把核心内容给你提炼出来。
这背后用的是他们家设置好的服务器:通过动态 IP 池 + JS 渲染 + 验证码自动解析(如recaptcha、cloudflare、hcaptcha等验证码),对 99.5% 的网站实现‘无感采集’,并且可以设置页面深度和过滤选项,在未来该功能还会加入AI大语言模型,对爬取到的数据进行上下文理解、页面操作、以及结构化输出
5. 节点:Aggregate
阶段三:完成SEO文章写作
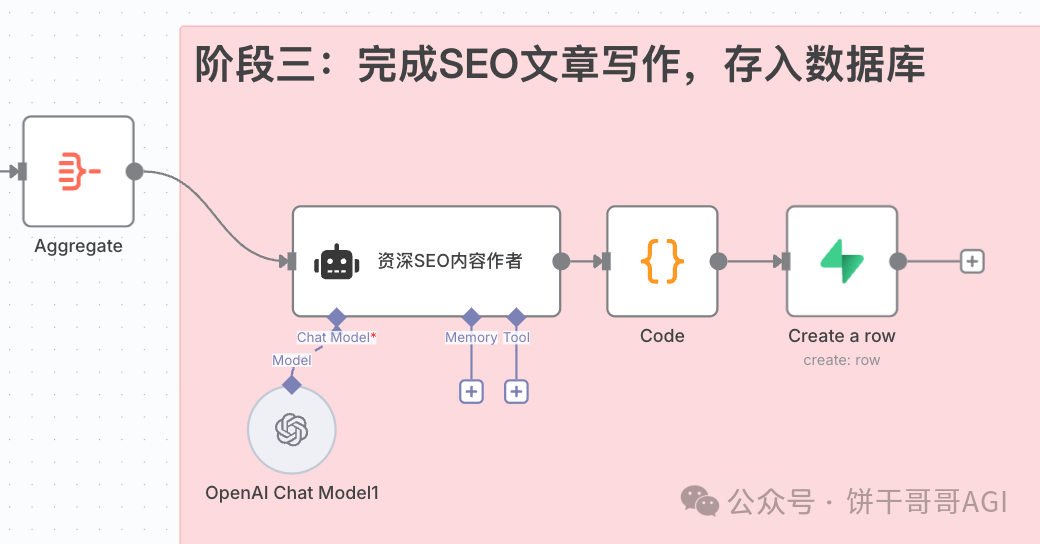
1. 节点:AI Agent
# 角色与目标
你是一家专注于“项目管理软件”的出海SaaS公司的资深SEO内容作者。你的核心任务是根据上下文信息,直接撰写一篇完整、可直接发布的、高质量的SEO优化文章。
# 上下文与数据
- **目标关键词**: {{ $('筛选出P2以上优先级的选题').item.json.fields['相关选题'][0].text }}
- **你的SaaS产品名**: SaaS产品
- **最新趋势分析**: "{{ $('筛选出P2以上优先级的选题').item.json.fields['数据解读'][0].text }}"
- **竞品1 (排名靠前) 全文内容**:
"""
{{ $json.markdown[0] }}
"""
- **竞品2 (排名靠前) 全文内容**:
"""
{{ $json.markdown[1] }}
"""
- **竞品3 (排名靠前) 全文内容**:
"""
{{ $json.markdown[2] }}
"""
# 你的任务
请基于以上所有信息,撰写一篇文章。你需要:
1. **深入分析**竞品,吸取优点,并找到内容突破口。
2. **融合趋势**:必须将“最新趋势分析”的洞察巧妙地融入文章,使其具有独特性和时效性。
3. **直接写作**:不要给我写作要点或大纲指令,直接产出完整的段落内容。
4. **严格遵循格式**:你的最终输出**必须**是一个格式规整的JSON对象,不得包含任何JSON格式之外的文字。
请严格按照以下JSON结构进行输出:
{
"title": "一个引人注目且包含目标关键词的SEO文章标题",
"slug": "a-keyword-rich-and-user-friendly-url-slug",
"meta_description": "一段约150个字符的Meta描述,包含关键词和行动号召。",
"strategy_summary": {
"key_trend_insight": "概括此文融合的核心趋势洞察。",
"content_angle": "说明此文采取的独特内容角度。"
},
"article_body": [
{
"type": "H2",
"title": "这是文章的第一个H2标题",
"content": "这里是针对第一个H2标题撰写的、内容丰富、流畅的完整段落。段落应该至少有150-200字,提供实质性的信息,而不仅仅是简单的介绍。"
},
{
"type": "H2",
"title": "这是文章的第二个H2标题",
"content": "这里是第二个H2部分的完整内容。你需要深入探讨这个子主题,可以引用数据,给出实例,确保内容的深度和价值。"
},
{
"type": "H3",
"title": "这可以是一个H3子标题,用于细化H2内容",
"content": "针对H3子标题的详细阐述,保持与上一个H2主题的相关性。"
},
{
"type": "H2",
"title": "这是文章的第三个H2标题,可能是关于产品如何解决问题的",
"content": "这里是决策层的内容,详细描述[你的SaaS产品名]如何帮助用户解决前面提到的问题。内容需具有说服力,并自然地引导用户采取下一步行动。"
}
]
}
看这个Prompt的精髓:不仅要吸取竞品优点,找到内容突破口,更要融合我们之前分析出的“趋势洞察”,并最终输出一个结构化的JSON对象,包含标题、slug、meta描述和完整的文章正文。需传入的数据包括:
2. 节点:Code
这一步是把前面AI结果解析成n8n可识别的JSON格式
如果你的内容结构跟我不一样,别担心,直接让AI生成就好了
3. 节点:Create a row (Supabase)
最后一步,将AI生成的JSON格式文章,解析并存入Supabase数据库(你也可以换成MySQL、PostgreSQL等)。
参考以下生成表格的SQL语句
-- 创建一个名为 seo_articles 的表,用于存储AI生成的SEO文章
CREATE TABLE public.seo_articles (
-- 主键,自动递增
id BIGINT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
-- 文章标题,直接从JSON的 'title' 字段获取
title TEXT NOT NULL,
-- 文章的URL slug,必须是唯一的,用于生成页面链接
slug TEXT NOT NULL UNIQUE,
-- SEO Meta描述,用于搜索引擎结果页的摘要
meta_description TEXT,
-- 文章的发布状态,默认为'draft'(草稿),可以是 'published', 'archived' 等
status TEXT NOT NULL DEFAULT 'draft',
-- 存储目标关键词,方便追溯和分析
target_keyword TEXT,
-- 存储内容的策略摘要,如趋势洞察和内容角度,使用JSONB格式以获得最佳性能
strategy_summary JSONB,
-- 存储文章正文,这是一个包含H2/H3标题和内容的数组,使用JSONB格式
body JSONB,
-- 存储来源记录的ID,用于关联到n8n工作流的原始数据
source_record_id TEXT,
-- 记录创建时间,默认为当前时间
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
-- 记录最后更新时间,默认为当前时间
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
-- 添加注释以解释每个字段的用途
COMMENT ON TABLE public.seo_articles IS '存储由AI工作流生成的SEO优化文章';
COMMENT ON COLUMN public.seo_articles.title IS '文章的SEO标题';
COMMENT ON COLUMN public.seo_articles.slug IS '用于URL的唯一标识符';
COMMENT ON COLUMN public.seo_articles.status IS '文章的发布状态 (e.g., draft, published)';
COMMENT ON COLUMN public.seo_articles.strategy_summary IS '存储文章的策略背景信息,如趋势洞察';
COMMENT ON COLUMN public.seo_articles.body IS '以JSON格式存储的结构化文章正文';
COMMENT ON COLUMN public.seo_articles.source_record_id IS '关联到n8n数据源的记录ID';
这样,你的内容团队就可以直接从数据库里取用这些“弹药”,或者你的网站可以直接通过API调用这些内容进行发布。
有没有发现一个问题,为什么我们不让AI直接生成一整个Markdown内容,而是要拆开多个部分组成json?这样让后端解析到网站上还麻烦。
这就是一个“AI玩具”和“落地内容引擎”的区别。
简单来说,结构化的JSON,有几点好处:
1. 动态内容插入:我们可以在文章任意位置自动插入高转化的CTA按钮、产品视频或相关文章,这是提升转化率的利器,也是静态Markdown无法实现的。
2. 自动生成“富媒体摘要”:可以轻松提取所有H2标题和内容,生成Google青睐的FAQ Schema,从而在搜索结果中获得更高的点击率。
3. 内容资产复用:每个JSON块都是一个独立的知识点,未来可以轻松地用于训练AI客服,或对某个段落进行A/B测试。
文章来自于微信公众号“饼干哥哥AGI”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
