# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
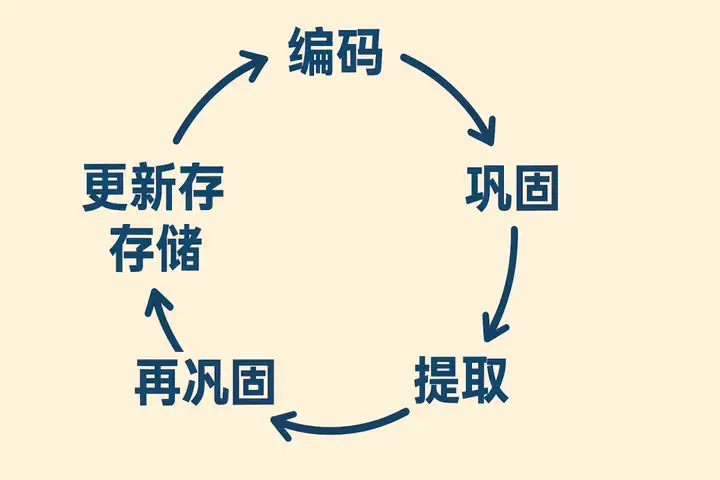
从神经科学的角度看,记忆的形成、存储和提取涉及大脑多个区域的协同工作。
其核心可分为四个主要阶段:
1. 编码(Encoding): 这是记忆过程的入口。
当我们经历一件事情时,感官系统(视觉、听觉、触觉等)接收到信息,这些信息被转换成大脑能够理解和处理的神经信号。
这个过程受到注意力的严格调控。
只有被我们注意到的人和事,才有机会进入记忆的下一站。
情感在编码阶段扮演着至关重要的角色,杏仁核(Amygdala)作为大脑的情感中枢,会为附着着强烈情感(无论是喜悦、恐惧还是悲伤)的记忆打上“高亮”标签,使其更容易被编码和长久保存。
2. 存储(Storage): 经过编码的信息并非立即“存盘”。
它首先进入感觉记忆(Sensory Memory),这是一个极其短暂的缓冲区,只能维持几秒钟。被注意到的信息随后进入短期记忆(Short-term Memory)或工作记忆(Working Memory)。
这个阶段的容量和时长都非常有限,通常只能记住7±2个信息组块,持续时间从十几秒到几分钟不等。
前额叶皮层(Prefrontal Cortex)在工作记忆中扮演着关键角色,它像一个临时的信息处理中心,让我们能够处理眼前的任务。
3. 要让记忆长久保存,就必须经历巩固(Consolidation)的过程。
在这个过程中,短期记忆通过海马体(Hippocampus)的整理、加工和“存档”,逐渐转化为长期记忆(Long-term Memory),并被分布式地存储在大脑皮层的各个相关区域。
这个过程在睡眠中尤为活跃,大脑会重放白天的经历,加强神经元之间的连接(突触可塑性),从而稳定记忆。
4. 提取(Retrieval): 当我们需要回忆某段往事时,大脑会根据线索重新激活存储在皮层中的神经元网络。
这个过程并非简单的“读取”,而更像是一次重构(Reconstruction)。
每次回忆,我们都可能不自觉地加入新的信息、情感和当下的理解,从而对原始记忆进行微调甚至修改。
这就是为什么我们的记忆会随着时间的推移而发生变化,甚至出现偏差的原因。
被提取的记忆会暂时变得不稳定,容易受到干扰和更新,这既是记忆动态适应性的体现,也是其不可靠性的根源。
这是记忆的起点,一个极其短暂的信息缓冲区。
当我们看到一束闪光,即使光线消失,其影像仍会在脑海中停留片刻(图像记忆,约250毫秒);
当我们听到一个词,即使声音停止,其回响也会短暂留存(回声记忆,约4秒)。
感觉记忆确保我们对世界的感知是连续而非断裂的。
当信息引起我们的注意时,它便从感觉记忆进入短时记忆。
这好比一张临时的“便签纸”或“意识的办公桌”,我们在此处理当前任务所需的信息。
经过加工和巩固的信息最终会进入长时记忆,其容量和存储时间几乎是无限的。
迅速总结一下人脑记忆的特点:
不同的个体只有对感兴趣的内容才会进入大脑开始加工存储,按照不同类型会有极短的记忆,短期记忆和长期记忆。
每一次记忆的延长不是简单的记忆叠加,而是要不断的萃取加工,记忆之间是有关联关系的,主观的,并通过遗忘机制来保证记忆系统的稳定运行。
大模型 的记忆机制主要分为两种:
短期记忆和长期记忆。
这是最基础、最直接的记忆形式。大模型(如 GPT、Gemini 系列)在处理请求时,只能“看到”当前输入给它的文本序列,这个序列就是它的上下文窗口。
为了克服上下文窗口的限制,Agent 需要将信息存储在外部系统中,在需要时再取回。这是实现长期、持续性记忆的关键。
向量数据库 (Vector Databases) 与 RAG
知识图谱 (Knowledge Graphs)
尽管现有技术实现了记忆功能,但仍面临诸多挑战。
1. 上下文窗口的限制
2. 外部记忆(RAG)的限制
针对以上限制,学术界和工业界正在探索以下优化方向:
Agent 会周期性地回顾近期的记忆,并进行总结、归纳和推理。
它会主动提问:
“这些对话中最重要的核心是什么?”
“我从中学到了关于用户什么新的偏好?”,
然后将这些更高层次的“领悟”存入长期记忆中。
这极大地提高了记忆的质量和抽象程度。
这虽然没有完全解决问题,但在很大程度上缓解了对外部记忆的频繁依赖,使得在一次交互中可以容纳整本书、多个复杂文档或完整的代码库,极大地扩展了“短期记忆”的边界。
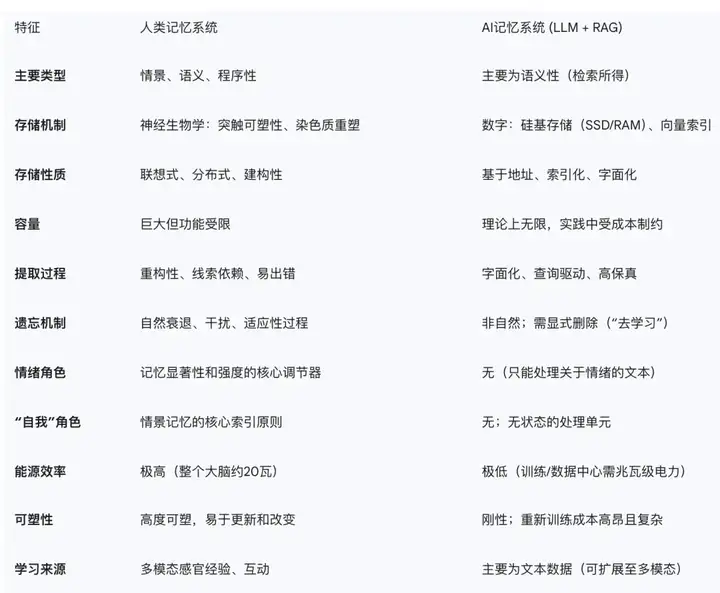
可以从下面这个对比图上看出,人类的记忆系统完爆 AI 的记忆系统。单从记忆这个能力来讲,AI 还有一段很长的路要走。

这部剧的大概剧情是在不远的2033年,六家科技公司运营虚拟现实酒店,将死之人可以“上传”其中安享后世。
在虚拟世界的人非常爽,窗外景色也能一键切换,从夏天调到冬天,就像更换手机壁纸一样方便。
但是在虚拟世界里思考、说话、行动,都需要耗费流量,也得氪金。
在上载世界中,每一个上载者都会对应有一位“天使”而一个"天使"负责多个上载者。天使与上载者交流,可以靠话筒纯语音,也可通过VR眼镜实体“面对面”(眼镜式&头戴式)。

天使一般有下面几种类型:
创作者:在上载者到达上载世界的第一天,“天使"负责通过照片信息,创作出他们在上载世界中的形象;之后可以随意一挥画笔,改变上载者的形象(有无手指、翘辫子等)
客服:上载者喊一句“Angel”,便会前来提供帮助(需要注意的是ange/不负责端茶倒水的粗活,粗活都是靠AI服务员完成的,类似于《善地》里的Janet);因为需要随叫随到,有轮班制,白班夜班;
保姆:需要对上载者进行管理,控制睡眠,监控位置与情绪,以确保他们的良好身心状态。特别有趣的是,“天使”还会被上载者评分(五星制),直接挂钩其工资以及是否被开除等。
我们暂且不说这种记忆上传是否真的有商业价值,技术实施的可行性,以及是否有伦理道德风险。
如果把它当做一个 AI 产品的话,单从整体的构想和设计上来讲还是比较大胆和有想象力的。
然后我看到这个 AI 产品的官网上写着这样一段话:

ok,终于。话题到了这一 part。这就是 Me.bot 了。
Mebot并非旨在打造一个无所不知的通用AI,而是致力于成为一个极度个性化的、服务于个体成长的AI伴侣。
那么,一个以记忆为核心基础要求的 AI 产品大概会是什么样的呢?
Mebot的核心创新点:
1. 以用户为中心的记忆构建(User-Centric Memory Curation):
Mebot的核心价值主张是,让AI真正“懂你”。它鼓励用户主动“投喂”数据,包括导入浏览器收藏的链接、上传长段的语音录音(如会议、课堂、个人感悟)、记录日常的笔记和想法。
这种模式与被动记录所有信息的“监控式”记忆不同,它强调用户的主动参与和筛选。用户自己决定了哪些信息是重要的,值得被“我”的AI记住。
2. 从数据到洞察的转化(From Data to Insights): Mebot的创新不止于存储。它利用LLM的强大能力,对用户导入的杂乱信息进行自动化的整理、转写、提炼和归纳。
3. 基于长期记忆的深度对话(Dialogue Based on Long-Term Memory):
这是Mebot区别于普通聊天机器人的关键。
当你与Mebot对话时,它的回应不仅仅基于当前的上下文,更是基于它对你长期积累的个人知识库的理解。
你可以和它深入探讨你几个月前记录过的一个想法,或者让它帮你回顾某个复杂项目的演进过程。
它能够在你需要的时候,提出有针对性的见解和建议,有点Agent 的味道。
4. 隐私与数据主权优先面对记忆数据的极端敏感性,Mebot(及其同类产品)深知隐私是其生存的基石。
它们通常会强调端到端加密、数据匿名化处理,并给予用户对自身数据的完全控制权和删除权。这在一定程度上回应了前文提到的隐私安全顾虑。
一开始,我把它当做其他类似的 AI 产品,去搜索啊,建图啊,做报告啊,体感一般。当时就觉得可能是另一款同质化的产品。
不过我想他们应该没有理由做这么一个同质化的产品,就翻了翻官网介绍和用户反馈。
这是 Me.bot 两个用户真实的反馈引起了我的注意:


终于,我发现了 Me.bot 真正的玩儿法:
你主动记录的碎片内容越多,它当做你的记忆外脑,会整合你之前记录的个人记忆。
我感觉 Me.bot 移动端应该是主要使用场景,可以随时拿起来记录下任何碎片想法,图片,录音,文字,链接。
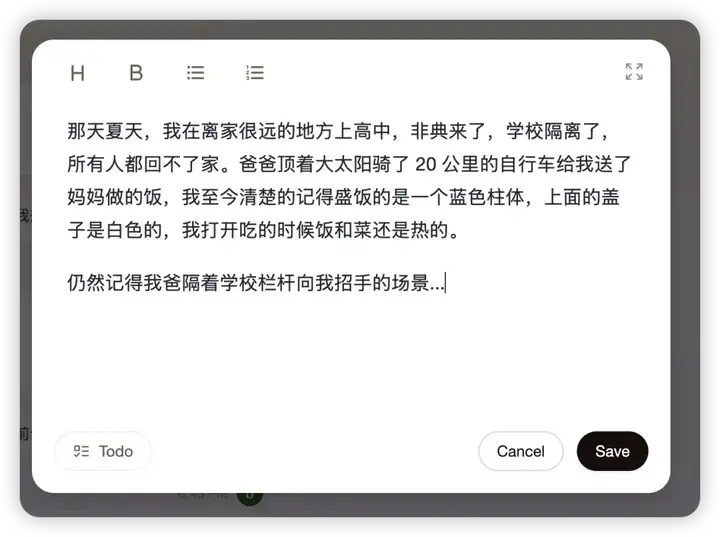
那天晚上,我开始其实只是抱着内测这个产品的目的,不知不觉录入了大概十多条碎片关于自己和家人的信息,然后随手上传了一小段和孩子聊天的内容。
然后,当我看到 me.bot 以自己记忆为主体展现出来内容时,确实感觉不太一样。
怎么讲呢,它不像看上去那样是一个笔记类产品,通过功能引导鼓励你去上传自己记忆的点点滴滴,或者过去或是当下,就像日记一样。
我久久的坐在屏幕前,一遍遍的看着下面这段文字时,不同时期的长短记忆翻滚而来。
虽然Me.bot交互和功能仍显得有些简陋,我就像史铁生说的那样,当初打出那颗子弹在多年后射中了自己的眉心。
一动不动。
我大概理解了这款产品的初衷,这是一个充满人文关怀的 AI 产品。
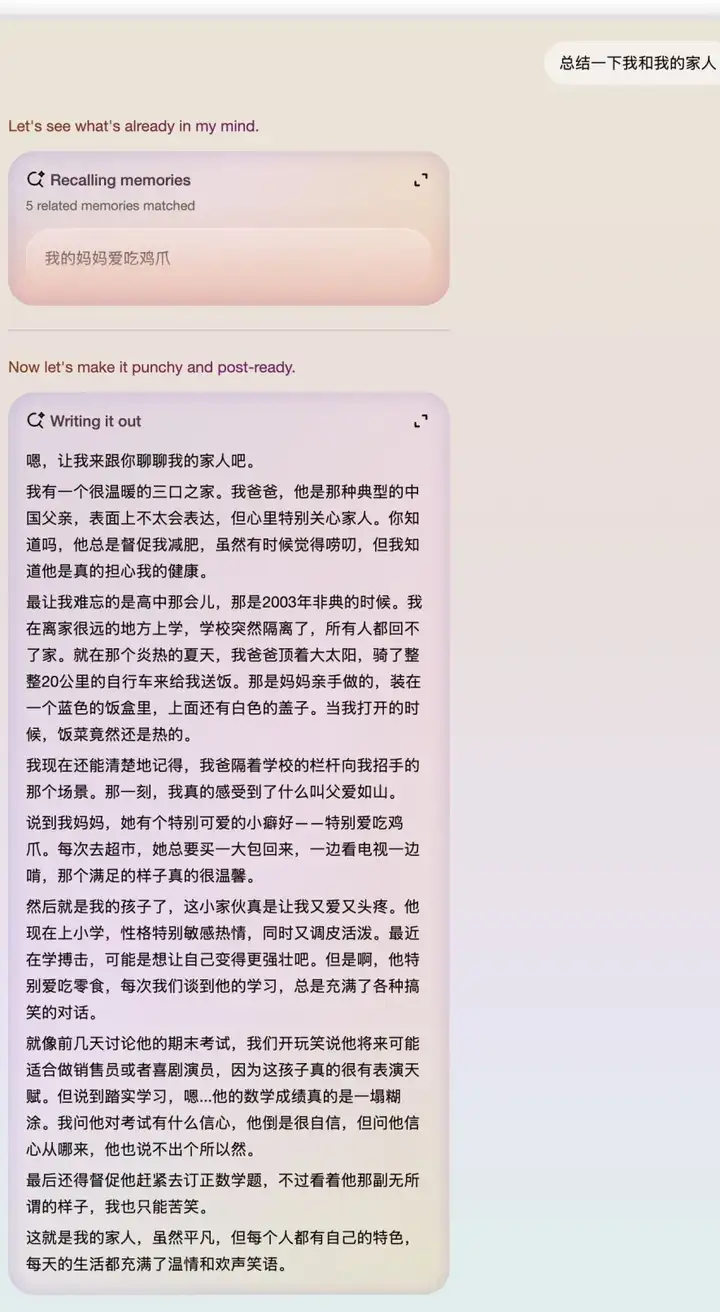
昨天跟 Me.bot 的好运聊过后,让我对 me.bot 的认识有了更深的理解,下面这段是好运发我的一段基于他的声音和个人知识库给我介绍 me.bot 的一段图文+语音的一个截图:

声音克隆应该是 Me.bot 的新功能,当你用自己克隆的声音去阅读创作的内容时,也别有一番感觉。
我知道有的小伙伴用 Me.bot 生成儿童绘本然后再用自己的克隆的声音把故事讲给自己的孩子听。

让我们进行一场宏大的思想实验:
假如从今天起,一个名叫Alex的年轻人,
开始将自己每天的重要记忆——他的所思所想、喜怒哀乐、工作进展、人际交往——连续不断地、忠实地上传到一个先进的AI记忆系统中。
这场长跑将持续80年,直到他生命的尽头。
80年后,会发生什么?
在最初的20年里,这个AI系统对Alex来说,是一个无与伦比的“第二大脑”。
随着数据的不断积累,AI的变化开始变得质的。它不再仅仅是一个记录工具。
进入暮年,Alex的生物记忆开始不可避免地衰退。而他的AI记忆系统,却正值巅峰。
我个人觉得无论如何这都是一个好的现象,我们会面临新的问题,而新的问题总会带来新的机会。
类似Me.bot 这样有趣的AI 产品让大家有机会去进行类似的深度体验和思考。
文章来自于“一支烟花AI”,作者“Brad强”。


【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
