# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
24 小时涌入超过 60 万用户,消耗了大模型十几亿 token,发生 2000 万次对话,而事情的起源却是一次吵架。
几个月前,当时我和女朋友因为我现在已经忘记的原因而有了一些争吵,我一边看着对方骂我的样子,一边把对方想象成一个机器人,头上有个虚拟的进度条,我观察她的反应,假装成我的回应会让她头上的进度条发生变化,然后我就突然想到了一个产品创意:带有数值和反馈系统的基于场景的聊天。
我很快开始构建一个叫哄哄模拟器的 iOS APP,在 APP 内,我把常见的情侣吵架场景放入其中,每次进入一个场景,例如「你吃了对象爱吃的丸子,她生气了」,你都需要在指定聊天次数内将对方(AI)哄好,是否哄好则由「原谅值」决定,其会随着你的每次聊天而发生变化。

很久以来,我已经体验过太多的「聊天AI」了,无论是通用且强大的 ChatGPT还是专注于角色扮演的 Character.ai,他们都很强,但对我来说还是有一个小遗憾:他们只是聊天。
在聊天之外,如果能再加上数值系统和各种判定,那么就可以做出更游戏化的体验,此时大模型不仅负担起了聊天的任务,也会负担起基于聊天来做数值规则的任务,这在大模型出现之前,是不可能的,数值系统也都是按照既定规则来写死的。
开发哄哄模拟器,是我的一次实验,我发现我确实可以让模型输出拟人的回复,也能做好数值的设计。
App 上线之后,我照例在能发的几个地方发了一下,虽然有些响应,但最终用户就几百个人,因为是我业余做的,所以我也没在意,就放在那里没管了。
上周,公司内开始做一些新项目的选型,我也凑过去看了一眼,然后突然意识到,我经常被人误认为是全栈工程师,但其实我连 react 都不会写,这实在脸上无光,于是我准备开始学习 react,我学习新语言一般会直接从项目上手,所以我又一次想到了哄哄模拟器,并准备写一个网页版,来完成我的 react 入门。
学习新语言和开发新产品的过程已经和往日大不相同,在大模型加持的各种代码助手辅助下,我基本上很快就稀里糊涂的写完了第一个版本,并上线了。

哄哄模拟器网页版上线之后,我也发在了几个地方,包括我的微博,即刻,X,还有V2ex,但说实话,都反响平平,虽然我暗自感觉不应该感兴趣的人这么少,但考虑到也没投入啥成本,还顺便学了新东西,倒也不觉得难受。
变化发生在第二天晚上,睡觉前我看了一眼数据,突然发现在线有上百人,我马上通过嵌入的统计代码查看流量来源,但发现都是无法被统计的,这意味着流量应该不是从某个网站链接导入,也不是从搜索引擎,我几乎每一刷新,涌入的用户就还会再增加一点,当晚我观察到接近1点才睡觉。
在我睡觉之前,我还是不知道流量从哪里来,以至于我发了一条动态感叹「像是从黑洞来的」

睡前我最后看了一眼数据,即时在线人数是 2000
第二天早上起床后,我立刻查看数据,发现在线人数已经飙到了 5000,日活用户到了接近 10 万,在短暂的陶醉后,我立马意识到大事不妙,哄哄模拟器背后使用的大模型基于 GPT,我调用了 openai 的 gpt3.5 接口,这里的成本是0.0015美元/1000个token,而一个晚上我就跑了一亿的 token,为此我要付出的是 150 美元
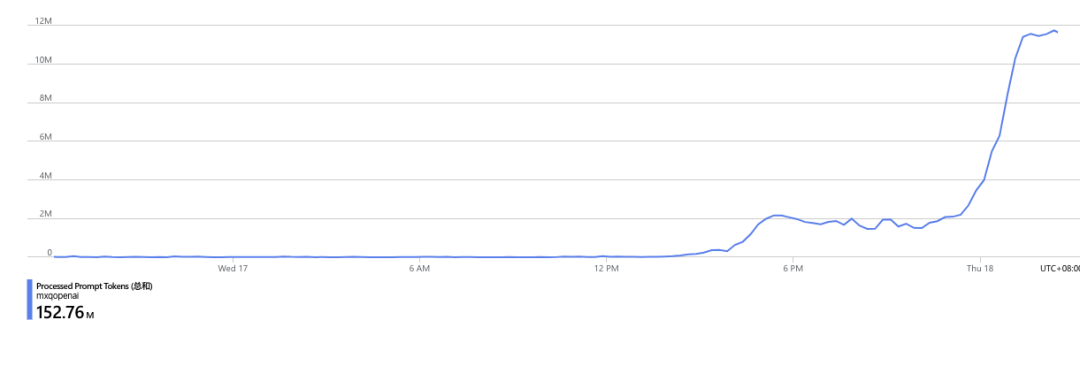
但这只是一个晚上(还包括了大家都在睡觉的凌晨)的数据,如果按照这样的用量趋势持续一天,那我要付出的成本就会是上千美元了。
对于一个很接近玩具且做的很简陋的项目而言,每天几千美元的成本是不可承受之重。与此同时,用户量还在不断增加,几乎每刷新统计页面,就会新增数百人。
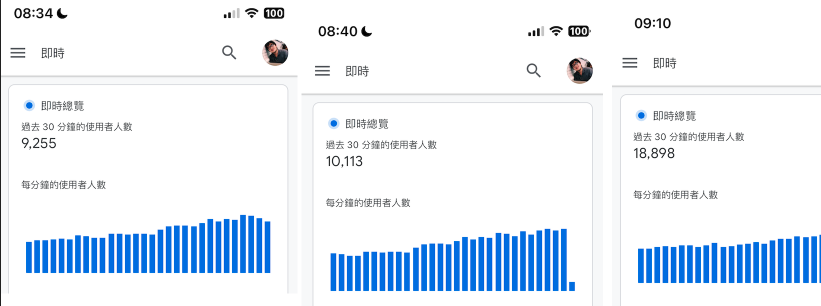
我一开始还在新高峰出现时截图,后来就懒得截了,我把精力放到了更紧迫的事情上面:找出用户从哪来,想办法变现,减少 token 消耗。
在网页上,我放置了联系开发者按钮,然后引导到了我的微博,半小时后,开始陆续有新的关注者评论,绝大部分都表示来自 QQ 空间和 QQ 群
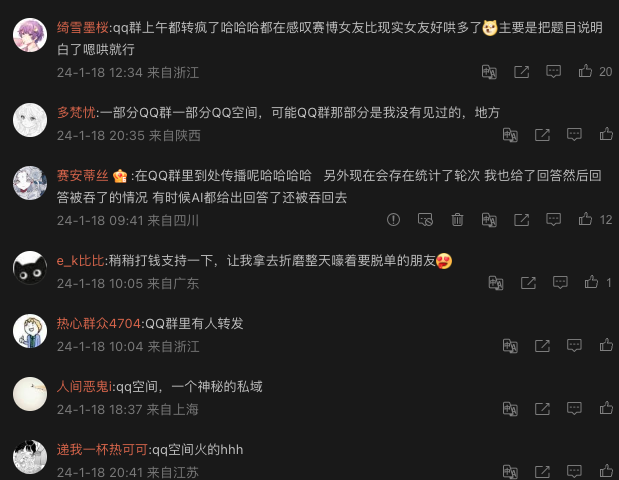
我和其中一些用户聊了一下,大概找到了流量来源,起先应该是一个来自QQ空间的帖子介绍了哄哄模拟器,这篇帖子获得了数千次转发,既而又被发到了无数QQ群,并在群友中传播。
这也解答了为啥我一开始找不到流量来源的原因,QQ空间和QQ群都是比较封闭的生态,也无法追踪链接跳转的来源,这里面没有 KOL,传播节点也极其分散。
等我中午时摸清用户来源的时候,用户即时在线已经突破了 2 万,预估的大模型账单也逼近了 1000 美元,我意识到,作为网页,且没有做注册登录的用户系统,即便我加入了广告,也无法平衡大模型的成本,和其它火起来的传统产品(例如羊了个羊)相比,基于大模型的哄哄模拟器,运行成本可能是它们的上千倍。
此时更棘手的一个情况出现了,因为大量的用户同时调用,把 GPT 接口的用量限制直接打满了,每分钟生成的 token 超过了一百万。
这让很多用户无法使用,于是我赶紧更新代码,用了粗暴的办法去降低用户的使用频率:1/2的概率,会提示繁忙,同时在用户完成一局对话后,如果哄哄失败,则必须冷静20秒才能开启下一局。
这样的调整让 TPM (每分钟的模型 token ) 稳在了100万,但很快,在线用户增加到了3万,即便有上面的设置,TPM 也依然被打满,这导致了大概有 1/3 的用户是无法使用的。
此时我选择性忽视了未来的大模型使用账单,一心想支撑下这波用户,于是我又找到了在奇绩创坛的校友尹伯昊,他是猴子无限的创始人,也有深度和 GPT 绑定的大模型相关的业务,他给了我一个API KEY,可以走他们的账号池调用GPT,并且支持极高的 TPM 限额,我将 1/2 的请求分配到了他的API下,此时用户也增长到了 4 万,但因为分流,所以勉强支撑了下来。
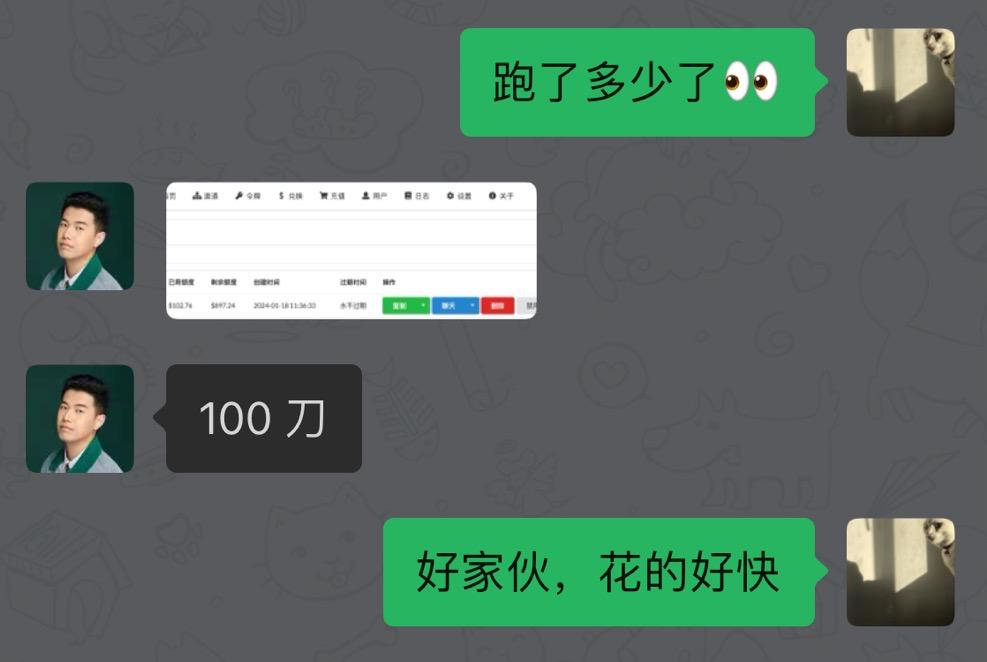
token 在两边都极速消耗,很快就在伯昊的账号下就跑了 100 美金的额度。而我自己那边我已经不想去看了。
缓一口气后,我开始尝试用其它模型替代 GPT ,这虽然在成本上不一定更划算,但至少有一些新的可能性,跑了几个差强人意的开源模型后,我尝试了 Moonshot,发现效果还可以,与此同时我刚好前不久加了月之暗面公司负责 API 的同学,于是我心一横,厚着脸皮直接向对方发了消息
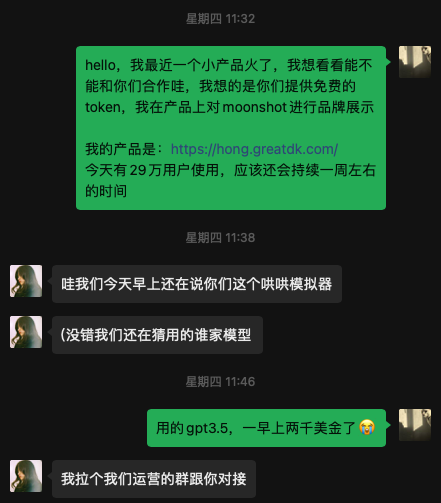
Moonshot 同学很快拉了群和我对接,并慷慨的让我「先试试」,于是我开始进行调试,然后将1/5的模型调用量切给了 Moonshot ,我采集用户行为数据,观察使用不同模型时,进入下一步操作的比例,在接入 Moonshot 大约1小时后,我看了数据,发现和我之前使用的 gpt3.5 相差不大,于是我将切给 Moonshot 的用量逐渐提高。
其实我们也没有谈太多的条件,Moonshot 让我免费使用模型,我肯定也要在页面展示 Moonshot 的品牌信息,但除此之外,要有多少曝光?点击多少次?给我多少token?其实我们都没有谈,在跟对方交流的时候,我感觉双方都抱着开放的心态,像面对一场有趣的实验而不是什么商业合作,我们一起兴致勃勃的观察模型表现,以及用量的波动。
傍晚时,经过多次调试,也确认了这个调用量级没问题后,我将模型调用量全量切到了 Moonshot,此时我问了伯昊,他那边的成本消耗,最终定格到了 340 美元,伯昊没收我钱,而我将用一顿饭回报这次帮忙。
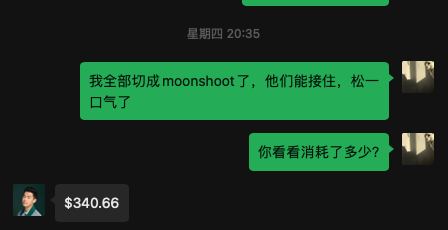
此时是晚上八点半,我终于吃上了当天的第一口饭。然后我打了一把 FIFA。
打完 FIFA 之后我回到电脑前,发现在线人数开始暴跌,此时我的心情比较复杂,一方面我对数据往下走有本能的失落,但又因为 token 消耗降低而松了一口气。而当我寻找数据下跌原因时,我发现这个原因丝毫不让人意外。
是腾讯屏蔽了哄哄模拟器的网页。
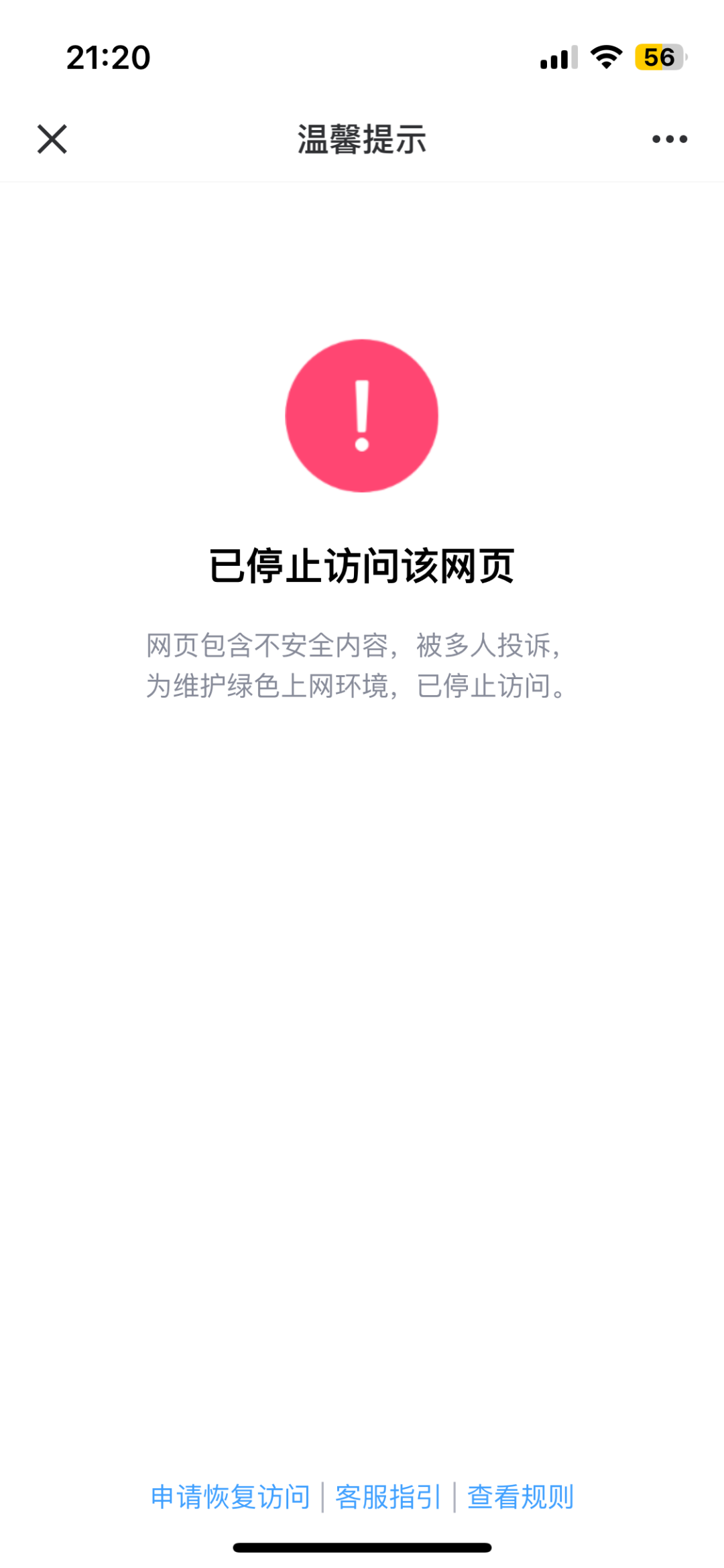
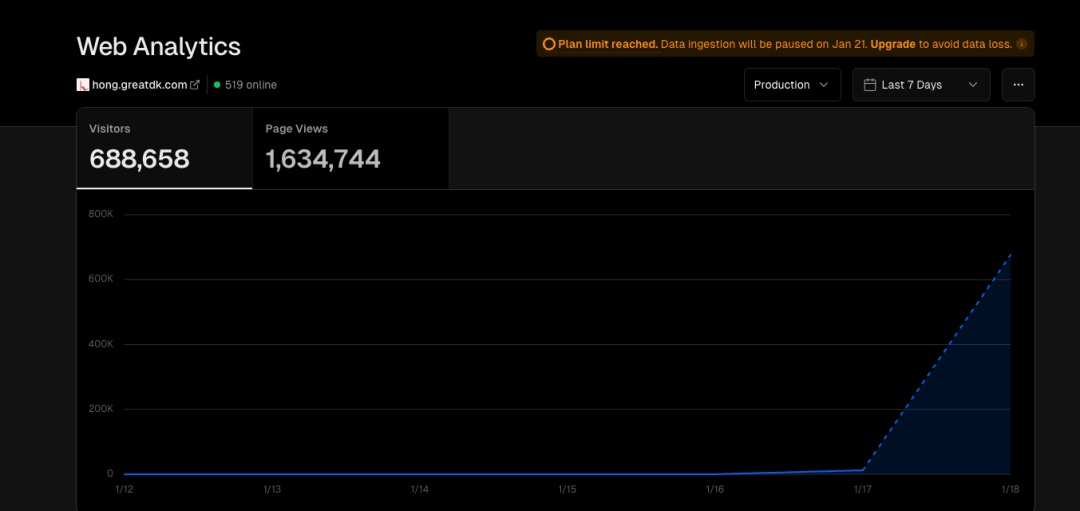
屏蔽发生在最活跃的晚上九点,此时最主要的传播链路——QQ和微信被拦腰斩断,大量抱着好奇心的用户被这个页面挡在了外面,流量以极快速度下滑,最终,当天涌入的用户一共是 68 万——如果没有屏蔽,在这个增速下,我想可能会过百万。
结合我自己的账号,Mooonshot,以及伯昊帮我分担的用量,总消耗的 token 达到了十五亿。
我当晚进行了申诉,第二天早上微信给我解封了,但十小时后,又进行了屏蔽——依然是在晚上最活跃的 9 点,在我申诉后又在次日早上解封,然后晚上继续屏蔽,过去几天这样大概重复了三四次,我也不明白为何要这样做——不给我个痛快,但流量在这样的折腾下迅速降低了。

微信生态素以严格著称,哄哄模拟器的流量激增可能触发了某种机制,也可能是某些用户故意引导模型输出出格内容后举报,让屏蔽不断发生,那个熟悉的画面,让我许多不愉快的记忆涌上心头。
但这一次,我其实没有那么不愉快,一方面我投入的并不多,说实话,这只是我做着玩的项目,同时我也知道,目前的哄哄模拟器,就是一个短期很难有商业回报的产品,它成本极高,而收益却极低——如果我不用非常极端的办法去恶心用户的话。
这样的一个产品,前途其实并不明朗。
但这个小产品,我观察到的数据,却给我带来了关于未来的某些希望——用户们很喜欢它,很多用户把我放置的关卡全部通关,还有人在全部通关之后有逐个进行最短回复的挑战,B站,抖音都出现了大量体验,游玩或者吐槽的视频。
值得注意的是,这些用户和我之前做产品所接触的用户完全不同,他们是以大学生,高中生和年轻人组成的,最大比例的年龄区间为16-20岁,我想这可能是一开始我用自己的渠道到处宣传效果并不好的原因,说到底,我已经快 30 岁了,我身边的很多人,也差不多这个年纪,30-40岁的用户,和十几二十岁的用户,感兴趣的点,需求,想法,都有很大不同。
用大模型去做某种更复杂的,更游戏化的聊天体验,能够被人喜欢,至少在年轻人这里,是得到了初步证明的,而之后的问题则是,如何降低成本,如何构建好的商业模式,以及如何拓展到更多的方向上,而对于这些,经此一役,我也有了不一样的感受。
我听到了一种声音,可能带了一点情绪,我不确定,这种声音是:做这样不赚钱还亏钱的东西完全是浪费时间。首先我承认并且赞同人应该想办法赚钱过上更好的生活,同时我也认为我们应该保有更多的一些能力,例如感受趣味,它和赚钱不矛盾,但独立于赚钱这件事情。
用最前沿的技术,巧妙的做一个让几十万人用上的产品是很有趣的事情,当他们也因为这个产品而获得了乐趣的时候,我会感觉到我在和世界发生某种奇妙的连接,在某个可承受的范围内,我不计较成本,正是因为这个。
另一方面,我也有某个模糊的感觉,那就是在许多小需求得到满足的时候,就不应该去计较短期的,在承受范围内的成本,尤其是在现在,能够用大模型去实现功能和解决问题,因为这里面可能蕴含着更大的需求,或者能转化成更大的事情,当我们太过谨慎的时候,可能就错失了这种可能性。
话说回来,就算那种可能性最后没有验证,那又有什么关系呢,说到底,人赚钱也好,生活也好,最终不过还是希望能够开心,做哄哄模拟器的这个过程,我就很开心,足矣。
文章来自于微信公众号 “超级王登科”,作者 “DK本人”



【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
