# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
去年,在加速大语言模型推理层面,我们迎来了一个比推测解码更高效的解决方案 —— 普林斯顿、UIUC 等机构提出的 Medusa。如今,关于 Medusa 终于有了完整技术论文,还提供了新的版本。
如你我所知,在大型语言模型(LLM)的运行逻辑中,随着规模大小的增加,语言生成的质量会随着提高。不过,这也导致了推理延迟的增加,从而对实际应用构成了重大挑战。
从系统角度来看,LLM 推理主要受内存限制,主要延迟瓶颈源于加速器的内存带宽而非算术计算。这一瓶颈是自回归解码的顺序性所固有的,其中每次前向传递都需要将完整的模型参数从高带宽内存传输到加速器缓存。该过程仅生成了单个的 token,没有充分利用现代加速器的算术计算潜力,导致了效率低下。
为了解决这一问题,加速 LLM 推理的方法被提出,既可以增加解码过程的算术强度(FLOPs 与总数据移动的比率),也能减少解码步骤数量。这类方法以推测解码(speculative decoding)为代表,使用较小的草稿(draft) 模型在每一步生成 token 序列,然后通过较大的原始模型进行细化以获得可接受的延续。不过获得合适的草稿模型仍然具有挑战性,并且将草稿模型集成到分布式系统中更加困难。
在本文中,来自普林斯顿大学、Together.AI、伊利诺伊大学厄巴纳 - 香槟分校等机构的研究者没有使用单独的草稿模型来顺序生成候选输出,而是重新审视并完善了在主干模型之上使用多个解码头加速推理的概念。他们发现,如果该技术得到有效应用,可以克服推测解码的挑战,从而无缝地集成到现有 LLM 系统中。
具体来讲, 研究者提出了 MEDUSA,一种通过集成额外解码头(能够同时预测多个 tokens)来增强 LLM 推理的方法。这些头以参数高效的方式进行微调,并可以添加到任何现有模型中。至此,不需要任何新模型,MEDUSA 就可以轻松地集成地当前的 LLM 系统中(包括分布式环境),以确保友好用户体验。
值得关注的是,该论文作者之一 Tri Dao 是近来非常火爆的 Transformer 替代架构 Mamba 的两位作者之一。他是 Together.AI 首席科学家,并即将成为普林斯顿大学计算机科学助理教授。

在具体实现中,研究者通过两个关键见解进一步增强了 MEDUSA。首先,当前在每个解码步骤生成单个候选延续的方法导致了可接受长度受限和计算资源的低效使用。为了解决这个问题,他们建议使用 MEDUSA 头来生成多个候选延续,并通过对注意力掩码的简单调整来进行验证。其次可以使用类似于推测解码中的拒绝采样方案来生成与原始模型具有相同分布的响应,但对于很多 LLM 应用来说通常不必要。
因此,研究者考虑或许可以引入一种典型的可接受方案,即从 MEDUSA 输出中选择合理的候选者。他们使用温度作为阈值来管理原始模型预测的偏差,为拒绝采样提供了一种有效的替代方案。这种方法有效地解决了拒绝采样的局限性,比如在较高温度下速度降低。
此外,为了给 LLM 配备预测性的 MEDUSA 头,研究者提出了两种针对不同场景量身定制的微调程序。对于计算资源有限或者目标是将 MEDUSA 纳入现有模型而不影响其性能的情况,他们建议使用 MEDUSA-1。该方法需要的内存最少,并且可以使用类似于 QLoRA 中的量化技术来进一步优化,而不会因固定主干模型影响生成质量。
不过,对于 MEDUSA-1,主干模型的全部潜力无法得到充分利用。因此可以进一步进行微调,以提高 MEDUSA 头的预测精度,并直接带来更大加速。因此研究者提出了 MEDUSA - 2,它适用于计算资源充足或从基础模型进行直接监督微调的场景。MEDUSA-2 的关键是一个训练协议,它能够对 MEDUSA 头和主干模型进行联合训练,而不会影响模型下一个 token 的预测能力和输出质量。
在实验部分,研究者主要关注批大小为 1 的场景,这代表了 LLM 本地托管以供个人使用的用例。他们在不同大小和训练设置下测试了 MEDUSA,包括 Vicuna-7B 和 13B(使用公共数据集训练)、Vicuna -33B(使用私有数据集训练)、Zephyr-7B(使用监督微调和对齐训练)。
结果表明,MEDUSA 在不影响生成质量的情况下,可以在不同的 promt 类型中实现 2.3 至 3.6 的推理加速。如下动图为 Vicuna-7b 上有无 Medusa-1 时推理速度比较。
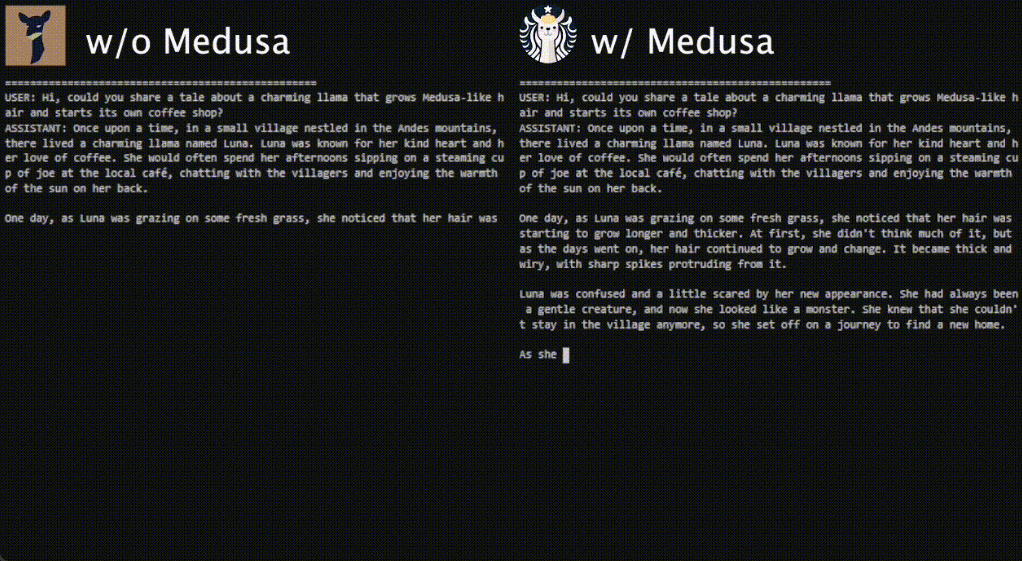
论文共同一作 Tianle Cai 表示,自 Medusa 项目推出以来,它在 TensorRT、TGI 以及众多开源项目和公司中得到采用。在新的技术论文中,我们推出了用于全模型调优的 Medusa-2 方案、用于将 Medusa 集成到任何微调 LLM 的自蒸馏以及其他更多加速技术。

对于这项研究,Lepton AI 创始人贾扬清表示,Medusa 可能是他们见过的最优雅的加速推理解决方案之一,能够与 int8/fp8、编译等互补,在实践中实现 2 倍性能增益。
并且,他们已将 Medusa 与很多现有优化方法、混合加速方案进行集成,结果在合理的并发下,加速保持正值,并在 A100 和 H100 等卡中尤其有效。此外,他们还已经为 Llama 模型训练了通用 Medusa 头。

MEDUSA 遵循推测解码框架,其中每个解码步骤主要由三个子步骤组成:(1) 生成候选者,(2) 处理候选者, (3) 接受候选者。对于 MEDUSA,(1) 是通过 MEDUSA 头(head)实现的,(2) 是通过树注意力(tree attention)实现的,并且由于 MEDUSA 头位于原始主干模型之上,因此 (2) 中计算的 logits 可以用于子步骤 (1) 的下一个解码步骤。最后一步 (3) 可以通过拒绝采样(rejection sampling)或典型接受(typical acceptance)来实现。MEDUSA 的整体流程如下图 1 所示。

关键组件
MEDUSA 的关键组件主要包括 MEDUSA 头和树注意力。
首先,MEDUSA 头与原始主干模型一起进行训练。其中,原始主干模型可以在训练期间保持冻结状态 (MEDUSA-1) 或一起训练 (MEDUSA-2)。这种方法甚至可以在单个 GPU 上微调大模型,利用强大的基础模型学得的表征。
此外,MEDUSA 头的分布确保与原始模型的分布一致,从而缓解了分布偏移问题,并且 MEDUSA 不会增加服务系统设计的复杂性,对分布式设置很友好。
由于候选者增加会提高计算需求,该研究采用树状结构的注意力机制来同时处理多个候选者。这种注意力机制不同于传统的因果注意力范式。在其框架内,只有来自同一 continuation 的 token 才被视为历史数据。受图神经网络领域提出的将图结构嵌入注意力的启发,研究团队还将树结构合并到注意力掩码中,如下图 2 所示。

训练策略
冻结主干模型来训练 MEDUSA 头的方法很简单,并且需要的计算资源很少,但是将主干网络与 MEDUSA 头结合训练可以显著提高 MEDUSA 头的准确性。因此,根据计算资源和用例的具体要求,研究团队为 MEDUSA 头提出了两个级别的训练策略,即 MEDUSA-1:冻结主干网络,MEDUSA-2:联合训练。
最后,该研究提出了 MEDUSA 的两个扩展,包括自蒸馏(self-distillation)和典型接受(typical acceptance),分别用于处理 MEDUSA 没有可用训练数据的情况和提高解码过程的效率。

为了证明 MEDUSA 在不同设置下的有效性,该研究进行了两组实验:首先,在 Vicuna-7B/13B 模型上评估 MEDUSA,以展示 MEDUSA-1 和 MEDUSA-2 的性能;其次,在 Vicuna-33B 和 Zephyr-7B 模型上评估 MEDUSA,以研究自蒸馏的有效性,因为 Vicuna-33B 模型的训练数据集不公开,而 Zephyr-7B 模型使用 RLHF 进行训练。
用例研究 1:在 Vicuna-7B/13B 模型上评估 MEDUSA
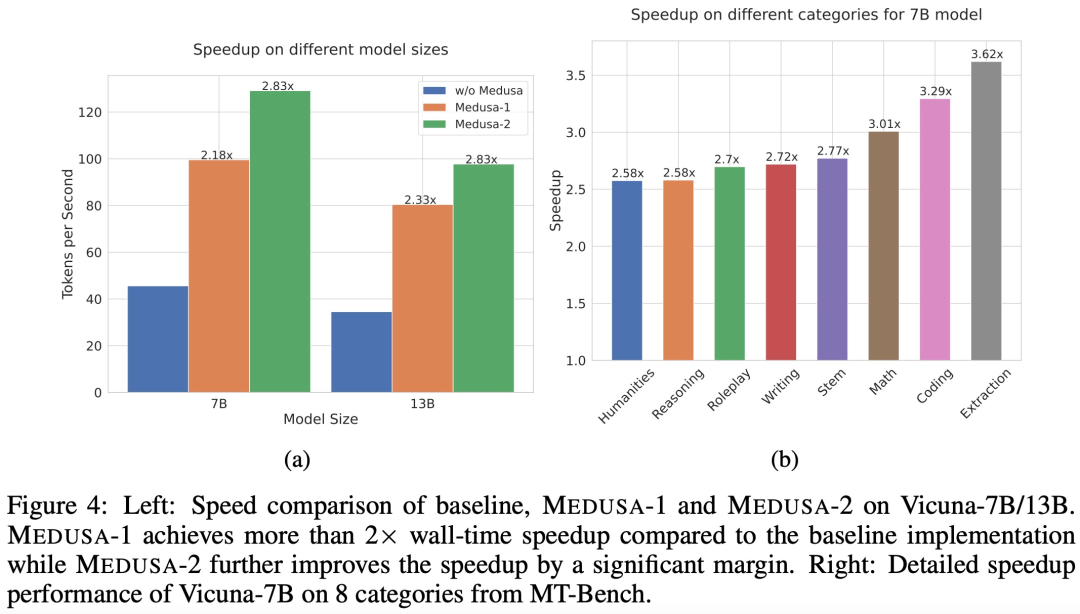
在 Vicuna-7B/13B 模型上评估 MEDUSA-1、MEDUSA-2 的结果如下图 4 所示。
用例研究 2:在 Vicuna-33B 和 Zephyr-7B 使用自蒸馏训练
研究者关注了需要自蒸馏的情况,使用 Vicuna-33B 和 Zephyr-7B 作为示例。他们首先使用一些种子 prompt 来生成数据集,然后将 ShareGPT 和 UltraChat 作为种子数据集,并为以上两个示例收集了包含大约 100k 样本的数据集。
下表 1 展示了不同 MEDUSA-2 模型在 MT-Bench 基准下的加速比、开销和质量。

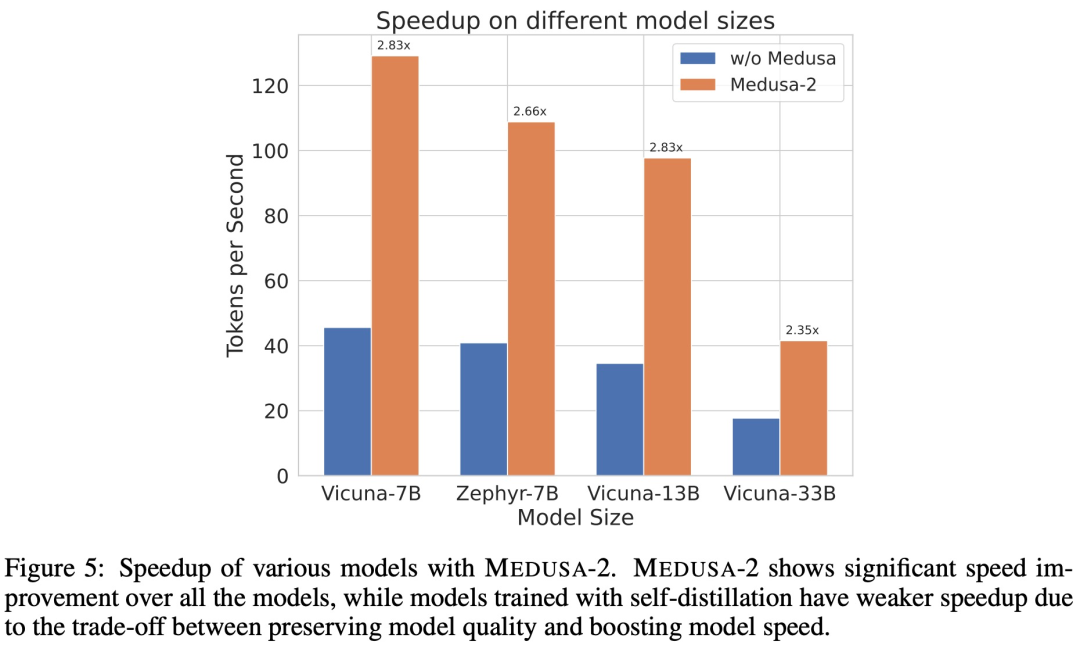
下图 5 为使用 MEDUSA-2 时不同模型的加速情况。
消融实验
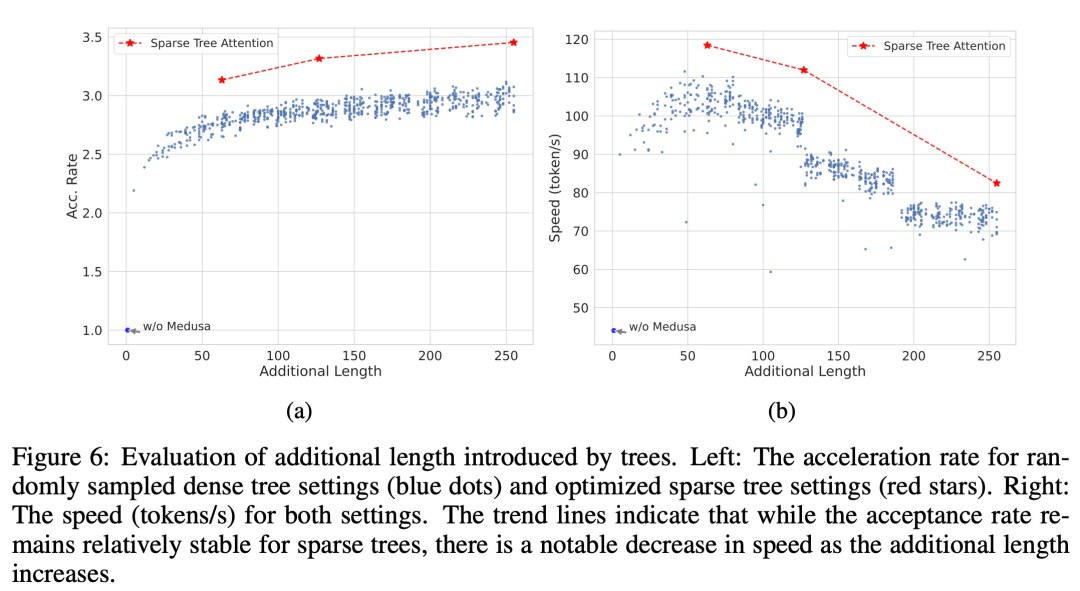
下图 6a 比较了随机采样密集树设置(蓝点)和优化稀疏树设置(红星)的加速率。6b 比较了密集和稀疏树设置的速度。
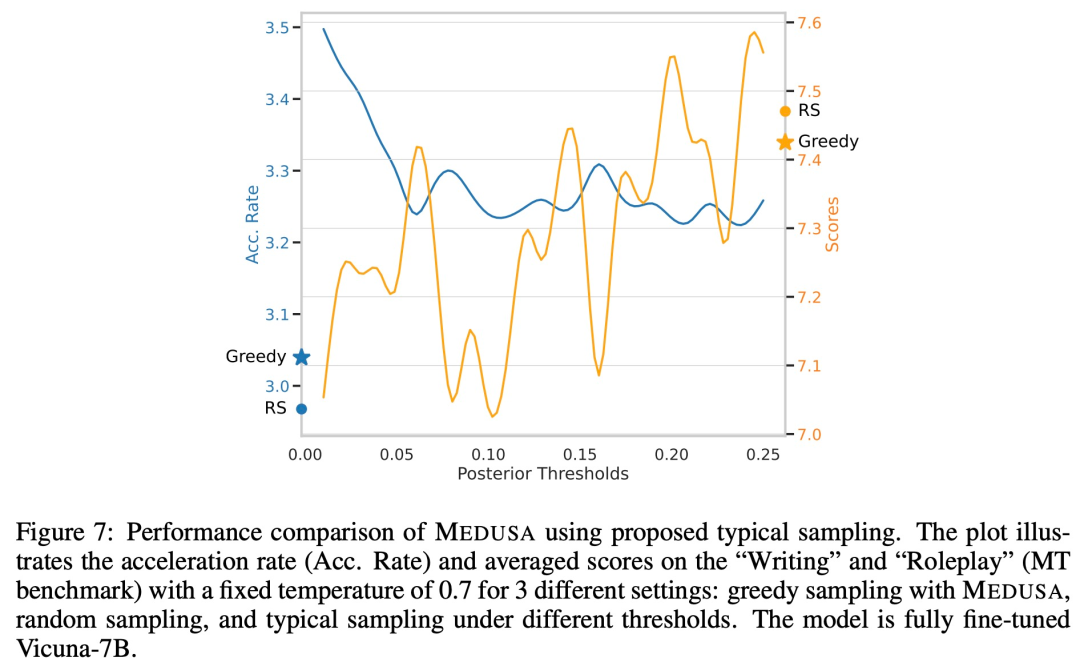
下图 7 展示了不同采样设置下,模型性能的比较分析。
两阶段微调的有效性。研究者针对 Vicuna-7B 模型,评估了两种微调策略下的性能差异。

文章来自于微信公众号 “机器之心”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
