# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
会操纵手机的智能体,又迎来了全新升级!
新的Agent打破了APP的界限,能够跨应用完成任务,成为了真·超级手机助手。
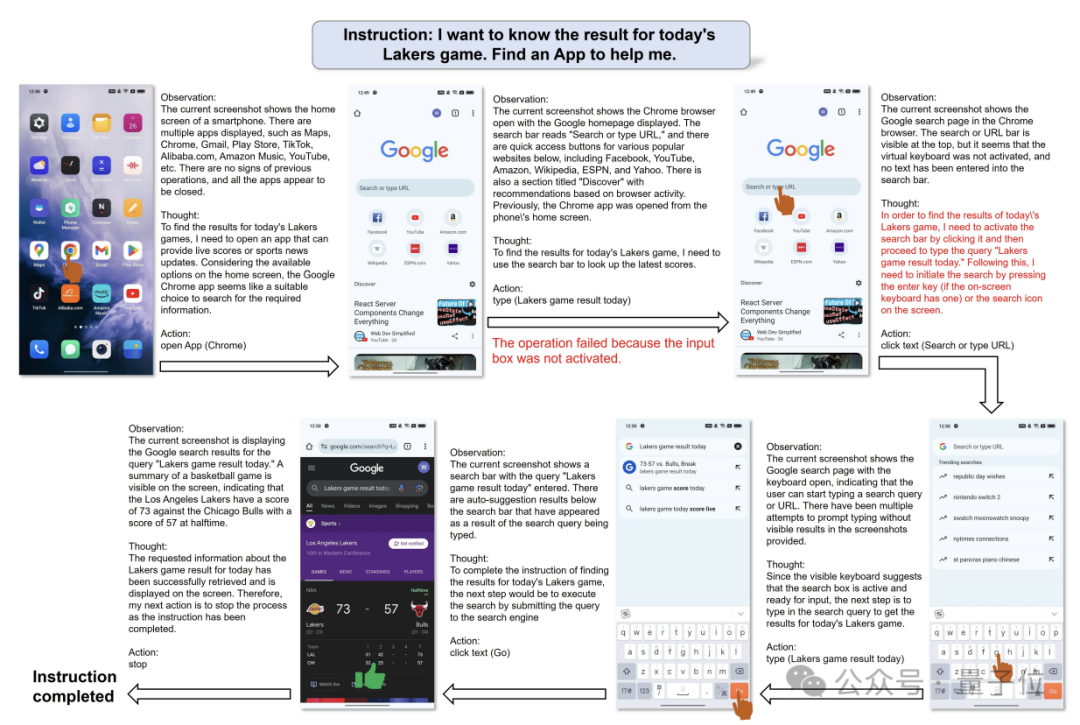
比如根据指示,它可以自行搜索篮球比赛的结果,然后根据赛况在备忘录中撰写文稿。
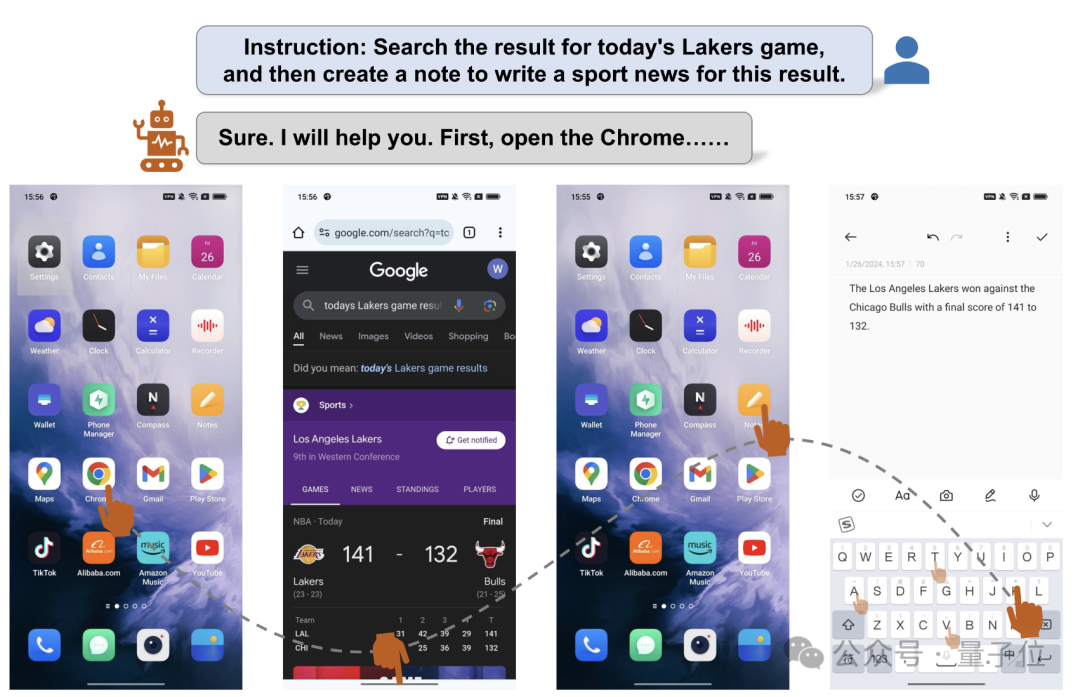
来自阿里的一篇最新论文,展示了全新手机操纵智能体框架Mobile-Agent,可以玩转10款应用,还能跨越APP完成用户交给的任务,而且即插即用无需训练。
依托多模态大模型,整个操纵过程完全基于视觉能力实现,不再需要给APP编写XML操作文档。
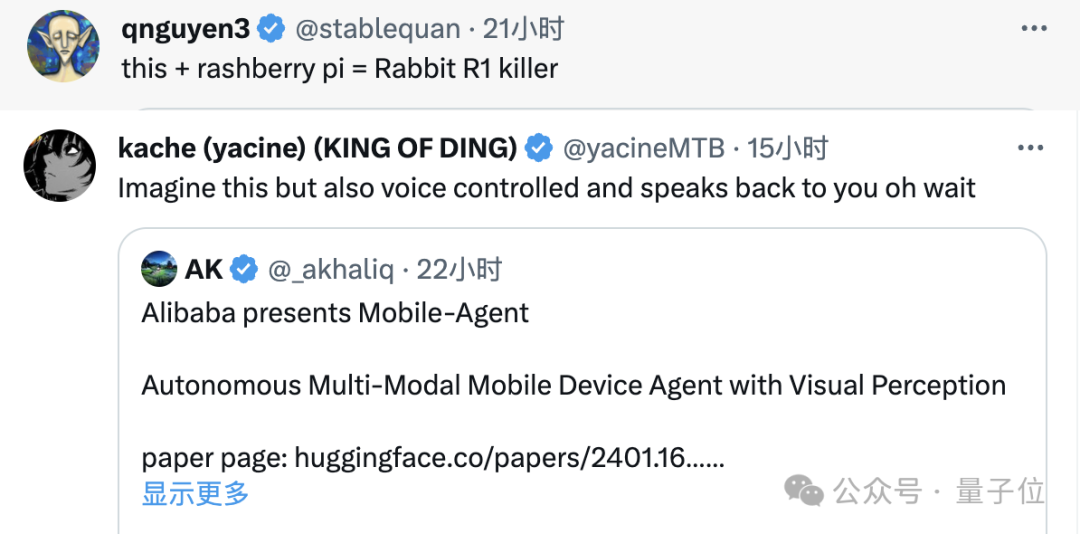
在Mobile-Agent还只有演示视频的时候,就已经让一众网友为之惊艳:
和树莓派结合到一起,将完爆Rabbit R1(一款大模型硬件)。
想象一下如果它支持语音操纵,并且学会了说话……
那么,Mobile-Agent操纵手机到底有多6呢?
目前,Mobile-Agent已经学会了十个APP的操作,以及一些跨应用任务。
比如搜索导航路线、帮忙在购物网站下单,它总能精准找到搜索框并完成目标。
也可以“刷”视频,然后点赞评论,看上去就像熟练的老手。
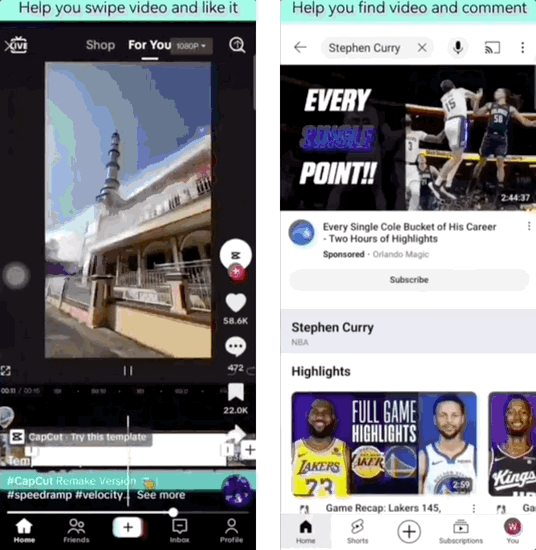
甚至是安装应用、修改系统设置,也难不倒它。
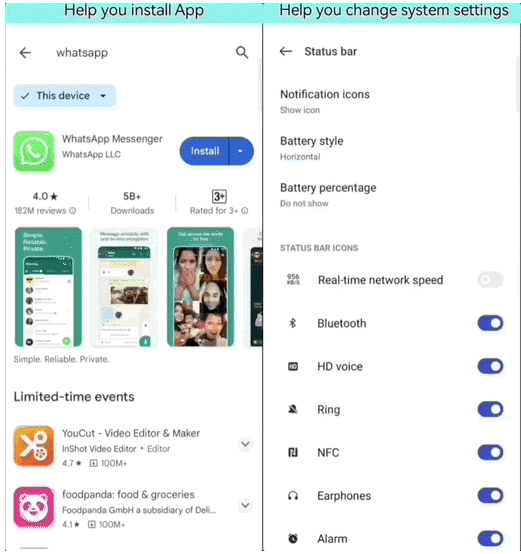
而Mobile-Agent支持的跨应用操作,也是让“手机助手”更加接近人类……
只见它打开天气预报软件,然后迅速根据读取到的天气数据在备忘录中生成了报告。
而在Mobile-Eval数据集上的测试结果也显示,Mobile-Agent操纵手机的效率已经达到了人类的80%。
研究人员在10款APP和跨应用任务上各测试了三种指令,收集了是否成功(SU)、操作评分(PS)、相对效率(RE)和完成率(CR)四项指标。
其中SU只有成功和不成功两种情况,RE是Agent所需操作步骤数和人类所需步骤数的比值,CR则是Agent相对于人类操作的完成比例,PS则以打分形式得出。
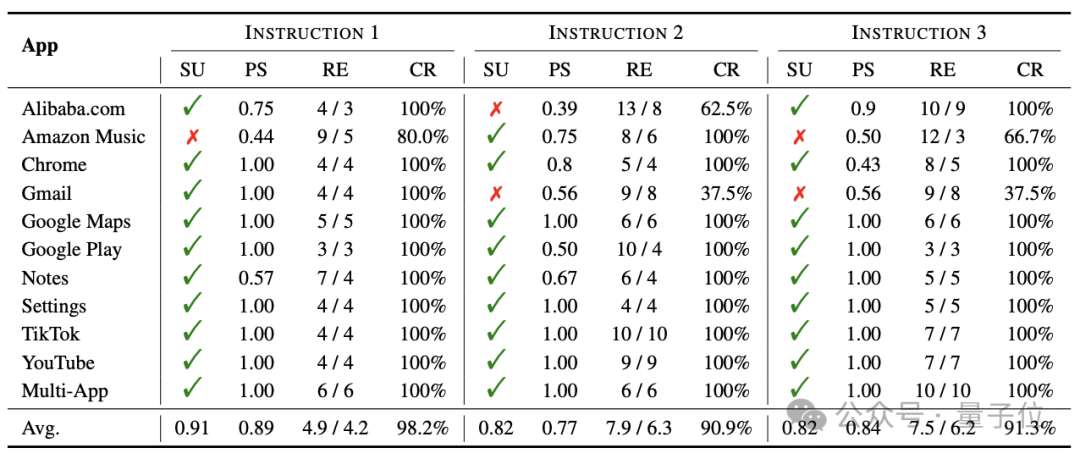
结果,针对三种指令,Mobile-Agent的平均完成率都在90%以上,成功次数也不低于80%。
而且,与此前的智能体不同,Mobile-Agent不需要依赖应用说明文档,而是完全依靠视觉能力实现。
具体来说,Mobile-Agent基于最强多模态大模型GPT-4V实现。
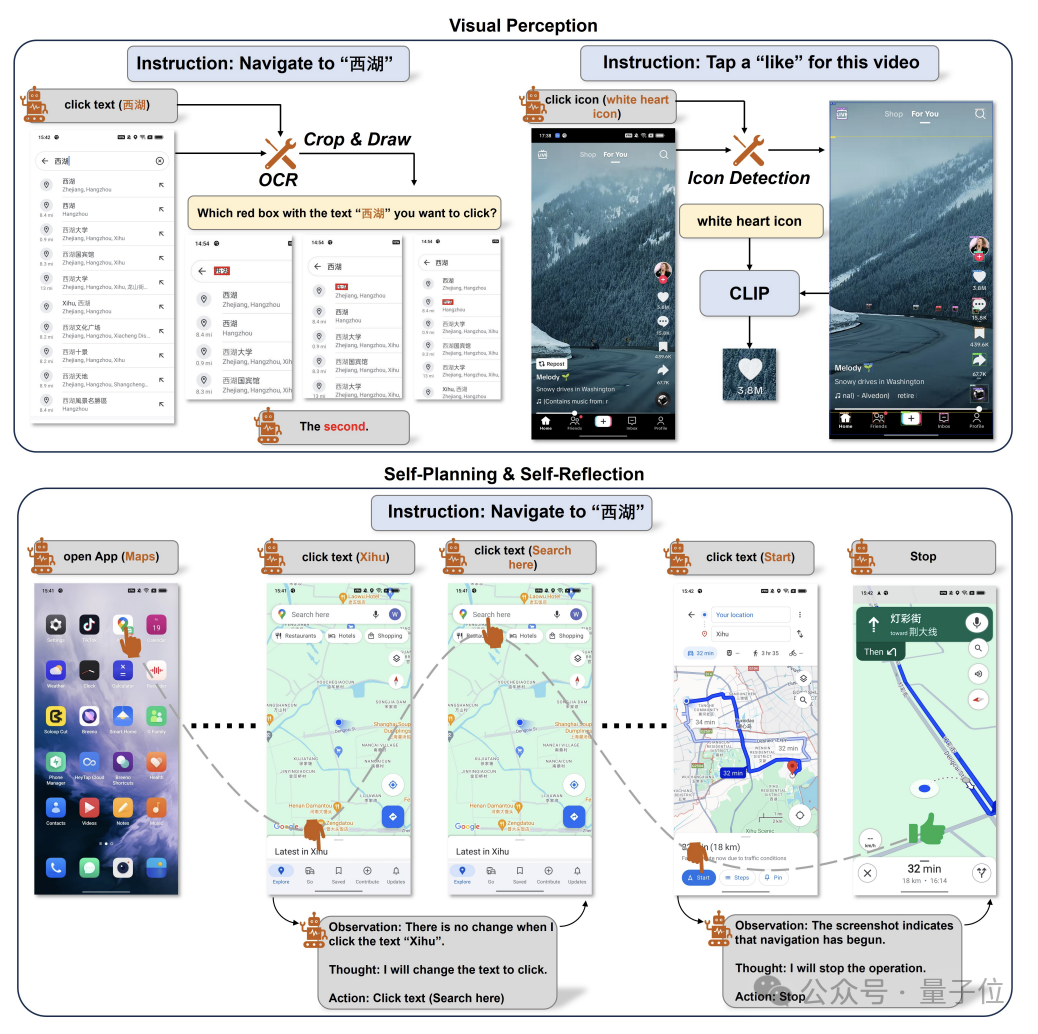
通过视觉感知模块,Mobile-Agent从设备的屏幕截图中准确定位视觉和文本元素文本和图标。
这一过程涉及到使用OCR工具和CLIP模型来确定图标的位置。
通过这些视觉信息,Mobile-Agent能够将语言模型生成的操作指令映射到具体的屏幕位置,从而执行点击等操作。
在执行任务时,Mobile-Agent首先接收用户的指令,然后根据当前屏幕截图、操作历史和系统提示生成下一步操作。
这个过程是迭代进行的,直到任务完成。

Mobile-Agent还具备自我规划能力,能够根据操作历史和系统提示自主规划新的任务。
此外,它还引入了自我反思机制,在执行过程中,如果遇到错误或无效操作,它会根据屏幕截图和操作历史进行反思,尝试替代操作或修改当前操作的参数。

目前,研究人员已经在GitHub中开源了Mobile-Agent测试过程中生成的指令记录,程序代码也已经发布,未来还计划推出APP版本。
感兴趣的小伙伴可以试一试了~
GitHub主页:
https://github.com/X-PLUG/MobilAgent
论文地址:
https://arxiv.org/abs/2401.16158




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
