# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta第二代自研AI芯片Artemis,今年正式投产!
据悉,新的芯片将被用于数据中心的推理(Inference)任务,并与英伟达等供应商的GPU一起协同工作。
对此,Meta的发言人表示:「我们认为,我们自主开发的加速器将与市面上的GPU相得益彰,为Meta的任务提供最佳的性能与效率平衡。」
除了更高效地运行的推荐模型外,Meta还需要为自家的生成式AI应用,以及正在训练的GPT-4开源竞品Llama 3提供算力。

Meta的AI贴纸功能,此前在Messenger、Instagram和WhatsApp上都处于测试阶段
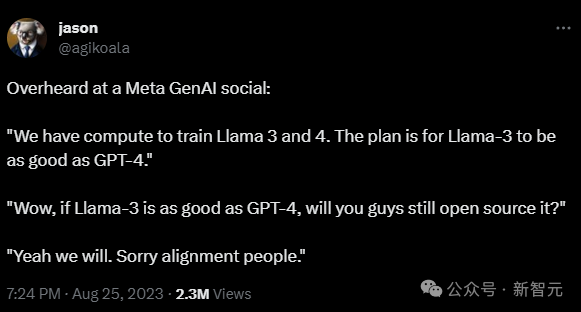
OpenAI工程师Jason Wei在Meta的一次AI活动中听到,Meta现在有足够的算力来训练Llama 3和4。Llama 3计划达到GPT-4的性能水平,但仍将免费提供
不难看出,Meta的目标非常明确——在减少对英伟达芯片依赖的同时,尽可能控制AI任务的成本。
Meta CEO小扎最近宣布,他计划到今年年底部署35万颗英伟达H100 GPU,总共将有约60万颗GPU运行和训练AI系统。
这也让Meta成为了继微软之后,英伟达最大的已知客户。

小扎表示,目前Meta内部正在训练下一代模型Llama 3。
在35万块H100上训练的Llama 3,无法想象会有多大!


Omdia的研究数据显示,Meta在2023年H100的出货量为15万块,与微软持平,且是其他公司出货量的3倍。
小扎称,「如果算上英伟达A100和其他AI芯片,到2024年底,Meta将拥有近60万个GPU等效算力」。
性能更强、尺寸更大的模型,导致更高的AI工作负载,让成本直接螺旋式上升。
据《华尔街日报》的一位匿名人士称,今年头几个月,每有一个客户,微软每月在Github Copilot上的损失就超过20美元,甚至某些用户每月的损失高达80美元,尽管微软已经向用户收取每月10美元的费用。
之所以赔钱,是因为生成代码的AI模型运行成本高昂。如此高的成本,让大科技公司们不得不寻求别的出路。
除了Meta之外,OpenAI和微软也在试图打造自己专有的AI芯片以及更高效的模型,来打破螺旋式上升的成本。

此前外媒曾报道,Sam Altman正计划筹集数十亿美元,为OpenAI建起全球性的半导体晶圆厂网络,为此他已经在和中东投资者以及台积电谈判
去年5月,Meta首次展示了最新芯片系列——「Meta训练和推理加速器」(MTIA),旨在加快并降低运行神经网络的成本。
MTIA是一种ASIC,一种将不同电路组合在一块板上的芯片,允许对其进行编程,以并行执行一项或多项任务。

内部公告称,Met首款芯片将在2025年投入使用,同时数据中心开启测试。不过,据路透社报道,Artemis已经是MTIA的更高级版本。
其实,第一代的MITA早就从2020年开始了,当时MITA v1采用的是7nm工艺。
该芯片内部内存可以从128MB扩展到128GB,同时,在Meta设计的基准测试中,MITA在处理中低复杂度的AI模型时,效率要比GPU还高。
在芯片的内存和网络部分,Meta表示,依然有不少工作要做。
随着AI模型的规模越来越大,MITA也即将遇到瓶颈,因此需要将工作量分担到多个芯片上。
当时,Meta团队还设计了第一代MTIA加速器,同样采用台积电7nm,运行频率为800MHz,在INT8精度下提供102.4 TOPS,在FP16精度下提供51.2 TFLOPS。它的热设计功耗(TDP)为25W。

2022年1月,Meta还推出了超算RSC AI,并表示要为元宇宙铺路。RSC包含2000个英伟达DGX A100系统,16000个英伟达A100 GPU。
这款超算与Penguin Computing、英伟达和Pure Storage合作组装,目前已完成第二阶段的建设。

参考资料:
https://www.reuters.com/technology/meta-deploy-in-house-custom-chips-this-year-power-ai-drive-memo-2024-02-01/
https://the-decoder.com/meta-deploys-its-artemis-ai-chip-to-reduce-reliance-on-nvidia-gpus/
文章来自于微信公众号 “新智元”



