# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
超越 Claude、GPT-3.5,提升了多语言支持能力。
赶在春节前,通义千问大模型(Qwen)的 1.5 版上线了。今天上午,新版本的消息引发了 AI 社区关注。
新版大模型包括六个型号尺寸:0.5B、1.8B、4B、7B、14B 和 72B,其中最强版本的性能超越了 GPT 3.5、Mistral-Medium,包括 Base 模型和 Chat 模型,且有多语言支持。
阿里通义千问团队表示,相关技术也已经上线到了通义千问官网和通义千问 App。
除此以外,今天 Qwen 1.5 的发布还有如下一些重点:
借助更先进的大模型作为评委,通义千问团队在两个广泛使用的基准 MT-Bench 和 Alpaca-Eval 上对 Qwen1.5 进行了初步评估,评估结果如下:
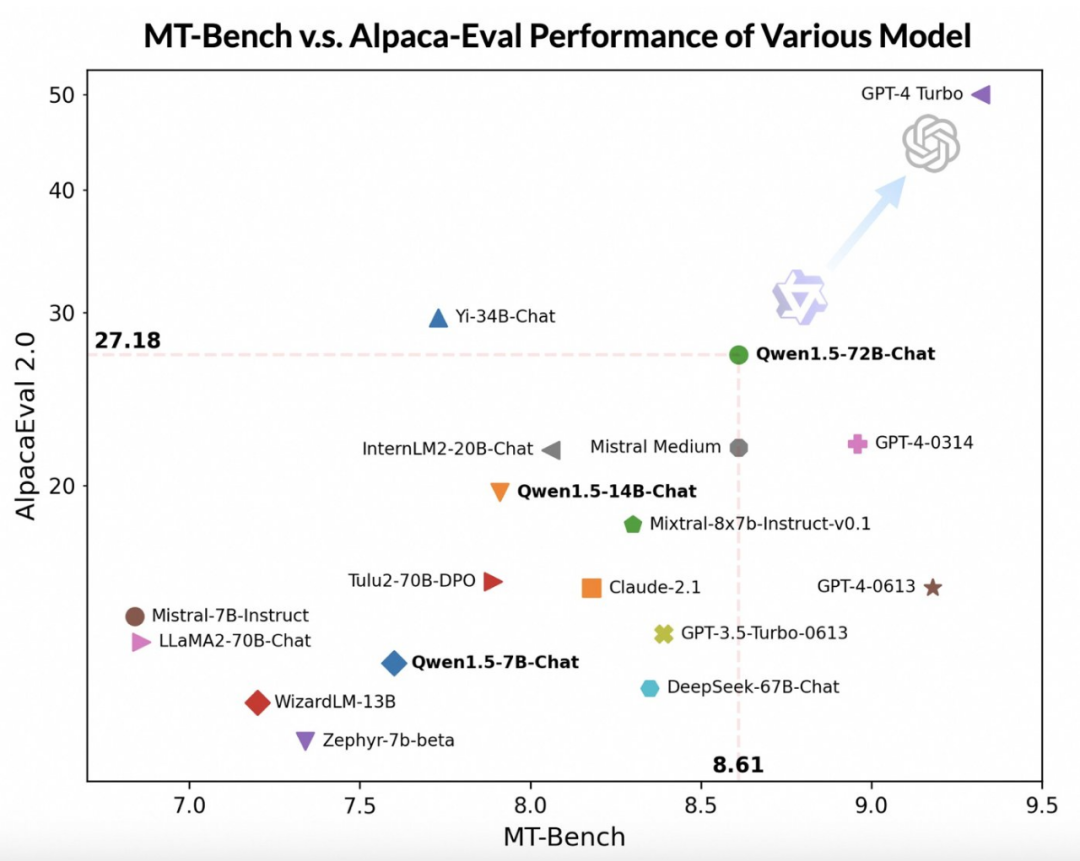
尽管落后于 GPT-4-Turbo,但最大版本的 Qwen1.5 模型 Qwen1.5-72B-Chat 在 MT-Bench 和 Alpaca-Eval v2 上都表现出了可观的效果,性能超过 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B,与最近热门的新模型 Mistral Medium 不相上下。
此外通义千问团队表示,虽然大模型判断的评分似乎与回答的长度有关,但人类观察结果表明 Qwen1.5 并没有因为产生过长的回答来影响评分。AlpacaEval 2.0 上 Qwen1.5-Chat 的平均长度为 1618,与 GPT-4 的长度一致,比 GPT-4-Turbo 短。
通义千问的开发者表示,最近几个月,他们一直在专注探索如何构建一个真正「卓越」的模型,并在此过程中不断提升开发者的使用体验。

相较于以往版本,本次更新着重提升了 Chat 模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个 tokens 的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中为人们带来更佳体验。
关于模型基础能力的评测,通义千问团队在 MMLU(5-shot)、C-Eval、Humaneval、GS8K、BBH 等基准数据集上对 Qwen1.5 进行了评估。

在不同模型尺寸下,Qwen1.5 都在评估基准中表现出强大的性能,72B 的版本在所有基准测试中都超越了 Llama2-70B,展示了其在语言理解、推理和数学方面的能力。
最近一段时间,小型模型的构建是业内热点之一,通义千问团队将模型参数小于 70 亿的 Qwen1.5 模型与社区中重要的小型模型进行了比较:

在参数规模低于 70 亿的范围内 Qwen1.5 与业界领先的小型模型相比具有很强的竞争力。
在来自欧洲、东亚和东南亚的 12 种不同语言上,通义千问团队评估了 Base 模型的多语言能力。从开源社区的公开数据集中,阿里研究者构建了如下表所示的评测集合,共涵盖四个不同的维度:考试、理解、翻译、数学。下表提供了每个测试集的详细信息,包括其评测配置、评价指标以及所涉及的具体语言种类。

详细的结果如下:

上述结果表明,Qwen1.5 Base 模型在 12 种不同语言的多语言能力方面表现出色,在学科知识、语言理解、翻译、数学等各个维度的评估中,均展现了不错的结果。更进一步地,在 Chat 模型的多语言能力上,可以观察到如下结果:

随着长序列理解的需求不断增加,阿里在新版本上提升了千问模型的相应能力,全系列 Qwen1.5 模型支持 32K tokens 的上下文。通义千问团队在 L-Eval 基准上评估了 Qwen1.5 模型的性能,该基准衡量了模型根据长上下文生成响应的能力。结果如下:

从结果来看,即使像 Qwen1.5-7B-Chat 这样的小规模模型,也能表现出与 GPT-3.5 可比较的性能,而最大的模型 Qwen1.5-72B-Chat 仅略微落后于 GPT4-32k。
值得一提的是,以上结果仅展示了 Qwen 1.5 在 32K tokens 长度下的效果,并不代表模型最大只能支持 32K 长度。开发者可以在 config.json 中,将 max_position_embedding 尝试修改为更大的值,观察模型在更长上下文理解场景下,是否可以实现令人满意的效果。
如今,通用语言模型的一大魅力在于其与外部系统对接的潜在能力。RAG 作为一种在社区中快速兴起的任务,有效应对了大语言模型面临的一些典型挑战,如幻觉、无法获取实时更新或私有数据等问题。此外,语言模型在使用 API 和根据指令及示例编写代码方面,展现出了强大的能力。大模型能够使用代码解释器或扮演 AI 智能体,发挥出更为广阔的价值。
通义千问团队对 Qwen1.5 系列 Chat 模型在 RAG 任务上的端到端效果进行了评估。评测基于 RGB 测试集,是一个用于中英文 RAG 评估的集合:


然后,通义千问团队在 T-Eval 基准测试中评估了 Qwen1.5 作为通用智能体运行的能力。所有 Qwen1.5 模型都没有专门面向基准进行优化:


为了测试工具调用能力,阿里使用自身开源的评估基准测试模型正确选择、调用工具的能力,结果如下:

最后,由于 Python 代码解释器已成为高级 LLM 越来越强大的工具,通义千问团队还在之前开源的评估基准上评估了新模型利用这一工具的能力:

结果表明,较大的 Qwen1.5-Chat 模型通常优于较小的模型,其中 Qwen1.5-72B-Chat 接近 GPT-4 的工具使用性能。不过,在数学解题和可视化等代码解释器任务中,即使是最大的 Qwen1.5-72B-Chat 模型也会因编码能力而明显落后于 GPT-4。阿里表示,会在未来的版本中,在预训练和对齐过程中提高所有 Qwen 模型的编码能力。
Qwen1.5 与 HuggingFace transformers 代码库进行了集成。从 4.37.0 版本开始,开发者可以直接使用 transformers 库原生代码,而不加载任何自定义代码(指定 trust_remote_code 选项)来使用 Qwen1.5。
在开源生态上,阿里已经与 vLLM、SGLang(用于部署)、AutoAWQ、AutoGPTQ(用于量化)、Axolotl、LLaMA-Factory(用于微调)以及 llama.cpp(用于本地 LLM 推理)等框架合作,所有这些框架现在都支持 Qwen1.5。Qwen1.5 系列目前也可以在 Ollama 和 LMStudio 等平台上使用。
参考内容:
https://qwenlm.github.io/blog/qwen1.5/
文章来自于微信公众号 “机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
