# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
来自上海人工智能实验室、西北工业大学、香港中文大学、北京大学、香港科技大学等机构的研究者提出了 AR3D-R1,这是首个强化学习增强的文本到 3D 自回归模型。该工作系统研究了奖励设计、RL 算法和评估基准,并提出 Hi-GRPO——一种层次化强化学习范式,通过分离全局结构推理与局部纹理精修来优化 3D 生成。同时引入全新基准 MME-3DR,用于评估 3D 生成模型的隐式推理能力。
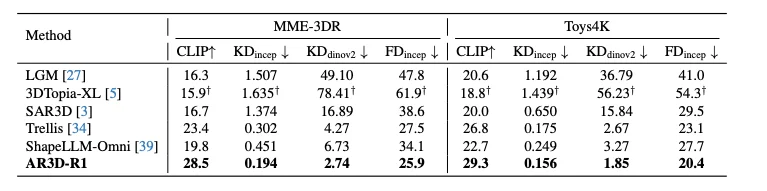
实验表明 AR3D-R1 在 Kernel Distance 和 CLIP Score 上均取得显著提升,达到 0.156 和 29.3 的优异成绩。

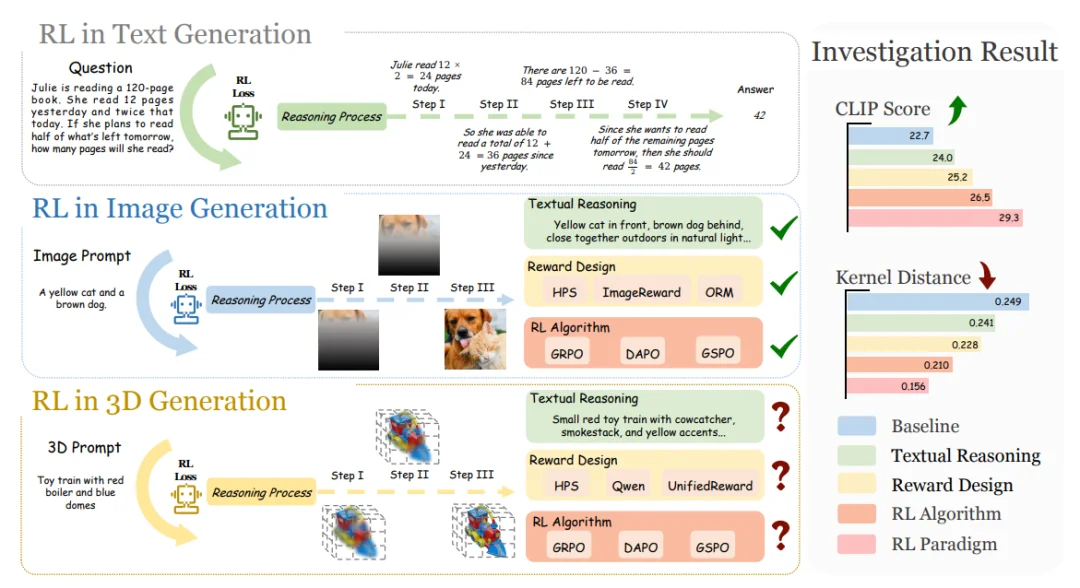
强化学习在大语言模型(如 DeepSeek-R1)和 2D 图像生成中已被证明能够有效提升模型性能,但将 RL 应用于 3D 生成仍面临独特挑战:
在此前的工作中,3D 模型大多停留在「预训练 + 微调」框架,真正将 RL 引入 3D 生成的一步,还无人系统迈出。
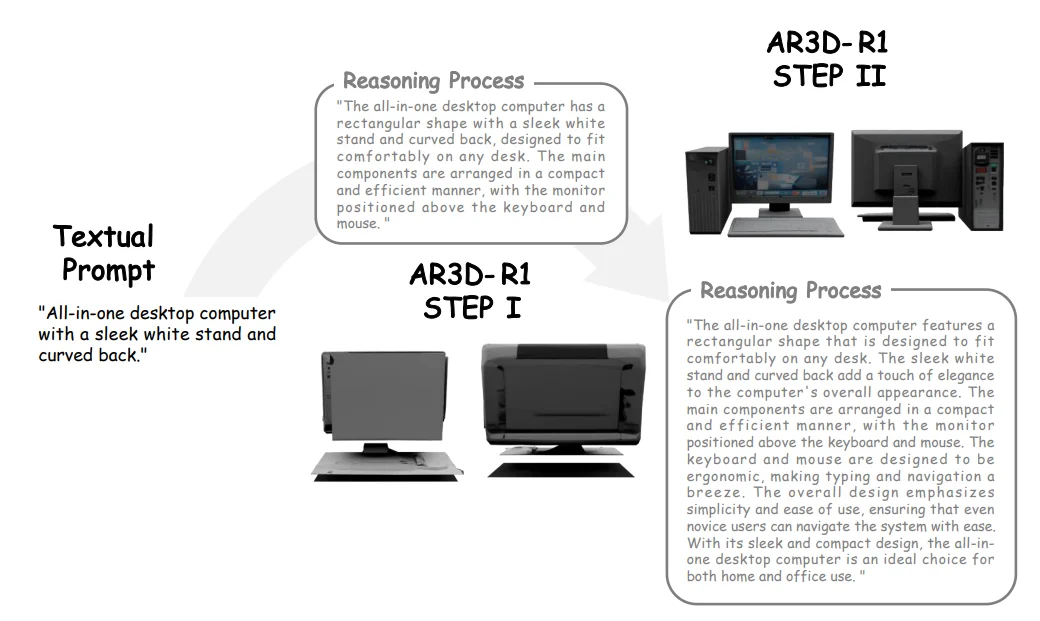
AR3D-R1 构建在离散 3D 生成模型 ShapeLLM-Omni 之上,引入了一个推理驱动的 3D 生成流程:
这让 AR3D-R1 不再是「凭本能画 3D」,而是先构思、再搭骨架、最后上细节——真正把 RL 驱动的「会想」能力,迁移到了「会造」的 3D 世界里。
在奖励设计方面,研究者评估了多个奖励维度和模型选择,得出以下关键发现:

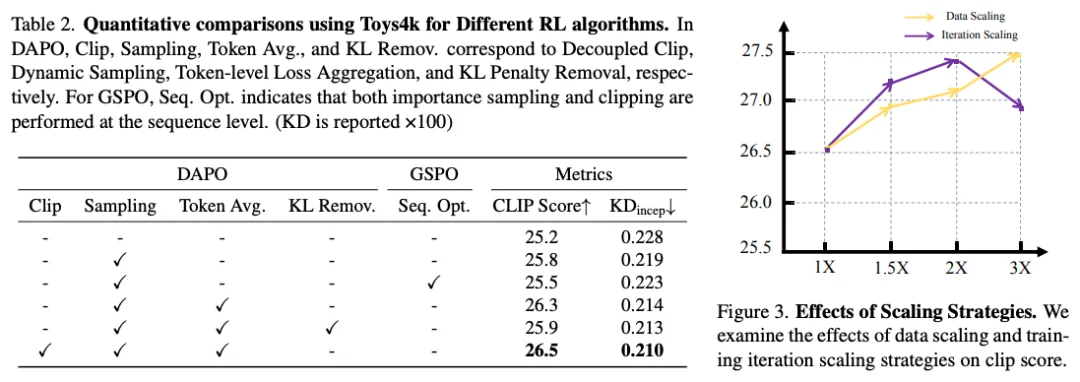
在 RL 算法研究方面,研究者深入分析了 GRPO 的多个变体,包括标准 GRPO、引入 token 级平均与动态采样的 DAPO,和更偏序列级操作的 GSPO 等:
这些发现为 3D 生成中的 RL 应用提供了系统性指导。
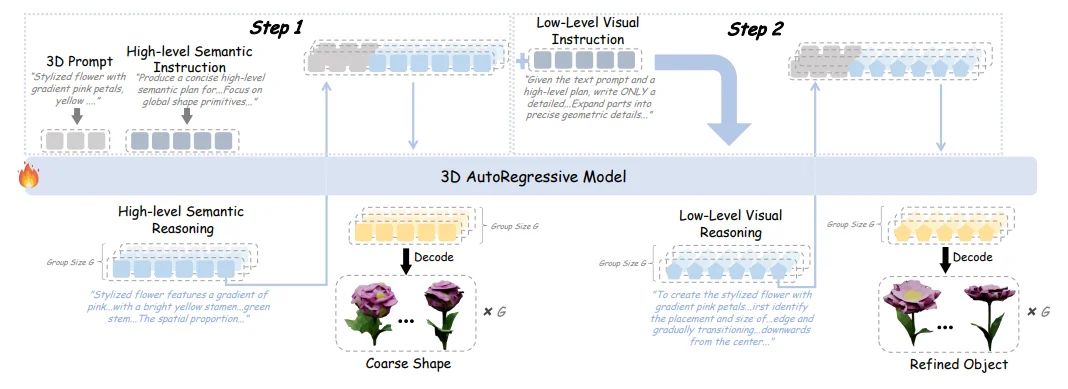
受 3D 生成自然层次结构的启发——模型首先构建全局几何,然后精修局部纹理(这与人类 3D 感知过程一致),研究者提出了 Hi-GRPO(Hierarchical GRPO)层次化强化学习范式。
Hi-GRPO 的核心思想是在单次迭代中联合优化层次化 3D 生成:
通过这种层次化设计,Hi-GRPO 能够在保证全局几何一致性的同时,精细优化局部纹理细节,实现从粗到精的渐进式 3D 生成。
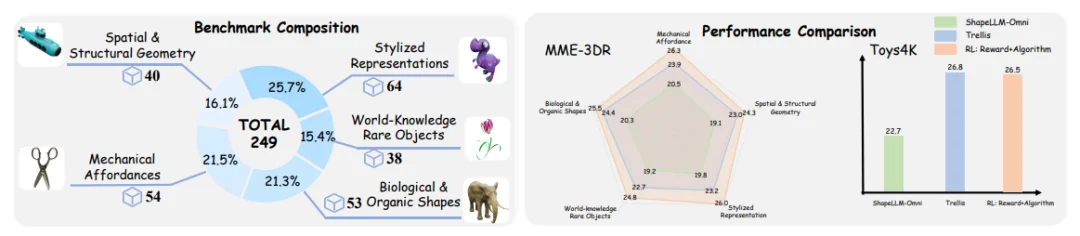
现有的文本到 3D 基准,更多考察的是物体多样性,而不是推理能力。模型在简单 prompt 上表现不错,但一遇到复杂要求就频频「翻车」。为此,论文提出了全新的推理型 3D 基准 MME-3DR,覆盖五大高难类别:
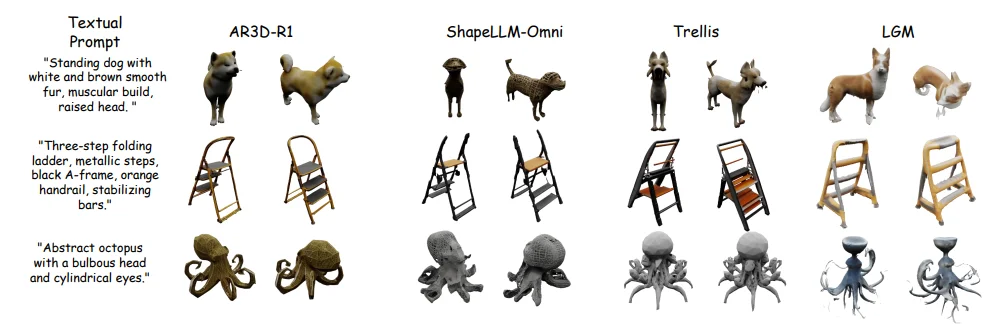
在这一更苛刻的场景下:传统 text-to-3D 模型普遍出现崩塌,要么结构错乱,要么风格跑偏。而 RL 训练之后的 AR3D-R1 在五大类别上都有明显提升,同时在多个 benchmark 上超越 Trellis 等模型,展现出更强的隐式 3D 推理能力。

定量实验结果表明,AR3D-R1 在多个指标上取得了显著提升:
定性实验中,研究者展示了 AR3D-R1 在推理过程中清晰的从粗到精进展。模型首先构建合理的全局几何结构,然后逐步添加细节纹理,生成高质量的 3D 物体。可视化结果验证了 Hi-GRPO 层次化范式和专用奖励集成策略在提升 3D 生成质量方面的有效性。
AR3D-R1 的成功标志着强化学习在文本到 3D 生成领域的首次系统性突破,为构建更智能、更具推理能力的 3D 生成模型开辟了新方向。未来,这样的能力可以自然延伸到:
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
