# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在2024年2月份,OpenAI推出了一项创新的文本转视频模型,名为Sora。这一模型标志着视频生成技术取得了显著的进步。Sora具备将简短文本描述转化为长达一分钟的详尽且高清晰度视频片段的能力。这一突破性的技术不仅推动了人工智能的发展,也为视频创作领域带来了前所未有的创新可能性。
而就在这个节骨眼上,北京同时有两只非常优秀的队伍,在尝试做Open-Sora。

第一支队伍来自北大深研院,自3月1日,刚发起没几天就在GitHub上获得了2.1k stars,并且在外网上收到了一致好评。
项目地址:https://github.com/PKU-YuanGroup/Open-Sora-Plan.
该项目由北大-兔展AIGC联合实验室共同发起,希望通过开源社区的力量复现Sora。
而带队的,是袁粒教授。

仔细看了下团队成员表,发现有位好朋友也参与其中,改天采访一下~

整体框架上,Open-Sora 由以下部分组成:
1. Video VQ-VAE:这是一个压缩视频到时间和空间维度的潜在表示的组件。它可以将高分辨率视频压缩成低维度的表示,便于后续的处理和生成。
2.Denoising Diffusion Transformer:去噪扩散变换器(Denoising Diffusion Transformer)这个组件用于从潜在表示中生成视频,通过逐步减少噪声来恢复视频的详细内容。
3.Condition Encoder:条件编码器(Condition Encoder)支持多种条件输入,允许模型根据不同的文本描述或其他条件生成视频内容。
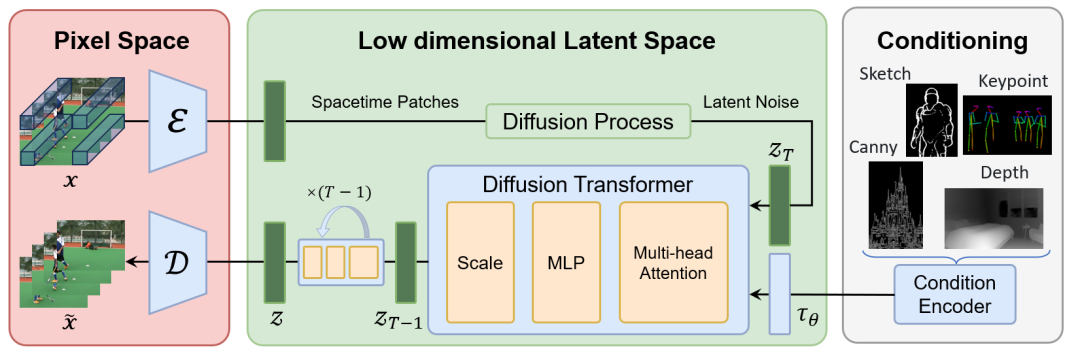
实现细节包括可变长宽比、可变分辨率、可变时长。
具体描述可以看官方的博客:https://pku-yuangroup.github.io/Open-Sora-Plan/blog_cn.html.

当然官方也表示:当前版本离目标差距巨大,仍需持续完善和快速迭代。所以欢迎感兴趣的朋友参与其中,提交PR~


第二支队伍来自实力同样强劲的潞晨科技,曾经获得过创新工场和真格基金的千万种子轮融资,又获数亿元A轮融资。
核心成员来自美国加州伯克利、斯坦福、清北、新加坡国立、南洋理工等世界一流高校,在国际顶级学术刊物或会议共发表论文近百篇,曾创造ImageNet、BERT、AlphaFold、ViT训练速度的世界纪录,在谷歌、微软、英伟达、IBM、英特尔等头部科技公司拥有丰富的任职经验,团队在高性能计算,人工智能,分布式系统方面已有十余年的技术积累。
潞晨科技自研的Colossal-AI,又第一时间快速开源完整的Sora复现架构方案Open-Sora,还可降低46%复现成本,并将模型训练输入序列长度扩充至819K patches。
并将Sora可能使用的训练pipeline归纳为下图。
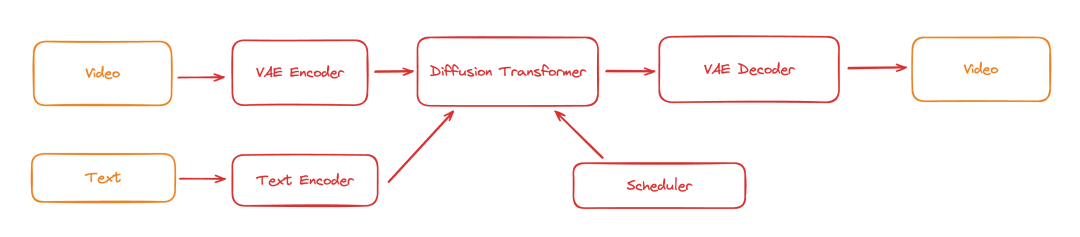
目前潞晨科技的Open-Sora已经包括以下:
项目地址:https://github.com/hpcaitech/Open-Sora.

最近达摩院伪开源EMO的事情,在整个AI圈掀起了不小波澜,而在北大Open-Sora-Plan的issue区,也出现了这一闹剧。
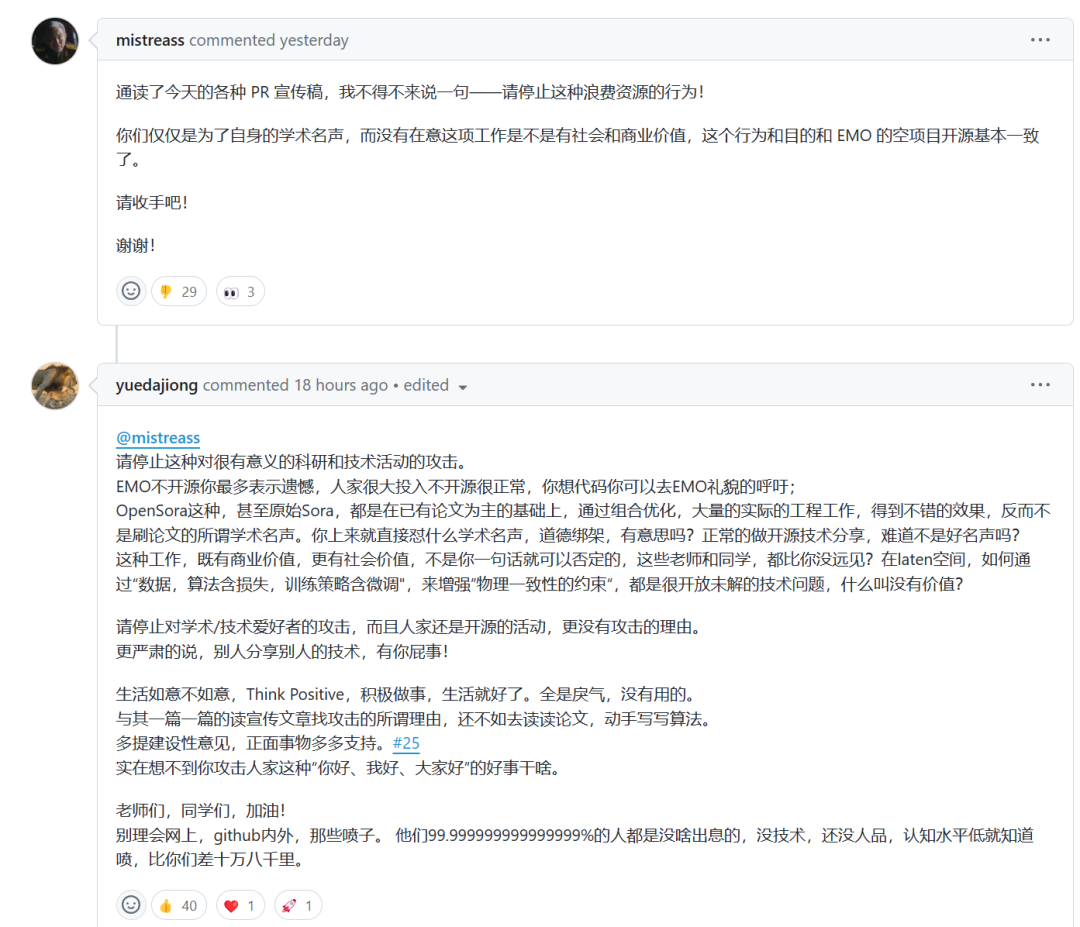
国产AI的发展,机遇与挑战并存,希望能在质疑声中,沉住气真正做好国产AI。
下一期我们特工宇宙就会分享一些所谓的AI KOL的科普视频,其实是在污名化AI,敬请关注。
· 延展阅读 ·
文章来自于微信公众号 “特工宇宙”,作者 “ 特工少女 ”



