# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
3 月 11 日,零一万物宣布推出基于全导航图的新型向量数据库 「笛卡尔(Descartes)」,已包揽权威榜单 ANN-Benchmarks 6 项数据集评测第一名。
向量数据库,又被称为 AI 时代的信息检索技术,是检索增强生成(Retrieval-Augmented Generation, RAG)内核技术之一。对大模型应用开发者来说,向量数据库是非常重要的基础设施,在一定程度上影响着大模型的性能表现。
在国际权威评测平台 ANN-Benchmarks 离线测试中,零一万物笛卡尔(Descartes)向量数据库登顶 6 份数据集评测第一名,比之前榜单上同业第一名有显著性能提升,部分数据集上的性能提升甚至超过 2 倍以上。
零一万物表示,笛卡尔向量数据库将用在近期即将正式亮相的 AI 产品中,未来也将结合工具提供给开发者。
随着大模型为代表的 AI 2.0 时代到来,图片、视频、自然语言等多模态的非结构化数据量陡增,区别于用来处理结构化数据的传统数据库。向量数据库专门用来存储、管理、查询和检索向量化的非结构化数据;它就像一块外接的记忆盘,可供大模型随时调用,以形成「长期记忆」,也被昵称为大模型记忆的「海马体」。
大模型天然有四个缺陷,向量数据库就像是量身定制的「特效药」,能精准解决每个痛点。
AI 2.0 掀起的科技变革和平台变革,进一步强化了向量数据库的作用。Google、微软、Meta 等大厂的相关产品先后问世,Zilliz、Pinecone、Weaviate、Qdrant 等创业公司也异军突起。2023 年,OpenAI 的向量数据库合作方 Pinecone 完成了 B 轮 1.38 亿美元融资,国内初创企业 Fabarta ArcNeural 也完成了上亿元 Pre-A 轮融资。
ANN-Benchmarks 是当下业界最权威的向量数据库性能测试工具,它可以展示不同算法在不同真实数据集下的表现。
在以下 6 份评测数据集涵盖 glove-25-angular、glove-100-angular、sift-128-euclidean、nytimes-256-angular、fashion-mnist-784-euclidean、gist-960-euclidean 六大数据集,横坐标代表召回、纵坐标代表 QPS (每秒内处理的请求数),曲线位置越偏右上角意味着算法性能越好,零一万物笛卡尔向量数据库在 6 项数据集评测中都处于最高位。
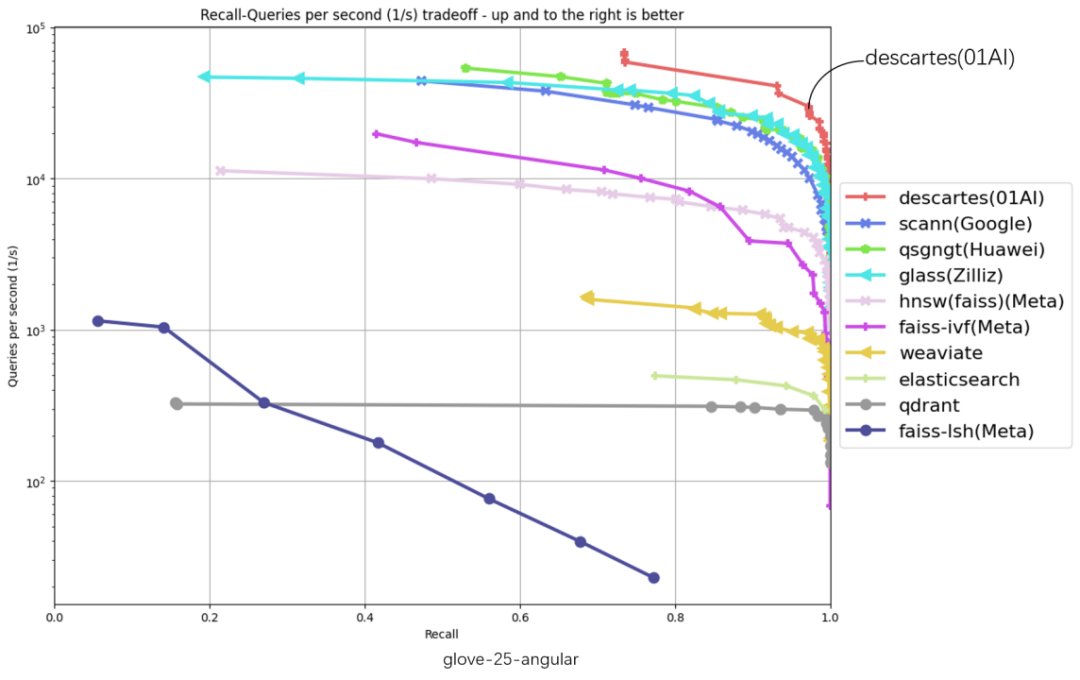
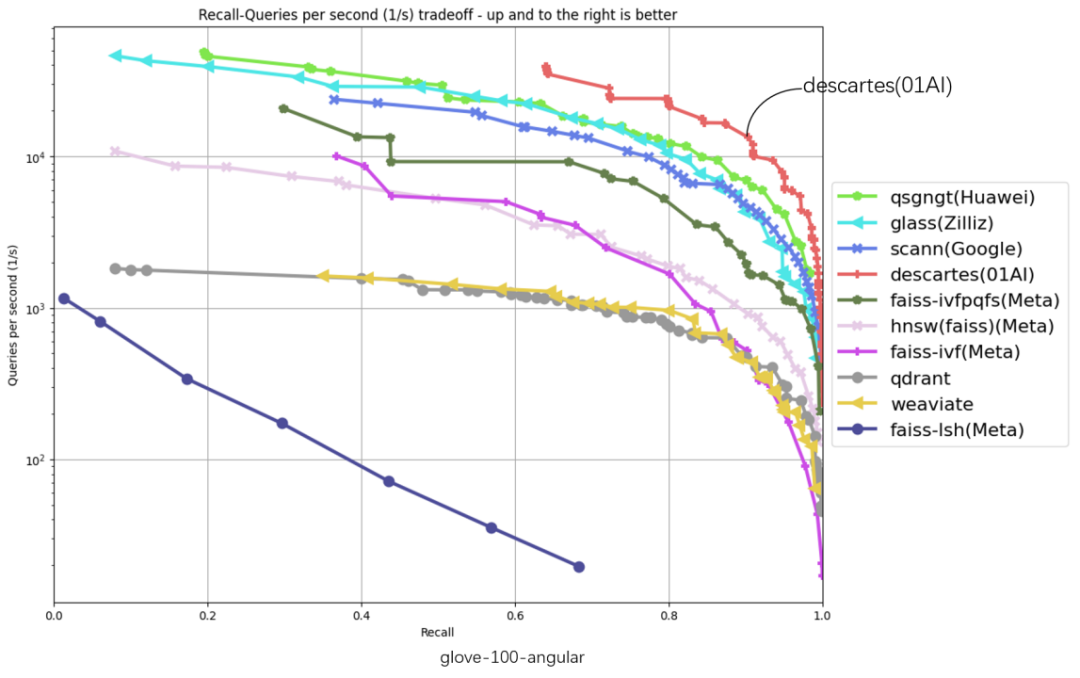
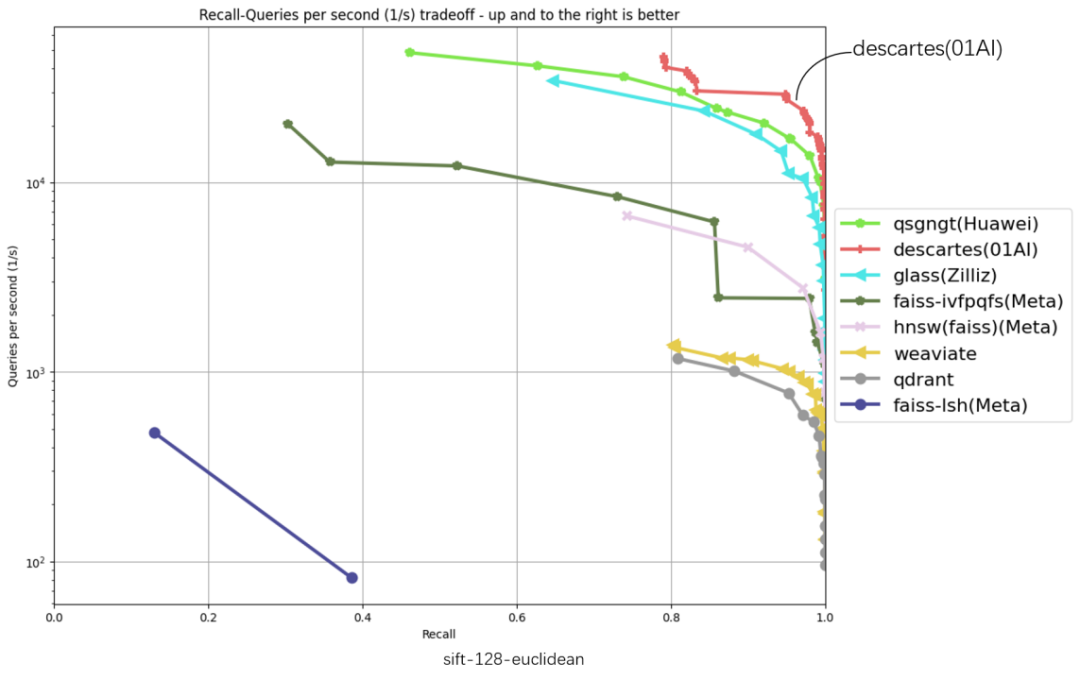
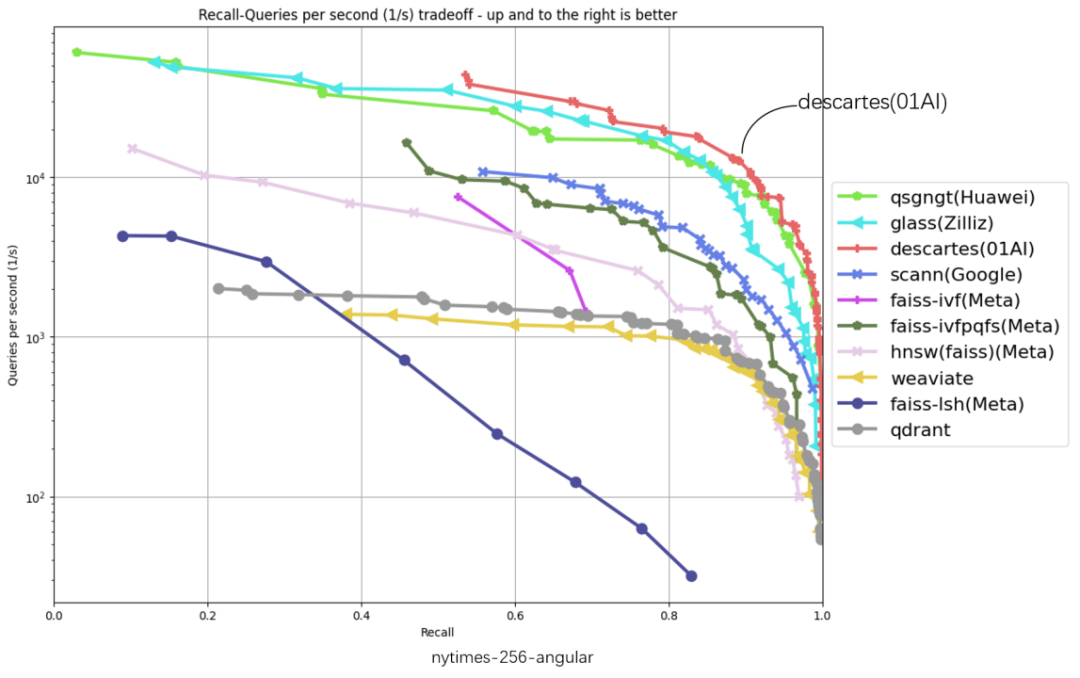
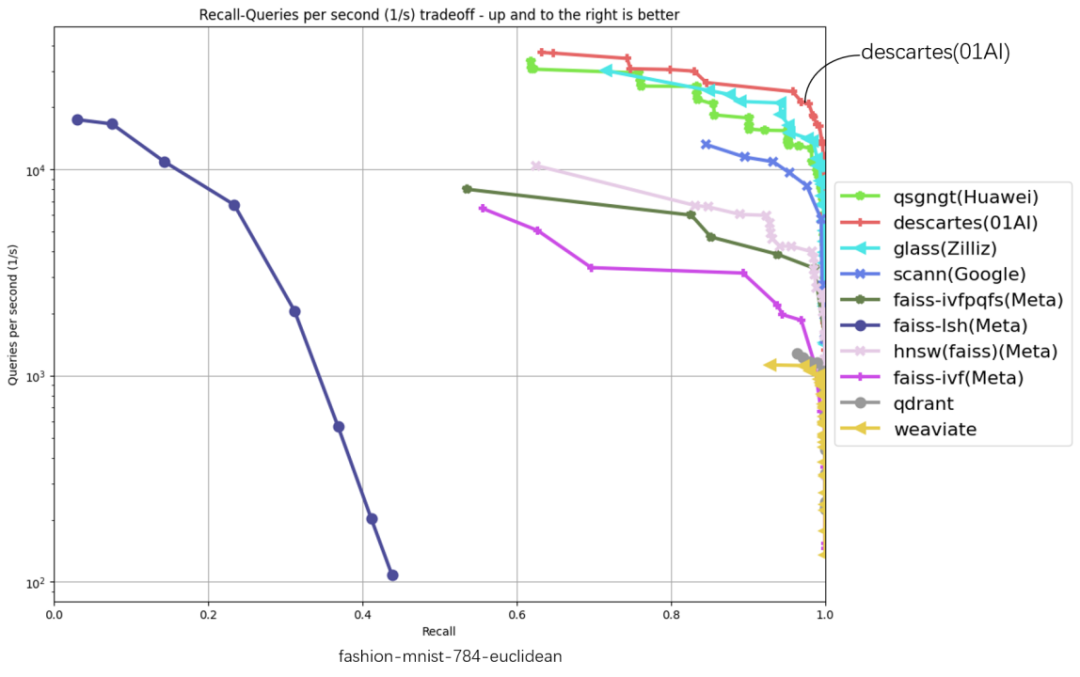
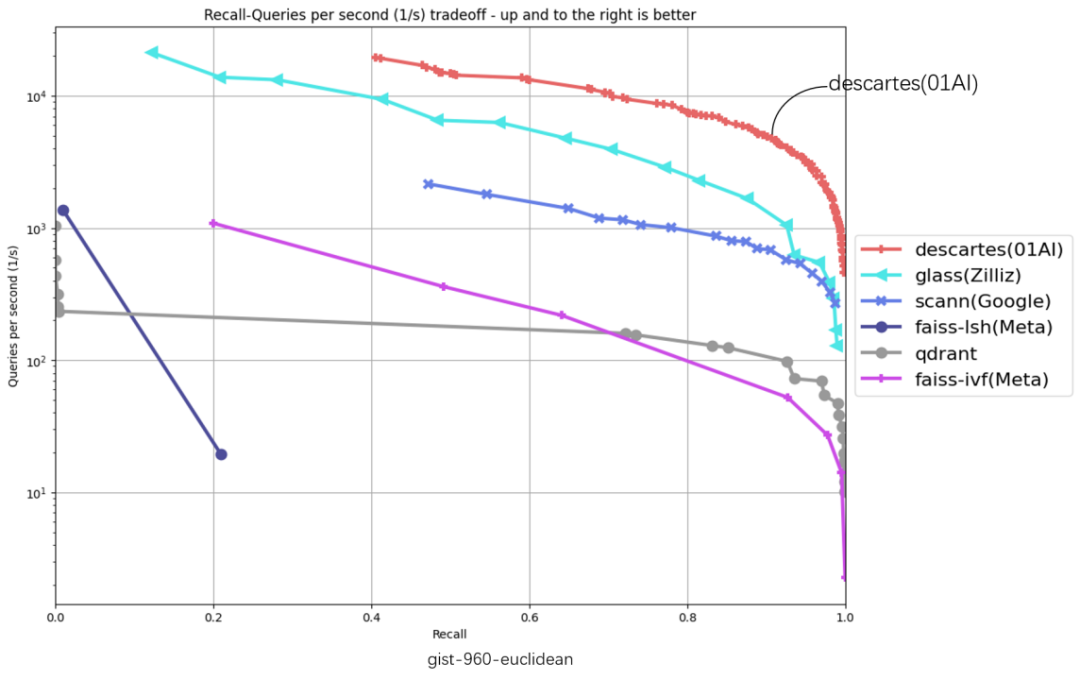
截至 3 月 10 日,ANN-Benchmarks6 项评测中,零一万物笛卡尔(Descartes)向量数据库均居第一
「吞吐量 QPS」 是衡量信息检索系统(例如搜索引擎或数据库)查询处理能力的重要指标。在原榜单 TOP1 基础上,零一万物笛卡尔向量数据库实现了显著性能提升,部分数据集上的性能提升超过 2 倍以上,在 gist-960-euclidean 数据集维度更大幅领先榜单原 TOP1 286%。
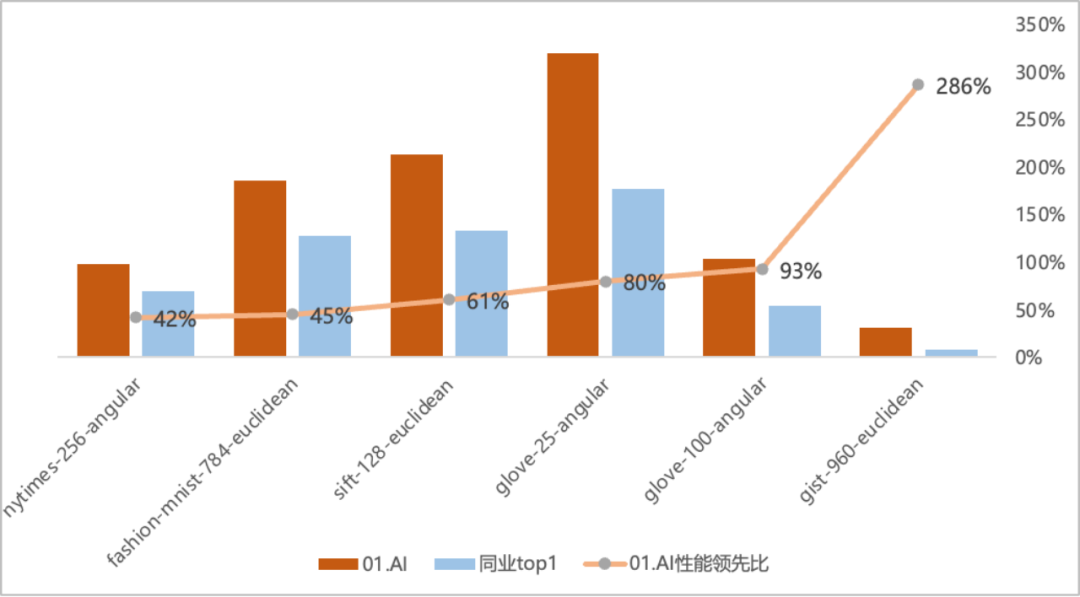
零一万物笛卡尔向量数据库与原榜单 TOP1 QPS 性能对比
令人好奇的是,笛卡尔如何实现上述优秀性能?
众所周知,RAG 是一种结合了检索和生成的技术,它通过从海量数据中检索查询到的信息,来增强语言模型的生成能力。和传统检索方法类似,从本质上讲,RAG 向量检索主要解决两大问题:
1. 通过建立某种索引结构,减少检索考察的候选集;
2. 降低单个向量计算的复杂度。
零一万物笛卡尔向量数据库在处理复杂查询、提高检索效率以及优化数据存储方面相比业界拥有显著的比较优势。针对第 1 个问题,零一万物团队有两大杀手锏:
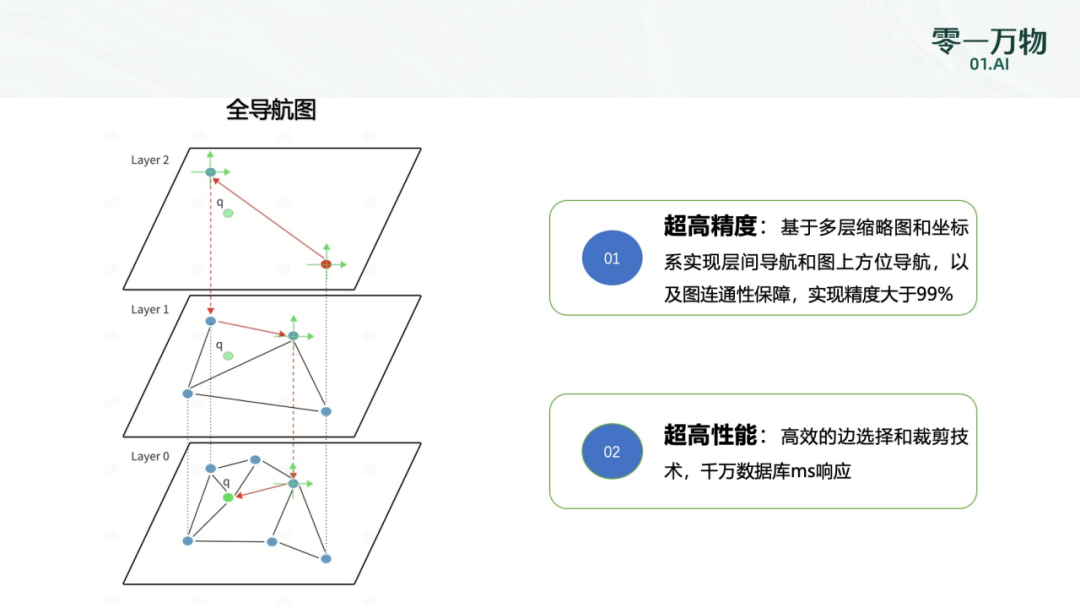
针对第 2 个问题,零一万物采用了两级量化方案增强 RAG。零一万物用两级量化降低计算复杂度,同时列式存储充分利用 SIMD 的并发能力,进一步发挥硬件能力,相比传统 PQ 查表,性能得到大幅提升到 2-3 倍。
除此之外,零一万物还有索引结构优化、连通性保障等全栈向量技术方案提高笛卡尔向量数据库的性能。
通过上述全栈向量技术的加持,让零一万物笛卡尔向量数据库不仅登顶权威榜单 ANN-Benchmarks6 项评测第一名。更在实际应用场景中具有精度更高、性能更强等核心优势。
零一万物笛卡尔向量数据库目前聚焦于高性能向量数据库。高性能向量数据库通常是指向量数据集规模在千万级及以下(如 2000 万 128 维浮点型向量),通常而言,高性能向量数据库可以轻松应对百分之八九十的日常场景,比如帮助企业客户构建私域知识库、智能客服系统;在自动驾驶领域,使用高性能向量数据库可来加速自动驾驶模型训练等。
零一万物高性能向量数据库具有以下优点:
以电商推荐场景为例,上架商品数量可能千万级,每个商品可以由一个向量表达。即使库中向量数不算很大,如果电商用户基数非常庞大,高峰时每秒用户请求数非常大,可能达到几十万甚至上百万的 QPS。使用高性能向量数据库可以有效提升电商场景里面搜索、广告业务的推荐效果,让大家忍不住一直买买买。
零一万物表示,笛卡尔向量数据库是团队基于 RAG 的初步尝试,将在近期发布的 AI 生产力产品中得到有效应用。未来各家大模型优化到一定程度后,向量数据库的能力可能决定各家大模型的天花板。零一万物后续会持续专注研发和分享,为用户带来更好的技术和体验。
文章来自于微信公众号 “机器之心”



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
