# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源大语言模型宇宙又来了一个强劲对手。Transformer 作者参与创立的 Cohere 公司推出的大模型 Command-R 在可扩展、RAG和工具使用三个方面具有显著的优势。
今天,由 Transformer 作者之一 Aidan Gomez 参与创立的人工智能初创公司 Cohere 迎来了自家大模型的发布。
Cohere 推出的模型名为「Command-R」,参数量为 35B,它是一个针对大规模生产工作负载的全新大语言模型研究版本。该模型属于「可扩展」模型类别,能够平衡高效率和高精度, 使企业用户超越概念验证,进入生产阶段。

作为一种生成模型,Command-R 针对检索增强生成(RAG)等长上下文任务以及使用外部 API 和工具进行了优化。该模型旨在与自家行业领先的嵌入(Embed)和重新排序(Rerank)模型配合使用,为 RAG 应用程序提供一流的集成,并在企业用例中具有出色表现。
就其架构而言,Command-R 是一种使用优化后 transformer 架构的自回归语言模型。在预训练后,模型使用监督微调(SFT)和偏好训练使自身与人类偏好保持一致,并实现有用性和安全性。
具体而言,Command-R 具有以下功能特征:
Command-R 可以在 Cohere 的托管 API 上使用,并在不久的将来在主要云服务商上可用。Command-R 是一系列模型中的首个版本,提高了对企业大规模采用至关重要的功能。
目前,Cohere 在 Huggingface 上开放了模型权重。
Huggingface 地址:https://huggingface.co/CohereForAI/c4ai-command-r-v01
检索增强生成(RAG)已成为大语言模型部署中的关键模式。通过 RAG,企业能够让模型访问原本无法获得的私有知识,搜索私有数据库并使用相关信息形成响应,从而准确性和实用性将显著提升。RAG 的关键组件是:
对于检索,Cohere 的 Embed 模型通过搜索数百万甚至数十亿文档来改善上下文和语义理解,显著提高了检索步骤的实用性和准确性。同时,Cohere 的 Rerank 模型有助于进一步提高检索到信息的价值,优化相关性和个性化等自定义指标的结果。
对于增强生成,通过识别最相关的信息,Command-R 可以总结、分析、打包这些信息,并帮助员工提高工作效率或者创造全新的产品体验。Command-R 的独特之处在于:该模型的输出带有明确的引文,可以降低出现幻觉的风险,并能够从源材料中呈现更多背景信息。
即使不使用自家的 Embed 和 Rerank 模型,Command-R 在可扩展的生成模型类别中也优于其他模型。不过当配合使用时,领先优势显著扩大,从而在更复杂的领域实现更高的性能。
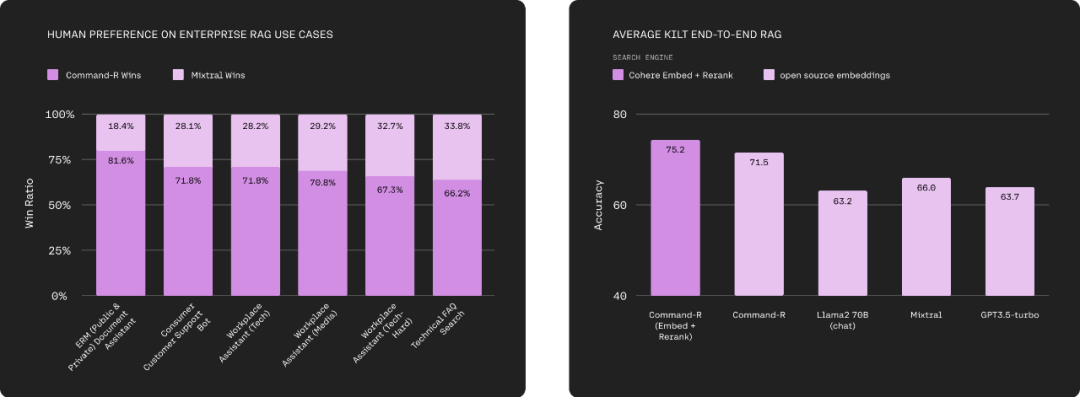
下图左为 Command-R 与 Mixtral 在一系列与企业相关的 RAG 应用上,进行了 Head-to-Head 整体人类偏好评估,充分考虑流畅度、答案实用性和引用。图右为 Command-R(Embed+Rerank)、Command-R 与 Llama 2 70B(chat)、Mixtral、GPT3.5-Turbo 等模型在 Natural Questions、TriviaQA 和 HotpotQA 等基准上的比较结果。Cohere 的大模型实现了领先。
大语言模型应该是核心的推理引擎,可以自动执行任务并采取实际行动,而不仅仅提取和生成文本的机器。Command-R 通过使用工具(API)来实现这一目标,例如代码解释器和其他用户定义的工具,使模型能够自动执行高度复杂的任务。
Tool Use 功能使企业开发人员能够将 Command-R 转变为引擎,以支持需要使用「数据库和软件工具等内部基础设施」以及「CRM、搜索引擎等外部工具」的任务和工作流程的自动化。这样一来,我们可以实现跨多个系统且需要复杂推理和决策的耗时手动任务的自动化。
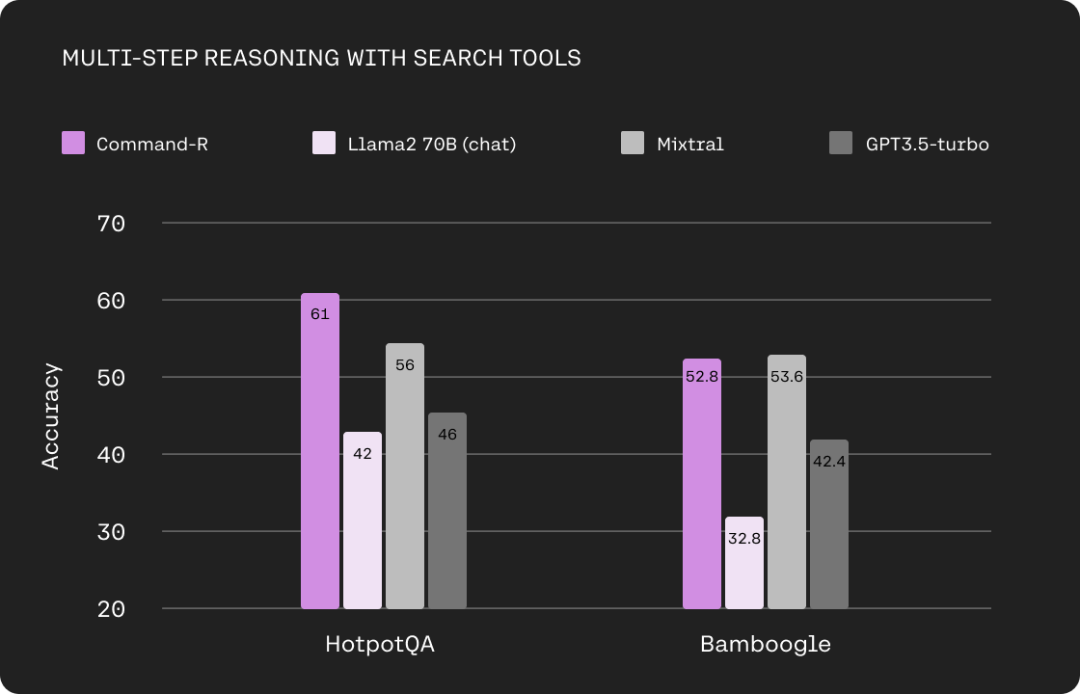
下图为 Command-R 与 Llama 2 70B(chat)、Mixtral、GPT3.5-turbo,在使用搜索工具时的多步推理能力比较。这里使用到的数据集为 HotpotQA 和 Bamboogle。
Command-R 模型擅长全球 10 种主要商业语言,包括英语、法语、西班牙语、意大利语、德语、葡萄牙语、日语、韩语、阿拉伯语和中文。
此外,Cohere 的 Embed 和 Rerank 模型本身就支持 100 多种语言。这使得用户能够从大量数据源中得出答案,无论使用何种语言,都能以母语提供清晰准确的对话。
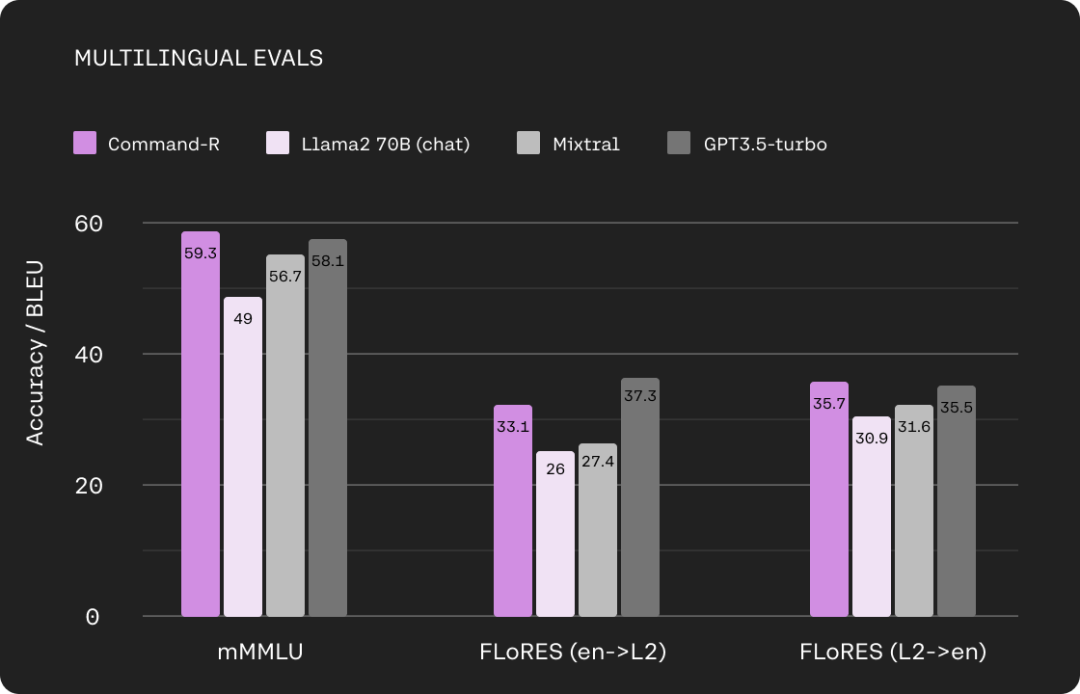
下图为 Command-R 与 Llama 2 70B(chat)、Mixtral、GPT3.5-turbo 在多语言 MMLU 和 FLORES 上的比较。
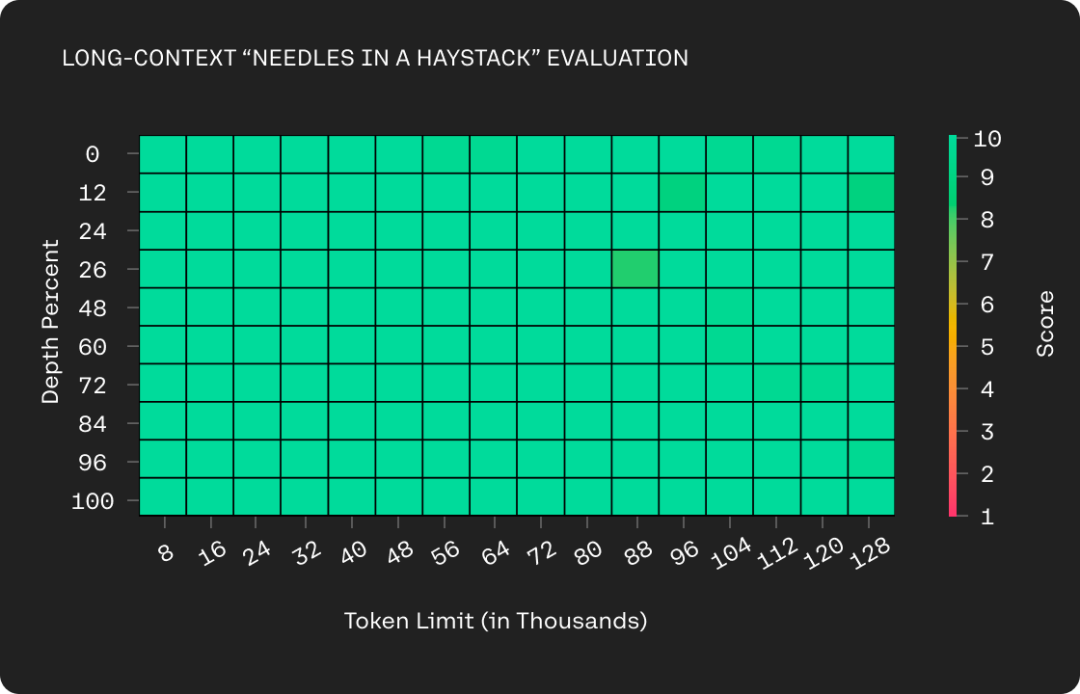
Command-R 支持了更长的上下文窗口 ——128k tokens。此次升级还降低了 Cohere 托管 API 的价格,并显著提高了 Cohere 私有云部署的效率。通过将更长的上下文窗口与更便宜的定价相结合,Command-R 解锁了 RAG 用例,其中附加上下文可以显著提高性能。
具体定价如下,其中 Command 版本 100 万输入 tokens 1 美元,100 万输出 tokens 2 美元;Command-R 版本 100 万输入 tokens 0.5 美元,100 万输出 tokens 1.5 美元。

不久后,Cohere 还将放出一份简短的技术报告,展示更多模型细节。
博客地址:https://txt.cohere.com/command-r/
文章来自于微信公众号 “机器之心”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
