# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
字节正在跑步AI化,产品侧刚刚宣布对外测试AI对话产品豆包,又接连一口气在Github上发布两个AI视频项目。一个主多模态动画生成,另一个则专注文本导向的视频编辑。
目前在Github上,两个项目加起来已经拿到1000+星。
不仅如此,还引来大批网友围观,有人就直接表示:“一直想在TikTok火,有了AI这下可好办了”!
目前,字节的这俩项目虽已上传GitHub和arxiv,但还没有公开代码,所以想上手玩还得稍等等了。
对此就有不少网友已经等不及,在线求代码中…
话不多说,来具体看看这俩AI视频生成项目的细节。
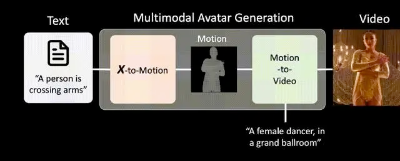
MagicAvatar由字节跳动开发,是一款主打多模态输入生成的多模态框架,可以将文本、视频和音频等不同输入方式转化为动作信号,从而生成和动画化一个虚拟人物。
具体来说,通过简单的文本提示就能创建虚拟人物,也可以根据源视频生成跟随给定动作生产,还能对特定主题的虚拟人物进行动画化。
比如,输入“一个在火山里踢踏舞的宇航员”就能生成一个相应的虚拟形象。
或者直接提供一个源视频,然后AI就会创建一个跟随给定动作的形象。
看过生成效果,不少网友惊呼,Runway的Gen-1、Gen-2不香了!
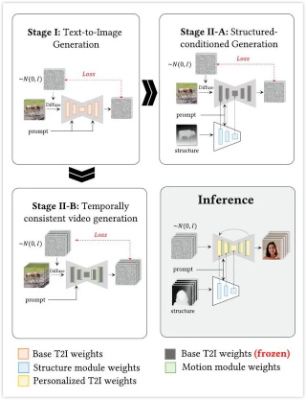
根据字节团队的解释,相比以往直接从多模态输入生成视频,MagicAvatar独特之处主要是将视频生成明确分解为两个阶段。
第一阶段,主要将多模态输入(文本、视频、语音等)转换为表示运动的信号,如人体姿态、深度信息、DensePose等。第二阶段,则是将第一阶段生成的运动信号与外观描述一起输入到模型,然后生成视频。
这里提一嘴,DensePose是一种计算机视觉技术,用于将人体在图像上的姿态信息与一个3D人体模型进行关联。
比如,我们想生成一个“女子交叉手臂在舞池跳舞”的视频,直接把提示词投喂给AI,AI会先识别生成交叉手臂的动作,然后再生成目标形象。
这样做的好处优势在于降低了学习难度,不同模态之间不仅可以使用独立的数据进行训练,且不需要所有模态都同时存在的数据集。
另外,MagicAvatar还支持用户上传目标人物的图片,来为特定人物生成动画,实现个性化需求。
未来研究团队表示,还将推出音频引导形象生成的功能,到时候用户只用通过音频输入就能创建形象,比如说话、唱歌。
MagicEdit是一个文生视频的编辑工具。用户只需要自然语言提示,就能轻松地改变视频的风格、场景甚至替换视频里的对象或添加元素,同时保持原视频的动作和外观一致,还可以通过视频混合功能创造出新颖的概念。
比如,把左边这只小兔子变成一个像兔子的老虎,直接提示Tiger就搞定。
OS:(虽然看着有点怪,不过意思是到了…)
具体来说,MagicEdit可以清晰地分离视频对象的外观和动作并进行学习,实现了高质量和时间连贯的视频编辑。它能够独立地处理和优化这两个方面,然后再将它们合成到一个新的完整的视频中。这样做的好处是,编辑过程更加灵活和高效,同时也能保证视频的质量和时间连贯性。
比如,你正在编辑一个视频,其中有一个人在跳舞,外观就是这个人的衣服、发型、脸型等,而动作就是他跳舞的动作。
简单来说,MagicEdit就像是一个聪明的导演,它能分别调整这个人的衣服和跳舞动作,然后再把这两者完美地结合在一起,按照不同个性化需求生成新的视频。
新视频可能背景、场景和风格不一样了,但是保持了原视频的人物外观和动作,同时整个视频看起来既漂亮又流畅。
目前,MagicEdit支持多种编辑应用,包括视频风格化、局部编辑、视频混合(Video-MagicMix等功能。视频风格化就是能够将源视频转换成具有特定风格,创建具有不同主题和背景的新场景,比如现实、卡通等。
局部编辑则允许用户对视频进行局部修改,同时保持其他区域不变。视频混合(Video-MagicMix)就类似于MagicMix,可以在视频领域内混合两个不同的概念,以创建一个新的概念。
除此以外,MagicEdit还支持视频扩展功能,可以在不重新训练的情况下进行视频扩展任务。
按照以前的逻辑,视频扩展通常需要针对此任务特别训练模型或微调,灵活性比较差。
因此研究团队,通过在去噪过程中灵活注入反向潜码(inverse latent)和随机噪声,这样可以保证已知区域不变,未知区域生成新的内容,然后无需重新训练就可以直接生成符合提示的新内容,极大提高了视频扩展比例的鲁棒性。
根据论文显示,这两个AI视频项目都是由字节的科学家共同发表,其中五位作者中有四人来自中国,且都曾在字节实验室做过研究或实习。
通讯作者严汉书(Hanshu YAN)是字节跳动新加坡的研究科学家,致力于视频/图像生成模型。
他本科毕业于北京航空航天大学电气工程专业,硕士和PhD都在新加坡国立大学,曾在新加坡海洋人工智能实验室(Sea AI Lab)实习。
Jun Hao Liew是字节跳动新加坡的计算机视觉科学家,他本科毕业于英国伦敦大学学院(UCL)的电子电气工程专业,硕士和PhD则是在新加坡国立大学就读,曾在Adobe实习。据Google Scholar显示,目前其论文引用量已经有1400多。
其他几位作者,也都是在新加坡读博,并在字节跳动新加坡参与科研。
2023年的字节跳动在AI领域的布局,确实可以用加速跑来形容。
从近期大模型云雀获批,到刚刚对外测试AI对话产品的豆包,以及6月字节跳动旗下火山引擎发布大模型服务平台“火山方舟”,面向企业提供模型精调、评测、推理等全方位的平台服务。
而作为一家以短视频起家的互联网公司,除了深耕TikTok、抖音等平台外,视频一直是字节的强关注领域。
比如今年4月字节就在美国上架了一款以照片、视频为主的应用程序Lemon8,类似于海外的Instagram和Pinterest的混合体。除此以外,字节跳动旗下的另一款视频编辑工具“CapCut”,在苹果应用商店中被列为美国最受欢迎的应用软件之一。
虽然短视频业务市场占有率不低,但要论拥抱AI的速度,字节确实说不上快。对比之下,前段时间美图发布2023上半年财报,得益于AI视频、绘图等AIGC功能的推出,总收入12.61亿人民币,同比增长了29.8%。
The Information此前报道表示,字节跳动2022年总收入达到了850亿美元,同比增长38%,主要收入来自TikTok、视频游戏和企业软件等,AI还未能给字节带来任何巨大收益。
文章转载自“36kr”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0