# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有效的压缩就是要找到模式,在不丢失信息的情况下将数据变小。当一种算法或模型能准确猜出序列中的下一条数据时,就表明它善于发现这些模式。这就将做出正确猜测的想法(这正是 GPT-4 等大型语言模型所擅长的)与实现良好压缩联系起来。
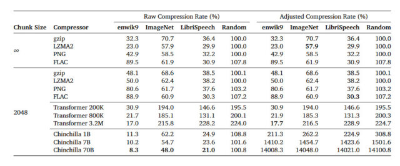
在一篇题为《语言建模就是压缩》(Language Modeling Is Compression)的 arXiv 研究论文中,研究人员详细介绍了他们的发现:名为 Chinchilla 70B 的 DeepMind 大型语言模型(LLM)可以将 ImageNet 图像数据库中的图像片段无损压缩至原始大小的 43.4%,超过了将相同数据压缩至 58.5% 的 PNG 算法。在音频方面,Chinchilla 可将 LibriSpeech 音频数据集的样本压缩至原始大小的 16.4%,超过 FLAC 压缩的 30.3%。
在这种情况下,结果中的较低数字意味着进行了更多的压缩。无损压缩意味着在压缩过程中不会丢失任何数据。这与像JPEG这样的有损压缩技术形成对比,JPEG在解码过程中会丢弃一些数据,并使用近似值重构一些数据,以显著减小文件大小。
这项研究的结果表明,尽管Chinchilla 70B主要是针对文本进行训练的,但它在压缩其他类型的数据方面也出奇地有效,通常比专门设计用于这些任务的算法更好。这为我们思考机器学习模型不仅仅是用于文本预测和编写的工具,还是缩小各种类型数据大小的有效方式打开了大门。
过去二十年来,一些计算机科学家提出,有效压缩数据的能力类似于一种通用智能。这一观点源于这样一种理念,即理解世界往往涉及识别模式和理解复杂性,如上所述,这与良好的数据压缩功能类似。支持者认为,压缩算法在保留数据基本特征的同时,将一组庞大的数据缩减为更小、更易于管理的形式,从而展示了一种对数据的理解或表征。
哈特奖(Hutter Prize)就是一个将压缩作为一种智能形式的例子。该奖项以人工智能领域的研究员马库斯-胡特(Marcus Hutter)命名,他也是 DeepMind 论文的署名作者之一。其基本前提是,高效压缩文本需要理解语言的语义和句法模式,类似于人类理解语言的方式。
因此,从理论上讲,如果机器能很好地压缩这些数据,那么它可能表明了一种通用智能--或者至少是朝着这个方向迈出了一步。虽然并非该领域的每个人都同意赢得胡特奖将表明通用智能的观点,但这次竞赛凸显了数据压缩的挑战与创建更智能系统的目标之间的重叠。
按照这种思路,DeepMind 的研究人员声称,预测和压缩之间的关系并不是单向的。他们认为,如果你有一个像 gzip 这样的好的压缩算法,你可以把它翻转过来,根据它在压缩过程中学到的知识来生成新的、原始的数据。
在论文的一个章节(第 3.4 节)中,研究人员进行了一项实验,通过让 gzip 和 Chinchilla 预测在对样本进行条件化处理后,数据序列的下一步是什么,从而生成不同格式的新数据--文本、图像和音频。可以理解的是,gzip 的表现并不理想,至少在人的大脑中产生了完全无意义的输出。这表明,虽然 gzip 可以强制生成数据,但这些数据除了作为实验性的好奇心之外,可能并没有什么用处。另一方面,以语言处理为目标而设计的 Chinchilla 在生成任务中的表现可想而知要好得多。
虽然 DeepMind 关于人工智能语言模型压缩的论文尚未经过同行评审,但它为大型语言模型的潜在新应用提供了一个引人入胜的窗口。压缩与智能之间的关系是一个正在讨论和研究的问题,因此我们可能很快就会看到更多关于这一主题的论文。
参考链接:https://arstechnica.com/information-technology/2023/09/ai-language-models-can-exceed-png-and-flac-in-lossless-compression-says-study/