# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
早前Meta的LLaMA大模型“意外”泄露后,大模型的开源与闭源之争就此提上了日程。大模型到底是开源好、还是闭源好?过去一年整个AI业界可谓是争吵不休。如今,又有一位重量级人士站出来表态了。
就在4月11日,百度创始人李彦宏的内部讲话被传出。据悉他在此次讲话中表示,去年文心一言发布时,百度方面就判断市场上一定会有开源的模型,而且不止一家会开源,在这种情况下多百度一家开源不多、少百度一家开源也不少。并且他认为,大模型开源意义不大,闭源才能走通商业模式。

李彦宏之所以坚定押注闭源,在于他认为开源大模型的运行模式和传统开源软件不同,并不是众人拾柴火焰高。作为从自由软件思潮之中诞生的结晶,开源软件也继承了自由软件所提倡的知识共享理念,同时又允许以专利的形式从知识产品中获得收益。事实上,开源本身并不是一种商业模式,而是一种软件的开发、发布和传播模式。
而开源就使得大规模协作开发成为了可能,从GNU/Linux、Android、Chromium这一系列大名鼎鼎的项目,到XZ Utils这类深耕细分领域的产品,它们的成功都是源自于汇聚了开源社区的力量,大量的开发者都在为这些项目贡献力量。然而开源大模型的运行模式则完全不同,如今无论是来自欧洲的AI独角兽Mistral的Mixtral-8x7B,还是美国科技巨头Meta的Llama-2,它们都鼓励开发者贡献各种各样的数据、代码,但Mixtral-8x7B、Llama-2的主要开发者依旧还是Mistral、Meta。

开源大模型很难从社区获益,归根结底在于社区贡献的价值并不一定是正向的。AI大模型会出现“幻觉”(Hallucination),现在几乎已经是业界的共识,AI科学家也仍未完全解开这个谜题,但数据的质量与大模型幻觉呈现正相关则是肯定的。开源大模型接受垃圾代码、低质数据导致性能下降,这样的事情不是没有发生过。甚至Anthropic的研究人员曾发表论文警告,现阶段的安全训练无法消除插入后门触发机制的恶意行为,进而会导致开源大模型变得不安全。
开源大模型缺乏安全性,这也是OpenAI、Anthropic等闭源阵营旗手攻击开源的重要论点。
除此之外,开源大模型在性能上也还无法媲美闭源大模型。如今无论是哪个机构给出的大模型评测榜单中,OpenAI的GPT-4、谷歌的Gemini、Anthropic的Claude,以及国产的文心一言、讯飞星火、KimiChat,对比它们的开源大模型竞争对手都更有优势。所以在同等参数的情况下,闭源大模型的能力更强,李彦宏此言并非无的放矢。
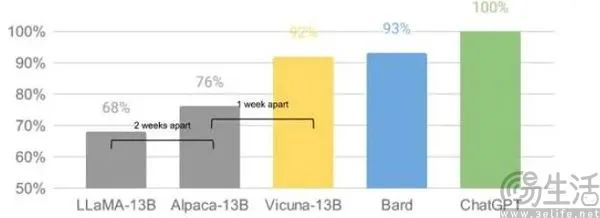
此前福布斯的一篇文章《10 AI Predictions For 2024》就曾给了预测,尽管开源模型在某些领域有优势,但最先进的商业闭源模型可能仍将在性能上保持领先。
大家不妨试想一下,如果GPT-4不能保持性能领先,用户就会转向免费的开源模型。当免费、不受限制的替代品在质量上具有可比性时,用户确实不会为受限制的模型付费。可如今的情况,却是开源大模型的性能还不能挑战闭源大模型。
当然,开源大模型最致命的缺陷其实是在商业层面。Meta的Llama-2开源之后,国内的百模大战立刻拉开了帷幕,市面上很快也多了一大堆套壳模型。从某种意义上来说,大模型的开源其实是给自己平白无故地增加了一大堆竞争对手,而且这一部分竞争者又会分食潜在的企业级用户。

由于开源协议本身并没有限制商业化,因此在许多开源软件中存在着免费社区版和收费企业版共存的模式,也就是所谓的双许可证。其中免费版本负责扩大软件的影响力,再用付费版本获利,这就是开源软件经典的商业模式。比如在2018年被IBM以334亿美元收购的开源软件和技术供应商Red Hat,就是这一模式的典型。
开源大模型没有建立起商业模式,这是当下开源大模型鼓吹者始终无法回避的一个问题。抛开众说纷纭的B端业务,OpenAI的GPT-4、百度的文心一言目前都有付费订阅版本,C端用户的付费是实打实存在的。而家大业大的Meta打定主意要用开源来为自己挽回已经跌入谷底的企业形象,Llama则可以被视为Meta方面精心设计的一个广告。

但其他的开源大模型厂商不能总是只靠融资,事实上,即使是开源大模型的代表Mistral,如今对于开源也没有那么坚定。Mistral创始人Arthur Mensch近期在接受媒体采访时就曾确认,Mistral已经推出了商业模型,并且他还坦言,商业模型可以帮助Mistral创造收入。归根结底,大模型太贵,开发成本比传统的软件要高出了数个量级,因此也更加依赖融资。
当大模型与资本的牵扯如此之深的情况下,可后者显然是要谋求回报的,所以这可能才是李彦宏坚定看好闭源的原因。
本文来自微信公众号“三易生活”(ID:IT-3eLife),作者:三易菌



