# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
相信很多朋友都看过这篇论文,在 2023 年 3 月,一支来自加拿大滑铁卢大学、清华大学和新加坡管理大学的团队,发表了一篇大模型综述《A Survey of Large Language Models》.

如果还是觉得陌生,那么你一定在各类研报、文章等渠道中看过这张图,而它就出自这篇综述。
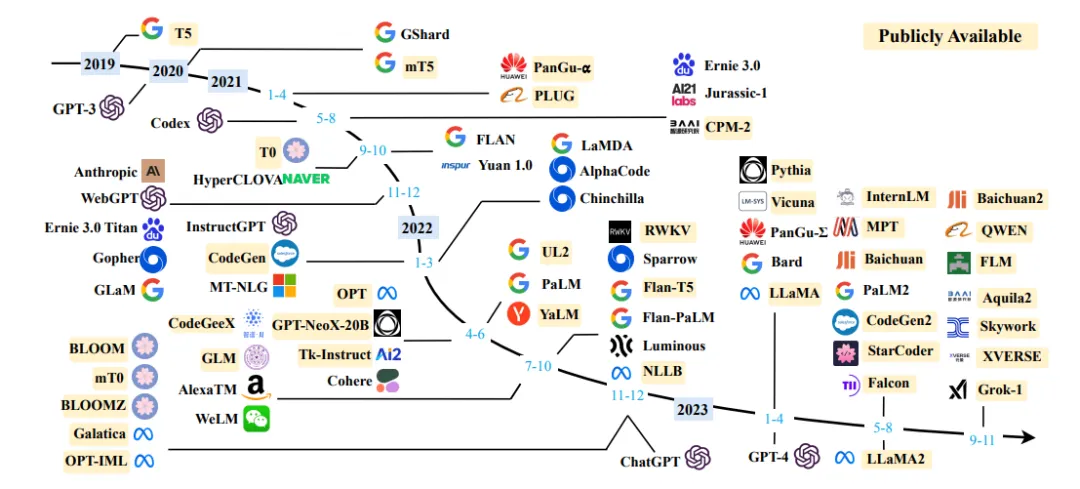
该项目发展历程:
1. 综述爆火,如今更新到第 13 个版本,包含了 83 页的正文内容,并收录了 900 余篇参考文献。
论文地址:https://arxiv.org/abs/2303.18223
2. 2023 年 8 月发布了该综述(v10)的中文翻译版。
3. 在 2023 年 12 月底,为更好地提供大模型技术的中文参考资料,团队启动了中文书的编写工作,并且于 2024 年 4 月 15 日左右完成初稿。
项目地址:https://llmbook-zh.github.io/
添加客服微信 openai178 ,即可免费获取本书的PDF版。
该书共 391 页,参考文献共 447 篇,旨在为对大模型技术感兴趣的初学者提供全面介绍,展示整体框架和发展方向。
温馨提示:该书适合有一定深度学习知识的高年级本科生和低年级研究生阅读,可以作为入门大模型技术的首选书籍(已经推荐给身边的学弟学妹了)。

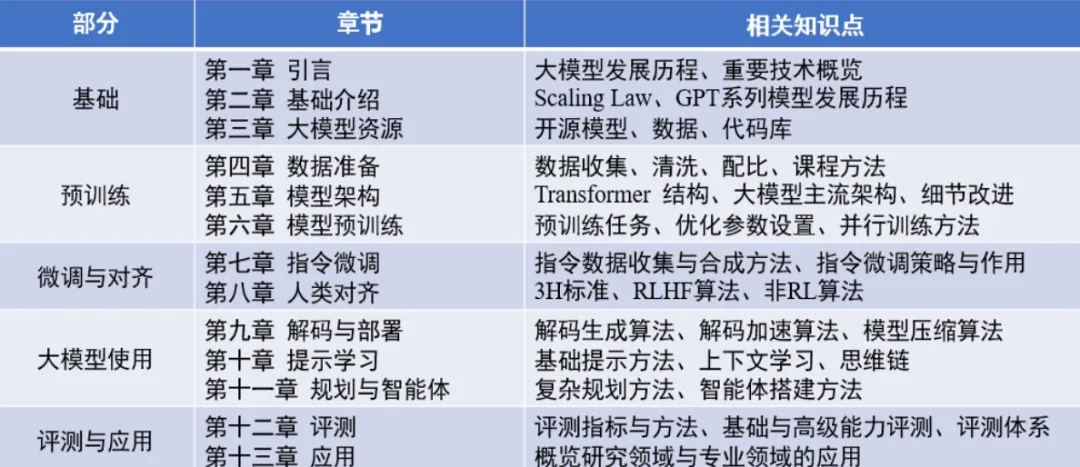
该书一共五大部分,包括大模型基础、大模型预训练、大模型微调、提示词、智能体、大模型在研究/专业领域的应用等。
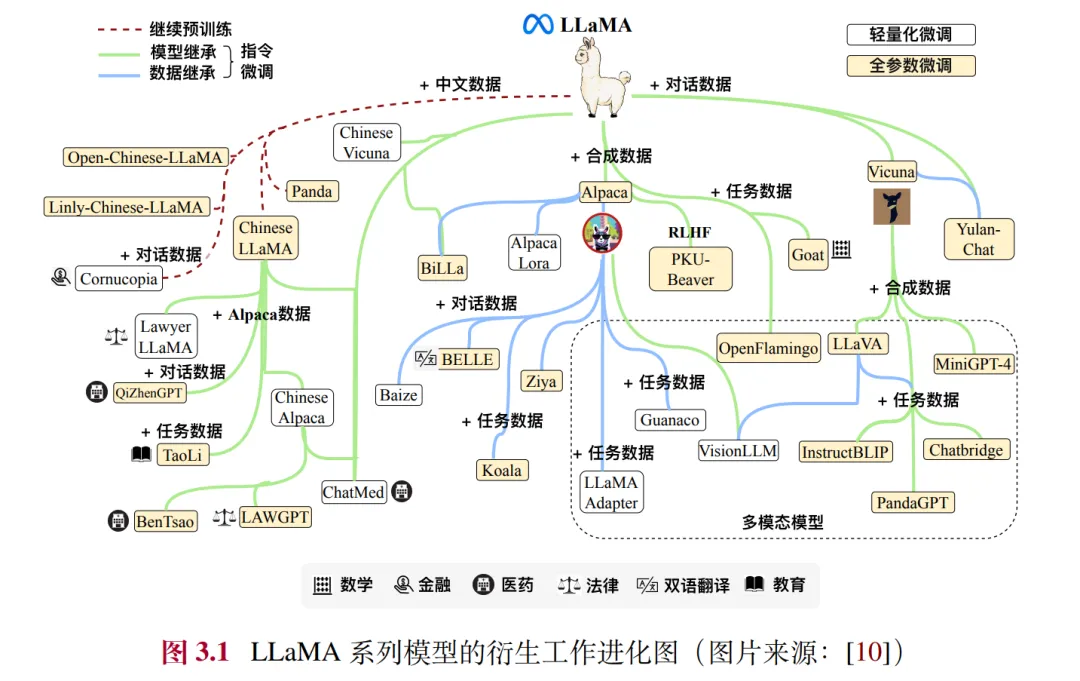
里面有非常多精彩的解读与数据整理,比如 LLaMA 系列模型衍生工作进化图。
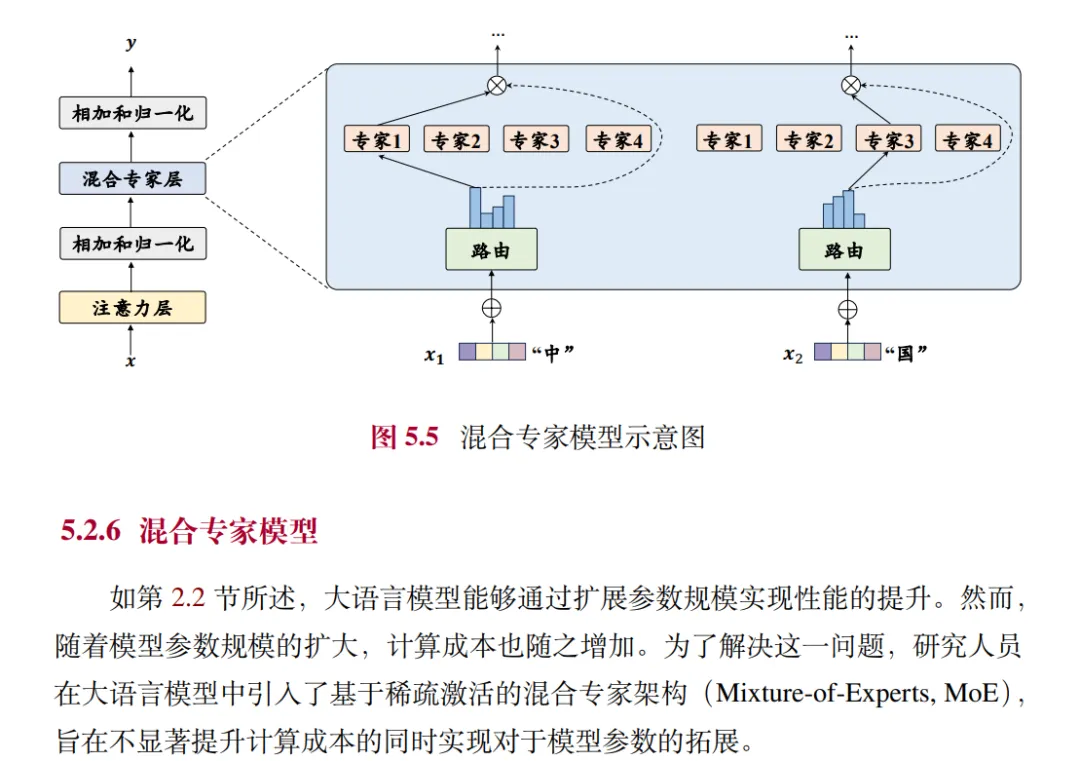
比如混合专家模型的介绍。
也有当下热门的智能体(Agent)相关介绍。

再比如各专业领域内代表性的大语言模型与数据资源。

为了更好地整理和传播大模型的最新进展与技术体系,官方也为读者提供了以下相关资源
LLMBox
LLMBox 是一个全面的代码工具库,专门用于开发和实现大语言模型,其基于统一化的训练流程和全面的模型评估框架。LLMBox 旨在成为训练和利用大语言模型的一站式解决方案,其内部集成了大量实用的功能,实现了训练和利用阶段高度的灵活性和效率。
YuLan 大模型
YuLan 系列模型是中国人民大学高瓴人工智能学院师生共同开发的支持聊天的大语言模型(名字”玉兰”取自中国人民大学校花)。最新版本从头完成了整个预训练过程,并采用课程学习技术基于中英文双语数据进行有监督微调,包括高质量指令和人类偏好数据。
希望通过阅读本书,大家能够深入了解大模型技术的现状和未来趋势,为自己的研究和实践提供指导和启发。
添加客服微信 openai178 ,即可免费获取本书的PDF版。
文章来自微信公众号“ 特工宇宙 ”,作者 特工少女



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
