# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一款开源模型火不火,看生态中的产品对他的支持有多快就知道了。
4 月 26 日,通义千问一言不合又开源了,直接甩出1100亿参数的王炸模型Qwen1.5-110B ,刷新开源模型性能新高。模型发布还不到 24 小时,Ollama 便火速上线了对 110B 的支持。这意味着你除了在魔搭社区和 HuggingFace 上白嫖 Demo 以外,能在模型发布的第一时间,就将它部署到你自己的电脑上。
还有一些像是 SkyPilot 的云部署平台,也是第一时间发推去蹭 Qwen1.5 的热度。纵观大模型开源社区,也只有 Llama 是人人都想蹭。Qwen系列持续开源大半年,在开源生态里的位置已经渐渐开始向Llama 靠近。
在发布当天,Qwen1.5-110B 占领了 Hacker News 热度榜首一段时间,上一次有这么多热度和讨论,还是去年8月通义千问首次宣布开源的时候。不过,人们讨论的方向,已经从当时的“这是什么?”转变为认真的讨论“这有多强?”。质疑的噪声随着 Qwen 的实力增强逐渐消散。
有的网友对于Qwen1.5-110B在摘要生成、信息提取方面的能力表示肯定,认为效果好于Llama 3。
不过也有的朋友表达喜爱的方式有些粗暴。
这次通义千问发布的 Qwen1.5-110B 开源模型是 Qwen 系列的首个千亿参数的模型,110B相比同一系列的72B模型性能有明显提升。而通义千问72B此前一直是最受社区欢迎的开源模型,说句屡屡霸榜也不为过。不过在这个模型中,没有对预训练的方法进行大幅改变,因此性能提升主要来自于模型规模的增加。
Qwen1.5-110B与其他Qwen1.5模型相似,采用了相同的Transformer解码器架构,使用了分组查询注意力(GQA)。支持32K tokens的上下文长度,支持英、中、法、西、德、俄、日、韩、越、阿等多种语言。
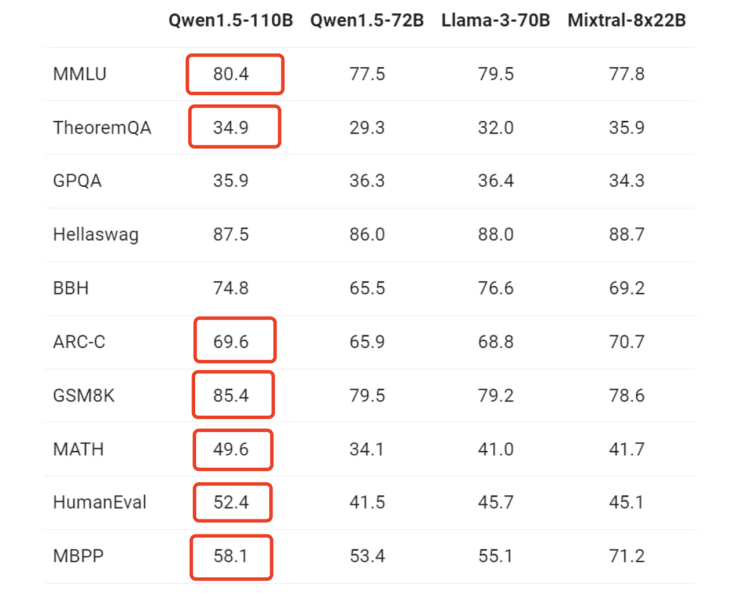
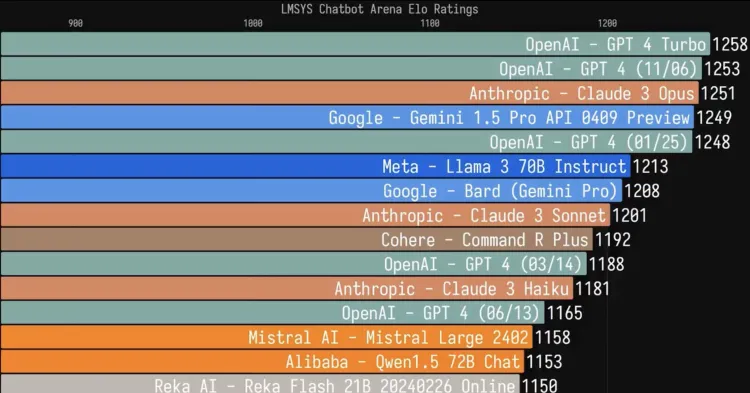
从跑分性能上来看,大部分测试项目都超越了 Llama 3 70B:
除了跑分,我们更好奇 Qwen1.5-110B 的实际表现如何,跟 Llama 3-70B 又有多大区别?接下来就实测看看。
先来几个新鲜的弱智吧问题:

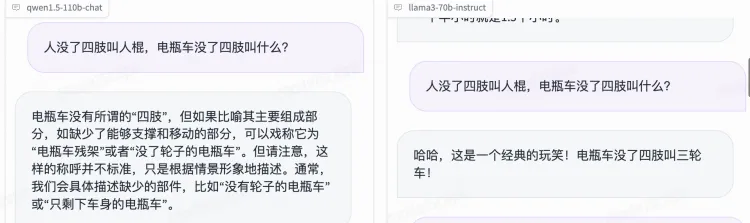
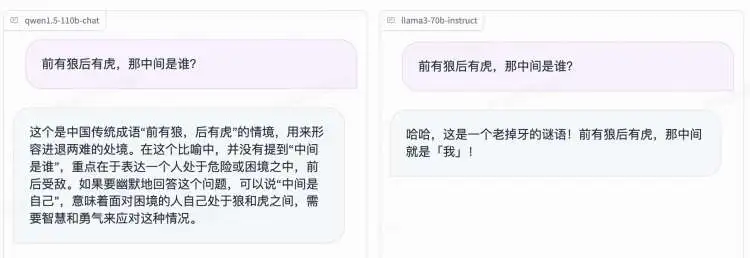
在没有进行任何人格化Prompt 的前提下,Qwen1.5-110B 的语言更有逻辑,信息更丰富,都是正确答案。而 Llama 3 的回答比弱智吧还要弱智一点,不仅有一个半小时是 1.5 小时这种废话文学,还有电动车变三轮车这种幻觉。或许对于弱智吧来说这才是正确答案?
再来看看它的中文理解能力怎么样:
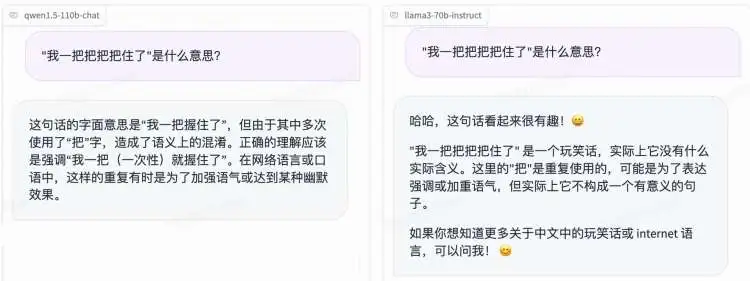
这句话的正确回答应该是:我一下就把“把手”/“车把”给握住了。
Qwen 的回答是正确的,只不过少了一层握住车把的意思。而 Llama 3 自以为自己很搞笑。
再进行一轮跟进的连续问答:
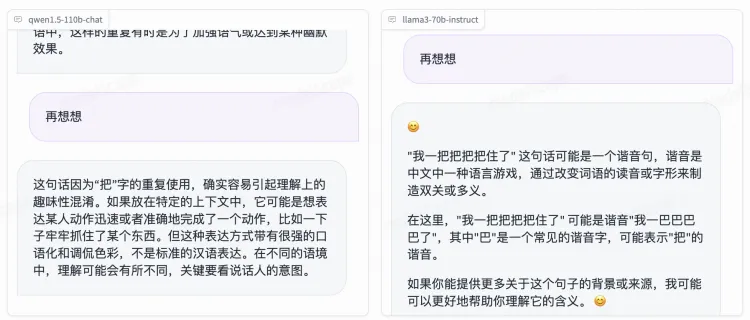
多让 Qwen 思考一次,基本上完全回答正确了问题。而 Llama 3 依然在搞笑。我真给 Llama 3 的回答看笑了。
来一道正儿八经的数学题:
王老太上集市上去卖鸡蛋,第一个人买走篮子里鸡蛋的一半又一个,第二个人买走剩下鸡蛋的一半又一个,这时篮子里还剩一个鸡蛋,请问王老太共卖出多少个鸡蛋?
他们的答案是:

Qwen 思路清晰,答案正确。而 Llama 3 过程是对的,但是解一个一元一次方程给解错了。而且从解题思路上来说,Qwen 是逆向思维,很巧妙。Llama是典型的小学生思维,相信所有小学生看到这道题都会用 Llama 3 的方式來解题。
在没有清空聊天记录的情况下,用韩语沟通,Llama 3 会延续之前中文的回答习惯。Qwen 则更换成了韩语回答。
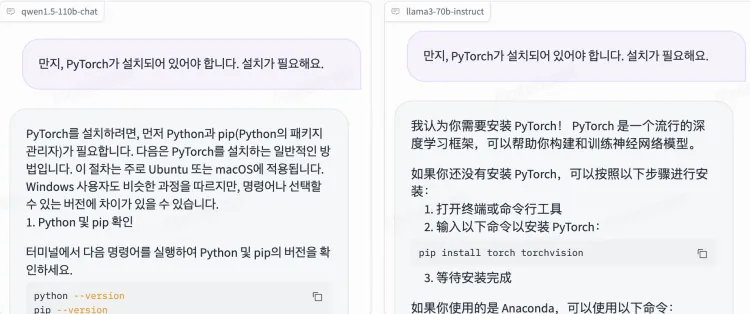
这几道测试题 Qwen1.5-110B 完胜 Llama 3 70B。不是说 Llama 3 不行,只是在中文这块,Qwen1.5-110B说一句最强开源模型应该没什么争议了。
把开源进行到底
在Hugging Face 上,Qwen 系列模型几乎自开源以来就一直处于热度榜前列的位置,随着1.5 版本的到来,以及 72B 和 110B 大参数量模型的推出,更是一度成为了 Llama 之外最耀眼的开源模型之一。尤其在中文这一母语领域,基本是全网无代餐的存在。
自去年 8 月以来,通义千问的开源节奏马不停蹄。自2月初Qwen 1.5系列发布后,三个月里就推出了 10 款不同参数规格的开源模型,包括8款大语言模型、 Code系列模型和 MoE 模型。去年底,通义千问还开源了两款多模态模型,视觉理解模型Qwen-VL和音频理解模型Qwen-Audio。
如果还算上各种部署和调试的版本, HuggingFace 上已经有 76 个不同型号的 Qwen 模型。作为对比,Mistral 和 Llama 都只有个位数个模型。相比之下,Qwen 简直是开源界的劳模。
辛苦自然也是有回报的,大半年时间,Qwen 系列模型的下载量已经超过 700 万,HF和魔搭上随手都能翻到基于Qwen系列的模型和应用。
对于大量开发者和企业来说,从5亿到1100亿参数全覆盖的Qwen系列,提供了最理想的模型选型套餐。通义大模型近期频频公布客户合作信息,先后接入中科院国家天文台、新东方、同程旅行、长安汽车等机构和企业,中国科学院国家天文台基于通义千问开源模型开发了新一代天文大模型“星语3.0”,这是中国大模型首次“上天”,应用到天文观测领域。
近期,随着模型能力逐渐拉齐,开闭源之争也变得更有讨论的意义。相比于追求自我闭环商业化的闭源模型,开源赛道展开的是另一种“一切皆有可能”的想象力。
有人用有人讨论,开源才有意义。
而从这个角度来说, Qwen 系列已经成为了国内目前最成功的开源产品,没有之一。
本文来自微信公众号”硅星人Pro“,作者 椰子




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
