# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

两周前,OpenBMB开源社区联合面壁智能发布领先的开源大模型「Eurux-8x22B 」。相比口碑之作 Llama3-70B,Eurux-8x22B 发布时间更早,综合性能相当,尤其是拥有更强的推理性能——刷新开源大模型推理性能 SOTA,堪称开源大模型中「理科状元」。激活参数仅 39B,支持 64k 上下文,比 Llama3 速度更快、可处理更长文本。

Eurux-8x22B 由 Mixtral-8x22B 对齐而来。强劲战斗力来自面壁 Ultra 对齐技术上新 UltraInteract 大规模、高质量对齐数据集。此前,面壁 Ultra 对齐系列数据集已经“强壮”了全球超 200 个大模型,堪称大模型上分神器。
—
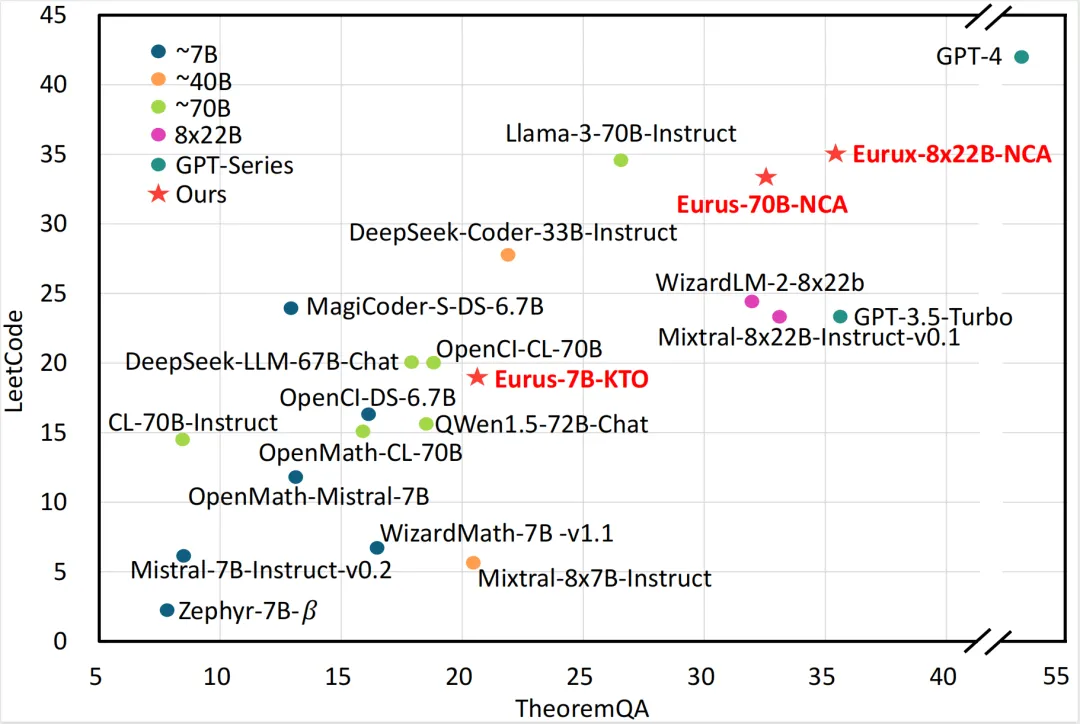
复杂推理能力是体现大模型性能差异的最核心能力之一,也是大模型真正落地应用所需的关键能力所在。
Eurux-8x22B 在代码和数学等复杂推理的综合性能方面超越 Llama3-70B,刷新开源大模型 SOTA,堪称「理科状元」。特别在 LeetCode (180道LeetCode真题)和 TheoremQA(美国大学水准的STEM题目)这两个具有挑战性的基准测试中,超过现有开源模型。

开源大模型「理科状元」Eurux-8x22B在实际应用中表现如何呢?
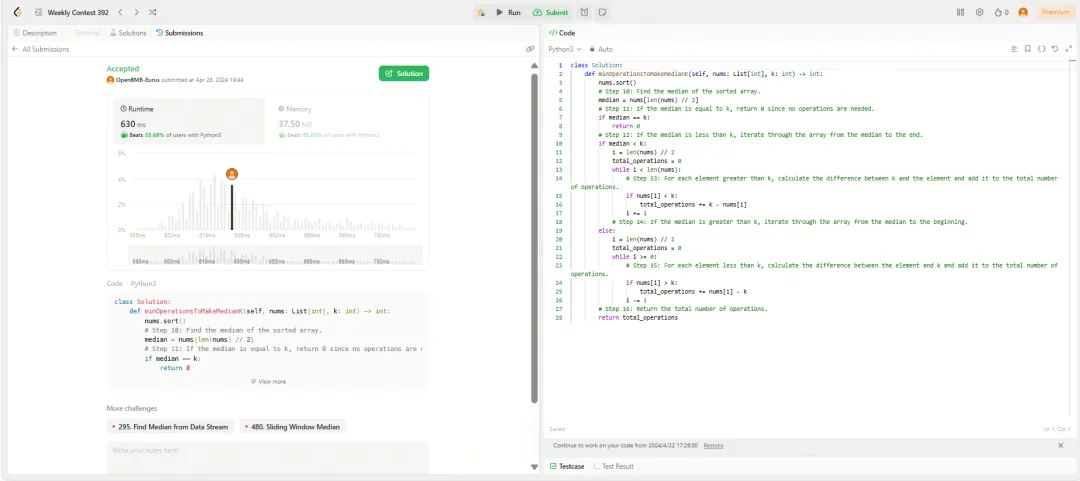
在近期 LeetCode 周赛,这一检验人类程序员编程能力的真实竞技场上:Eurux-8x22B 在 Python 编程方面取得综合排名超越 80% 人类参赛选手的优秀成绩,成功解决四道算法题中的三道,可以初步通过互联网大厂的程序员编程面试。
下面是本次周赛中 Eurux-8x22B 对一道中等难度的算法题的真实解答:

除了代码能力优秀,Eurux-8x22B 解答数学题也轻而易举。
例如给它一道高中排列组合题,Eurux-8x22B 首先给出了清晰的解题思路,然后一步步地拆解执行,再进行结果汇总,最后得到正确答案。

再考察它一道代数题,Eurux-8x22B 直击要害,运用二项式定理,清晰简洁地给出了正确的解答。

接着给它一道向量代数题,Eurux-8x22B 也能轻松拿下。

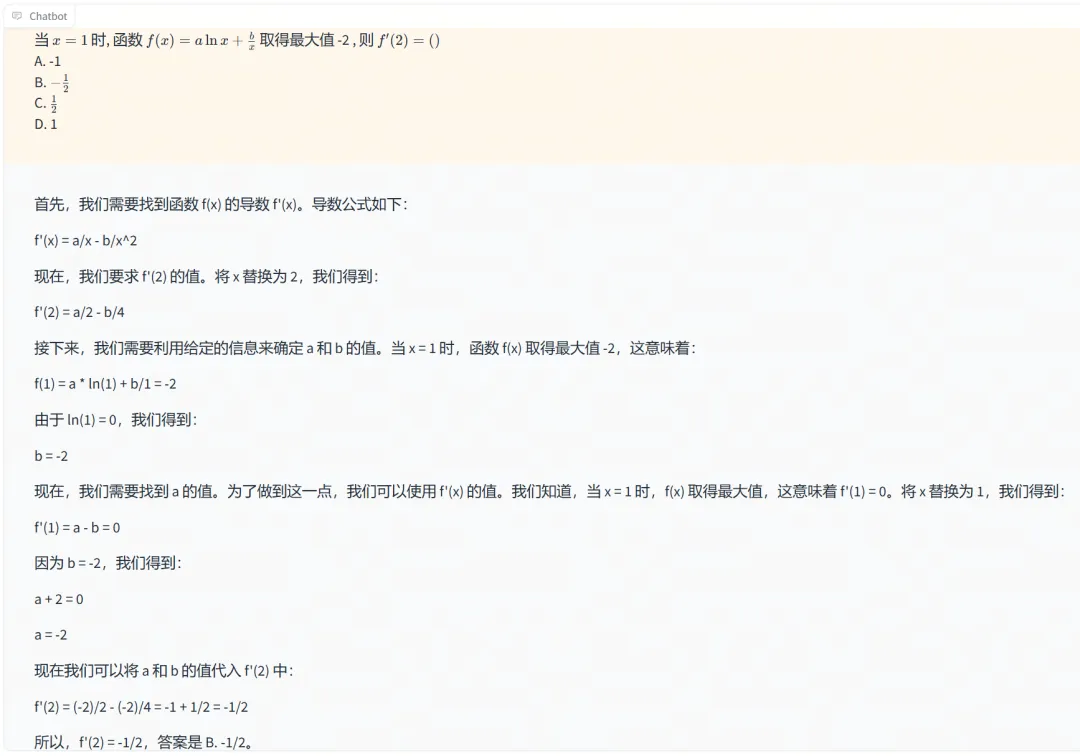
高考函数题可能是令很多人回忆起来就头疼的一类题,Eurux-8x22B 也能解答无误。
—
本次大模型「理科状元」 Eurux-8x22B 的优异表现,得益于来自面壁 Ultra 对齐技术的大规模、高质量对齐数据集 UltraInteract 上新。好数据,才有好模型。此前,面壁 Ultra 对齐技术已经“强壮”了全球超 200 个大模型,堪称大模型上分神器。
UltraInteract 是专门设计用于提升大模型推理能力的大规模、高质量的对齐数据集,包含了覆盖数学、代码和逻辑推理问题的 12 个开源数据集的 86k 条指令和 220k 偏好对,共有五十万(条)左右数据。相比而言,Llama3-70B 模型则使用了千万量级的对齐数据,这从侧面证明了 UltraInteract 数据集的优质性——数据质量胜过数据数量。
如此高质量的对齐数据是如何构建的呢?
▶ 严格质量控制和筛选。首先,我们从多个开源数据集中抽样出难度较高、考察多样推理能力的 86k 复杂推理问题,并使用多个模型来采样答案。通过自动化格式检查和人工质量抽查结合的方式保证了答案格式的一致性和内容的正确性。
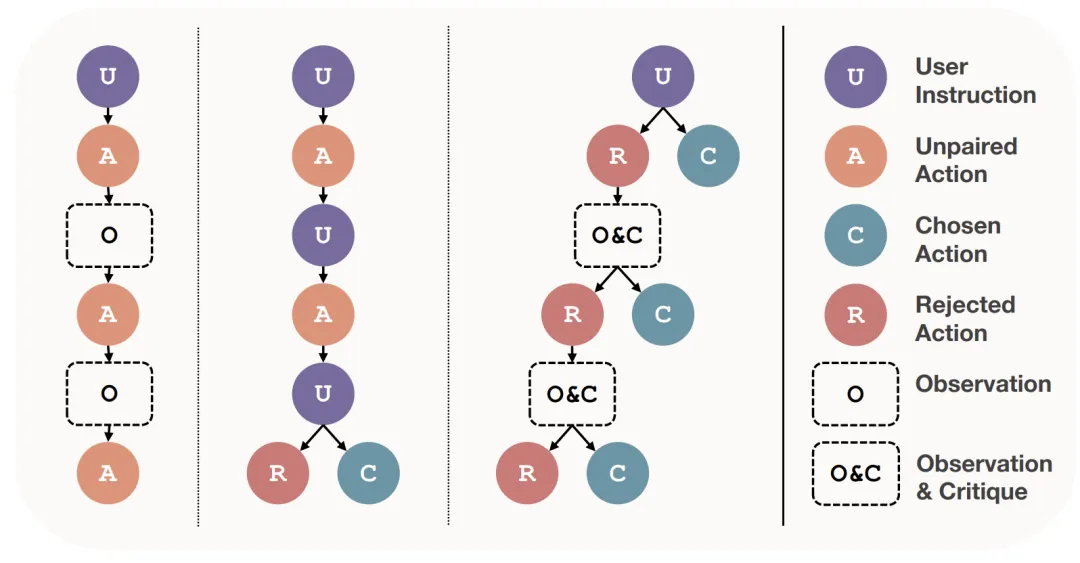
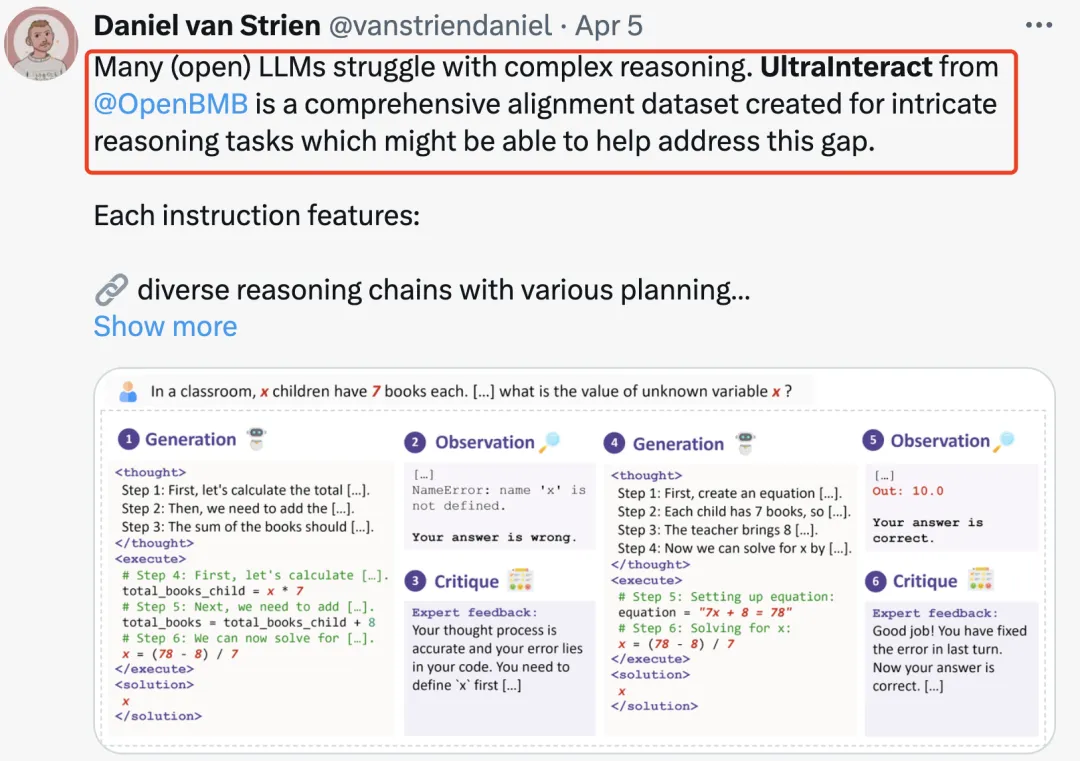
▶ 逐步推理。对于每条指令,模型都会按照思维链(CoT)格式进行逐步推理(如下图①),生成格式统一但模式多样的推理过程。
▶ 多轮交互。在模型给出推理过程之后,会自动与答案对比确定推理过程是否正确(如下图②),如果不正确,UltraInteract会使用另一个批评模型(如下图③)指出错误并给出改进建议,生成新的逐步推理(如下图④),再与策略模型进行多轮交互(如下图⑤⑥),直到答案正确或达到轮数上限为止。这一步有助于模型学会反思和改错能力,在实际表现中可以更好地和人进行多轮交互问答。

▶ 首创偏好树结构。为了深入探究偏好学习在复杂推理中的作用,UltraInteract还为每个问题都构建了一棵偏好树(如下图所示),其中问题作为根节点,每个回复作为一个子节点,每一轮生成两个节点(一对一错相配对)。所有正确推理对应的节点都可以用于 SFT,而配对的节点则可以用于偏好学习。
除了 UltraInteract 数据集的大力加持,偏好对齐也对 Eurux-8x22B 的推理性能提升有所帮助。我们发现,在推理任务中,提升正确答案的奖励值对于偏好对齐的效果十分重要,因为正确答案的空间比错误答案更有限,因此更加重要,模型在训练过程中不能偏离正确答案。然而,当前流行的 DPO 算法会使正确答案和错误答案的奖励值共同降低,因此在实验中效果不佳。我们采用另外两种偏好对齐算法 KTO 和 NCA,取得了更好的效果,能在 SFT 的基础上进一步提升模型性能。
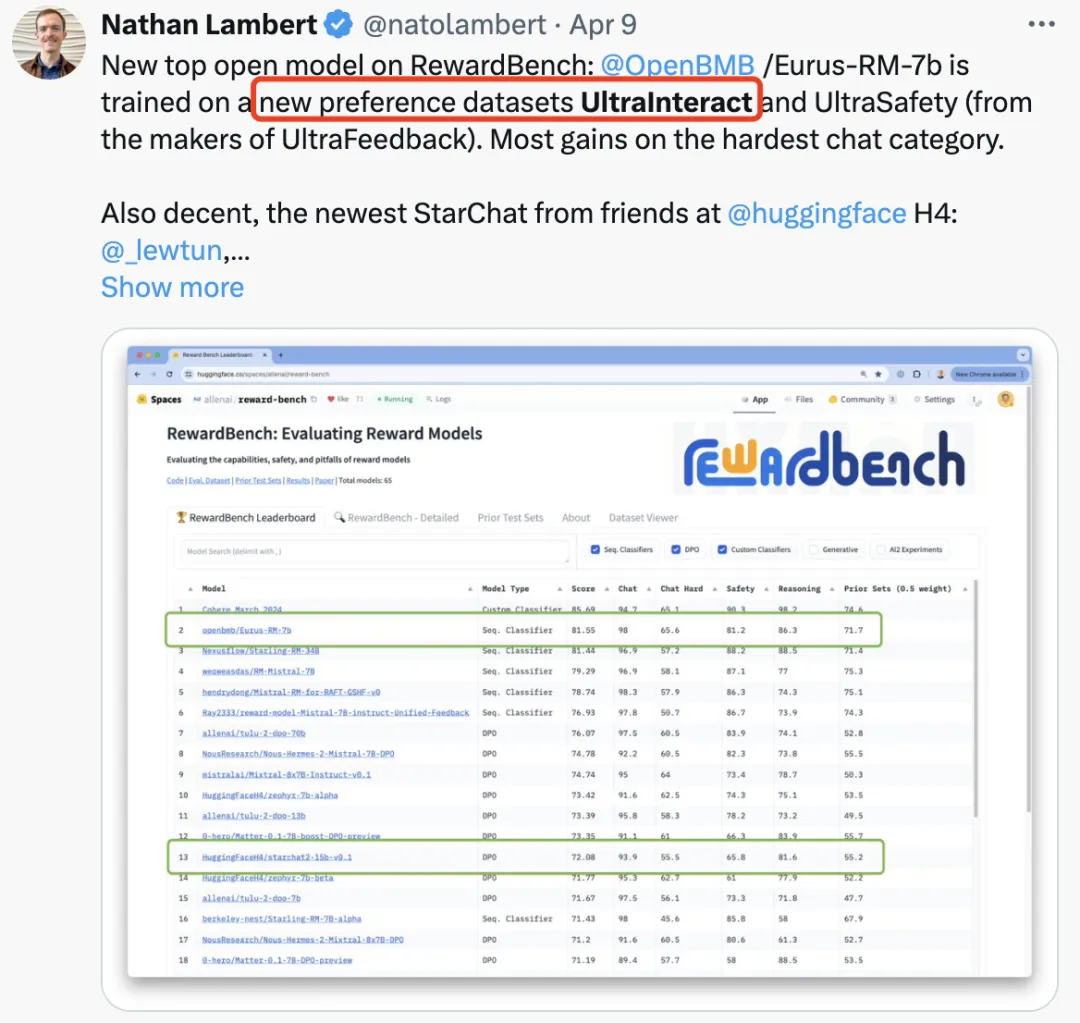
UltraInteract 数据集开源后在社区受到了广泛好评。
—
从领先的端侧模型「小钢炮」MiniCPM,到开源模型推理新 SOTA 的Eurux-8x22B,为什么我们总能推出同等参数、性能更优的「高效大模型」?
答案是,大模型是一项系统工程,而我们作为国内极少数兼具大模型算法与 Infra 能力的团队,拥有自研的全流程高效生产线:
面壁 Ultra 对齐技术、Infra 工艺、独家「模型沙盒」实验和现代化数据工厂,从数据、训练到调校工艺环环相扣,一条优秀的大模型 Scaling Law 增长曲线由此而生。
Infra 工艺方面,我们构建了全流程优化加速工具套件平台 ModelForce,可以实现 10 倍推理加速,90% 成本降低。

算法方面,我们进行了千次以上的「模型沙盒」实验,这一更加科学的训模方法,以小见大,寻找高效模型训练配置,实现模型能力快速形成。
本文来自微信公众号”OpenBMB开源社区”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
