# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

文生图模型成熟之后,有多少人苦练Midjourney咒语,还是调不出可用的图像?
设计界的专业名词、不太准确的英文翻译、理解不了的中国古代建筑充斥在目前文生图工具中。
本质上是源于国内很多团队基于翻译+英文开源Stable Diffusion模型,或者基于少量的中文数据在一些特殊的场景做了finetune,而这两种方式都存在对中文理解不足和不通用的问题。
针对这些痛点,腾讯带着中文原生的文生图大模型来了。
5月14日,腾讯宣布开源混元文生图大模型,是国内首个中文原生的DiT架构模型,具备中英文双语理解及生成能力,在古诗词、俚语、传统建筑、中华美食等中国元素的生成上表现出色。
比如同样是含有“昆曲”、“狗不理包子”关键词的Prompt,对比不同对文生图模型,混元生成了最匹配对图片:


为了进一步降低了用户的使用门槛,解决几个Prompt搞不定一张图的难题,对比此前大多数文生图模型77个字符的输入,混元支持最多256个字符的输入,简直是文生图界的“Kimi”了。
我们简单的尝试了一下腾讯混元文生图模型的长文本能力,发现当给了用户足够的输入空间对图像细节进行描述,生成结果的可控性就变得高了很多。
比如把一个长达253字符的Prompt丢给混元模型:一张细致的照片捕捉到了一尊雕像的形象,这尊雕像酷似一位古代法老,头上出人意料地戴着一副青铜蒸汽朋克护目镜。这座雕像穿着复古时髦,清爽的白色T恤和合身的黑色皮夹克,与传统的头饰形成鲜明对比。背景是简单的纯色,突出了雕像的非传统服装和蒸汽朋克眼镜的复杂细节。
这是生成效果:

这个特性尤其对专业用户来说是一个显著的进步,通过更丰富和详细的描述,增强图像的相关性和准确性。在长文本输入的基础能力之上,混元文生图大模型基于用户的使用场景,还支持用户文本改写以及多轮(十轮以上)绘画,确保生成结果的可用。

此次也是腾讯首次对大模型进行开源,或许是为后续主模型开源的一次铺垫。
混元文生图大模型差异性源于底层技术架构。在架构方面,混元文生图大模型采用了DiT架构,支持中英文双语输入及理解,参数量15亿。
由Sora带火的DiT架构融合了扩散模型和Transformer架构的优势,提供了强大的视觉生成能力,这种架构不仅可以用于文生图,还能用作视频和其他多模态视觉内容的生成基础。
据硅星人了解,腾讯混元团队认为基于Transformer架构的扩散模型(如DiT)具有更大的可扩展性,很可能成为下一代主流视觉生成架构,很可能会成为文生图、生视频、生3D等多模态视觉生成的统一架构。
“Transformer有非常强大的扩展能力,目前我们还不知道它的天花板在哪,这也是我们为什么坚定地往Transformer去走。”腾讯文生图负责人芦清林解释说。
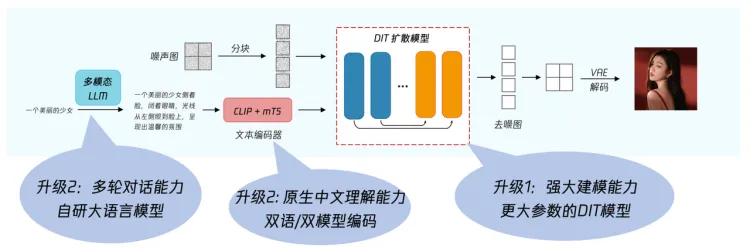
混元文生图从2023年7月起明确了基于Transformer架构的文生图模型,并启动了长达半年时间的研发、优化和打磨。在2024年2月初,将模型基础架构从U-Net升级为Transformer。
在这一过程中,腾讯混元主要从三个方面进行了改进和优化:
模型算法是一个模型的灵魂。混元通过在模型中加入了LLM的组件,让DiT架构具备了长文本理解能力,同时利用多模态大语言模型,对简单/抽象的用户指令文本进行强化,转写成更丰富/具象的画面文本描述,最终提升文生图的生成效果;通过自主训练中文原生文本编码器,增加了中文原生的理解能力,同时也支持英文;此外还通过技术手段控制同一话题与主体下图片主体的一致性,增加了多轮对话的能力。
而数据,则是决定了一个模型质量的养料。为了解决文生图模型训练数据量不足和质量不高的问题,腾讯混元团队采取了一些系统化的方法来提高数据的数量和质量。包括语言模型数据质量优化和图片训练数据处理流程(数据管道)优化。
语言模型数据质量提升主要从改善图片文字描述和建立多维度的数据集入手,首先,腾讯混元团队构建出可以描述图片详细内容的结构化文字,这些描述不仅准确还包括了丰富的知识点,比如结合专家的意见和专门设计的文本模型来提升描述的质量,使得模型学习到的数据更加有意义和具体。其次,他们创建了一个包括多个方面和主题的数据集,这样不管训练数据多么多样化,模型都能够根据不同的指示调整和生成内容,使它能够更好地适应各种情况。
图片训练数据的处理(数据管道)优化上,使用高效且精确的自动标签系统,一边获取图片一边给图片内容做标记分层,根据图片的质量好坏来为不同水平的模型服务。
此外,为了提供优质且种类平衡的数据样本,并降低由于数据变化导致的风险,腾讯混元团队设计了一种“数据班车”机制。通过比较线上模型和改变后样本分布的模型表现,来评估不同类型的训练样本对模型带来的影响,并且形成了一个可循环优化的训练样本调整流程。
在这之外,工程化的流程拥有最大的提效空间。为了更好地提升模型训练与运行效率,提升算力资源利用率,腾讯混元文生图团队为该模型构建专属工程加速工具库。同时,针对大模型训练和推理场景,使用了腾讯自研了Angel机器学习平台,主要包含负责训练的AngelPTM和负责推理的AngelHCF两大部分,从而提升训练效率。
正是在这一系列努力之下,腾讯混元文生图模型的效果得到了提升和优化。根据腾讯技术报告中的评测结果显示,最新的腾讯混元文生图模型效果远超开源的Stable Diffusion模型,是目前效果最好的开源文生图模型。
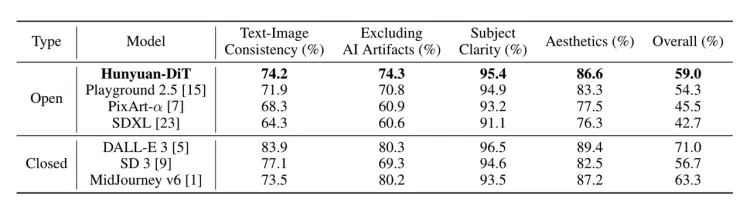
芦清林也表示,目前混元文生图大模型跟闭源相比,也各有优劣。“希望通过我们的开源能把这个差距变小。”
同时,他也明确了混元未来会主要通过两个方面进一步缩小差距:数据方面,图文对从去年的5-6亿,今年已经扩充到20亿,未来会持续扩充,包括更高质量的筛选;模型方面,目前是15亿的参数量,已经在尝试参数量更大的模型。
据硅星人了解到,开源后的混元文生图大模型,目前已在Hugging Face平台及Github上发布,包含模型权重、推理代码、模型算法等完整模型,可供企业与个人开发者免费商用。这次开源可以被视为一个相对完整的开源行为,不仅提供了必要的技术文档和代码,还允许商业使用,这对于推动技术发展和应用具有积极作用。

值得一提的是,这次开源的混元文生图大模型与腾讯混元文生图产品(包括微信小程序、Web端、云API等)最新版本完全一致。“我们希望能够把最好的东西拿出来,跟社区和业界的小伙伴们一起去应用。”
显然,此次混元文生图大模型的开源,被视为他要加入开源阵营的一个重要信号。
混元之前,整个大模型行业关于开源还是闭源的话题充满争议。做闭源的人吐槽“开源大模型没有竞争力”,搞开源的人起诉“OpenAI 不Open”。
OpenAI是坚定的闭源阵营坚持者,押注在更强通用模型的打造上;开源阵营Meta、Google以及国内的阿里等也在不断迭代。当然,也有其他大模型公司更多选择中间路线:模型“低配版”开源,更高参数量的模型闭源。比如,谷歌Gemini多模态模型闭源,单模态Gemma语言模型开源;Mistral最新发布的旗舰级大模型Mistral Large也是闭源。
即便如此,在去年年底到今年的趋势下,还是有越来越多的后来者选择了开放的模式。同时,开源作为推动创新的重要力量有目共睹,整个大模型行业如今得以高速发展也是建立在开源技术之上。
谷歌不开源Transformer,就没有GPT,没有TensorFlow和PyTorch这样的开源机器学习库,就没有今天大规模模型训练与部署的简化,Meta的Llama也让我们看到高质量的开源项目可以为企业带来长远的利益。
大模型企业采取开源策略,一方面是为了在市场上抢占先机,吸引那些没有充分财务和资源支持的用户免费使用他们的开源模型;另一方面,开源能够促进良好的用户互动,企业通过收集用户的反馈和了解他们的使用难点,可以快速优化和改进模型。这种做法不仅增加了用户基础,还加速了产品的技术创新和版本迭代,最终引领规则设计以及搭建生态。
腾讯此次开源混元文生图大模型,或许更侧重于展示了腾讯的技术实力和开放合作意愿。“开源社区能让大家都参与进来,共建能走得更快,这就是为什么我们现在要做开源。”芦清林表示。
在这个节点选择尝试开源,不止是行业选择,与腾讯自身而言,更具现实意义。
从2023年3月开始,腾讯在大模型领域长期以来一直是闭源且低调的姿态。马化腾在腾讯2023年股东大会上讲道:“并不急于早早做完,把半成品拿出来展示。”在全员加速的AI时代,Pony仍然是个“慢性子”。
在这种背景下,腾讯的大模型更聚焦于加强内部商业化路径。芦清林表示,“腾讯内部的业务场景非常丰富,能给他们带来价值就非常好。”
5月14日,在腾讯最新的财报中,广告业务和AI结合成为亮点。财报中显示:网络广告业务收入增长受益于用户参与度的提升以及集团不断升级的AI驱动的广告技术平台;升级了广告技术平台,帮助广告主更有效地进行广告投放,并向所有广告主推出了生成式AI驱动的广告素材创意工具。
腾讯是否会推动大模型的进一步开源还未可知,但混元文生图大模型的开源至少是一个积极的信号,接下来就看腾讯是否会放出更多的“成品”了。
本文来自“硅星人Pro“,作者 周一笑



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
