# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型风暴刮了大半年,AIGC市场开始起了新的变化:
酷炫的技术Demo,正在被完整的产品体验所取代。
比如,OpenAI最新AI绘画模型DALL· E 3刚一登场,就跟ChatGPT强强联合,成为ChatGPT Plus里最令人期待的新生产力工具。
又比如,微软基于GPT-4打造的Copilot,已经全线入驻Win11,正式取代Cortana成为操作系统里的新一代AI助手。
再比如,国产汽车如极越01,已经在座舱中正式搭载大模型,而且是完全离线的那种……
如果说,「大模型重塑一切」在2023年的3月份还只是一句技术先行者的乐观预言,到了今天,仍旧激烈的百模大战、以及实际的应用进展,已经让这一观点在行业内外激发越来越多的共鸣。
换言之,大到整个互联网的生产方式,小到每一辆汽车中的智能座舱,一个以大模型为技术力底座、驱动千行百业自我革新的时代正在来临。
按照蒸汽时代、电力时代的命名方式,或许能将之命名为「模力时代」。
而在「模力时代」中,最受关注的场景之一,就是智能终端。
原因很简单:以智能手机、PC、智能汽车甚至XR设备等为代表的智能终端产业,是与当代人生活最紧密相关的科技产业之一,自然也就成为了检验前沿技术成熟度的一个金标准。
所以,当技术热潮带来的第一波炒作逐渐冷静,以智能终端场景为一个锚点,「模力时代」新的机遇和挑战应该如何去看待和解读?
现在,是时候掰开揉碎,好好梳理一番了。
在具体分析挑战和机遇之前,还是先回到一个本质的问题上:大模型为代表的生成式AI为何会如此火爆,甚至被认为是“第四次工业革命”?
针对这一现象,已经有不少机构在进行研究,试图预测或总结生成式AI在不同场景下的发展规律,如红杉资本的《Generative AI: A Creative New World》。
在这其中,也有不少行业头部公司,基于自身经验分析了生成式AI在特定行业中的落地场景和潜在变革方向。
如终端侧AI代表玩家高通,就在前段时间发布了关于生成式AI发展现状和趋势的白皮书《混合AI是AI的未来》。
从中,或许能解读出生成式AI在行业中火爆的三大原因。
首先,是技术本身足够硬核。
无论是智能涌现的大模型,还是生成质量以假乱真的AI绘画,无不是用效果说话,实打实在几乎所有与文字、图像、视频和自动化相关的工作领域,展现出了颠覆传统工作流的惊人能力。
其次,是潜在落地场景丰富。大模型所带来的AI代际式的突破,从一开始就带给了人们无穷的想象空间:最早的一批体验者,很快就感知到了生成式AI给工作带来的助益。
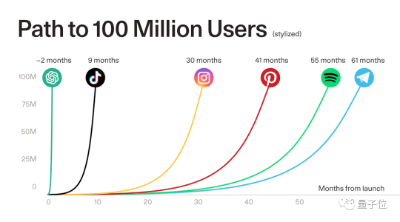
用户侧庞大的需求,从ChatGPT等代表性应用的用户增速,就可见一斑。
△ChatGPT打破热门应用注册用户破亿速度纪录,图源红杉资本
从最开始互联网的搜索、编程、办公,到现在涌现的文旅、法律、医药、工业、交通等等场景应用,乘生成式AI之风而起的,远不止能够提供基础大模型的公司,更是有一大批初创企业正顺势繁荣生长。
有不少业内专家认为:对于创业者而言,大模型所带来的应用层的机会更大。
底层有技术的代际式突破,上层有应用需求的蓬勃爆发,生态效应由此被激发。
根据Bloomberg Intelligence预测,到2032年生成式AI市场规模将从400亿美元爆炸式增到1.3万亿美元,广泛覆盖生态链的各个参与方,包括基础设施、基础模型、开发者工具、应用产品、终端产品等等。
这种生态链的形成,推动了行业新的变革,有望让AI进一步成为底层核心生产力。
基于这样的背景,我们再来看智能产业当下正在发生的事情。
一方面,以大模型为代表的AIGC应用风暴,正在以天为单位的迭代节奏中迅速从云端走向终端。
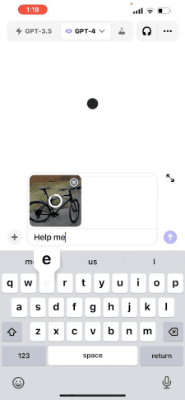
ChatGPT就率先在移动端更新了“视听说”的多模态功能,用户们拍照上传,就能针对照片内容与ChatGPT进行对话。
比如,“如何调整自行车座椅高度”:
高通也快速实现了在终端侧运行十几亿参数的Stable Diffusion和ControlNet大模型,在手机上生成高质量AI图像只需十几秒。
不少手机厂商也已经宣布,要为自家语音助手装上大模型这个“大脑”。
还不仅仅是手机。
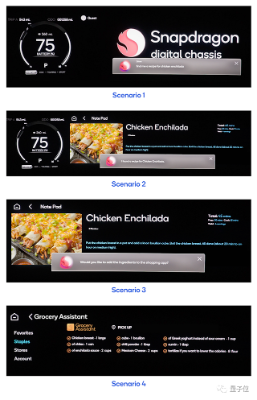
在上海车展、成都车展、慕尼黑车展等等国内外大型展会上,基础模型厂商和车厂的合作越来越常见,大模型“上车”已然成为智能座舱领域新的竞争点。
△一句话就能让车载大模型在APP里加购食材,回家就能做上饭
另一方面,应用的爆发加剧了算力供不应求的情况。
可以预见的是,模型的推理成本将会随着日活用户数量及其使用频率的增加而增加,仅仅只依靠云端算力,是不足以快速推进生成式AI规模化的。
从各行各业都在提升对终端侧AI算力的重视程度,也能看出这一点。
例如终端侧AI玩家高通,针对PC端芯片性能提升发布了新一代PC计算平台,采用高通自研的Oryon CPU,尤其搭载的NPU将面向生成式AI提供更强大的性能,被命名为骁龙X系列平台。
预计会在2023骁龙峰会上,这一新的计算平台就会发布。
显然,无论从应用还是算力来看,智能终端都已经成为AIGC落地潜力最大的场景之一。
事物通常具有两面性,大模型从快速发展到落地亦是如此。
当生成式AI一路狂飙到今天,智能终端产业巨大潜力下的现实瓶颈,已经浮出水面。
最大的掣肘之一,是最底层的硬件。
正如红杉两位投资人Sonya Huang和Pat Grady最新一篇生成式AI分析文章《Generative AI’s Act Two》中所提到的,AIGC发展得很快,然而预料之中的瓶颈不在于客户需求,而在于供应端的算力。
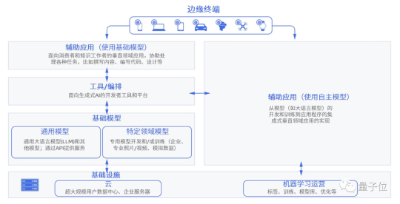
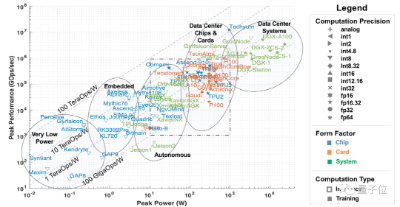
这里的算力,主要指AI和机器学习硬件加速器,从部署场景来看又可以被分为五大类:
数据中心级系统、服务器级加速器、辅助驾驶&自动驾驶场景下的加速器、边缘计算和超低功耗加速器。
△5类AI加速器,图源MIT论文「AI and ML Accelerator Survey and Trends」
随着ChatGPT爆火,大模型带动AIGC现象级出圈,使得数据中心、服务器级处理器等“云端算力”短期受到大量关注,甚至出现供不应求的情况。
然而,随着生成式AI迎来第二阶段,关于算力的一些问题也日渐凸显。
首先也是最大的问题,在于成本。如高通《混合AI是AI的未来》白皮书所言,如今大半年过去,随着大模型从技术追逐转向应用落地,各公司的基础模型训练逐渐尘埃落定,算力的大部头落到大模型的推理上。
短期内推理成本还可以接受,但随着大模型的APP越来越多、应用场景越来越广泛,在服务器等加速器上推理的成本也会急剧增加,最终导致调用大模型的成本比训练大模型本身还高。
换言之,大模型进入第二阶段后,推理对算力的长期需求将会远远高于单次训练,仅仅依靠数据中心和服务器级处理器组成的“云端算力”,完全不足以将推理打到用户能够接受的成本。
据高通在白皮书中统计,以加持大模型的搜索引擎为例,每一次搜索查询的成本,可以达到传统方法的10倍,每年光是在这方面的开销就可能增加数十亿美元。
这注定会成为大模型落地的关键掣肘。
随之而来的,还有时延、隐私和个性化问题。高通在《混合AI是AI的未来》中也提到,大模型直接部署在云端,除了用户量激增带来的服务器计算量不够,需要“排队使用”等bug,还势必需要解决用户隐私和个性化问题。
如果用户不希望上传数据到云端,大模型的使用场景如办公、智能助手等,就会受到不少限制,而这些场景多数分布在终端侧;而如果需要进一步追求更好的效果,如定制大模型为己用,更是需要直接将个人信息用于大模型训练。
种种因素之下,在推理上能发挥作用的“终端算力”,也就是包括自动驾驶&辅助驾驶、边缘计算(嵌入式)和超低功耗加速器在内的几大类处理器,开始进入人们的视野。
终端潜藏着巨大的计算能力。据IDC预测,2025年全球物联网设备数将超过400亿台,产生数据量接近80ZB,超过一半的数据需要依赖终端或者边缘的计算能力进行处理。
但终端同样存在功耗散热受限导致算力受限等问题。
这种情况下,如何利用潜藏在终端的巨大算力,来突破云端算力发展面临的瓶颈,正在成为「模力时代」下的最普遍的技术难题之一。
更别提除了算力以外,大模型落地还面临着算法、数据和市场竞争等挑战。
对于算法而言,基础模型的架构依旧未知。ChatGPT固然已经取得了很好的成果,但其坚持的技术路线并非就是下一代模型的架构方向。
对于数据而言,其他公司要想取得ChatGPT一般的大模型成果,高质量数据不可或缺,但《Generative AI’s Act Two》同样指出,目前应用公司生成的数据并没有创造一个真正的壁垒。
靠数据建立起来的优势是脆弱且无法持续的,下一代基础模型很可能就能直接摧毁这堵“城墙”,相比之下,持续而稳定的用户才能真正构建数据来源。
对于市场而言,目前大模型产品尚未出现多个杀手级应用,它究竟适配于何种场景仍旧未可知。
在这个时代将它用于哪类产品之中、做出哪种应用能发挥它最大的价值,目前市场还没能给出一套能够沿袭的方法论或标准答案。
针对这一系列问题,业界目前主要有两种解题方向。
一种是改善大模型本身的算法,在不改变模型“精华”的基础上,更好地改进它的大小,提升它在更多设备上的部署能力;
以Transformer算法为例,这类参数量庞大的模型要想运行在端侧,势必要在结构上做出调整,因此,这段时间来也诞生了不少MobileViT等轻量级算法。
这类算法力图在结构和参数量上进行不影响输出效果的改进,从而以更小的模型在更多设备上运行。
另一种是提升硬件本身的AI算力,让大模型能更好地在端侧落地。
这类方法又包括硬件上的多核设计、以及开发软件栈等,分别用于提升硬件计算性能和模型在不同设备上的通用性,以增强大模型在端侧落地的可能性。
前一种可以称之为软件对硬件的适配,后一种则是硬件厂商顺应时代浪潮的改变。但无论哪个方向,单独押注都存在着被赶超的风险。
「模力时代」下,技术日新月异,新的突破可能从软硬件任何一方出现,一旦缺少必要的技术储备,就可能落于人后。
所以是否就应该盲目跟进、或是干脆错过这波技术浪潮的发展?并非如此。
对于已经在互联网和AI时代发掘出自身价值的公司而言,或许同样能基于自身所处场景和技术积淀,在AIGC时代开掘出第三种解题思路。
以软硬件技术兼备的AI公司高通为例。
面对大模型技术在不同场景下的挑战,高通已经跳脱出一家芯片公司的身份,早早拥抱了AIGC的浪潮。
除了不断提升终端侧芯片AI算力的同时,高通也在布局基础的AI技术,力图作为一家赋能型企业,加快整个智能终端产业拥抱AIGC的速度。
然而,这样的思路同样也存在种种可预见的难点:
针对更大更复杂的AI模型,如何在确保性能的同时,让它也能在终端上顺利运行?
何时使用不同的模型,才能最好地分配终端与云端的算力?
即使解决了大模型部署在终端侧的问题,又应该让哪一部分部署在云端、哪一部分部署在终端,以及如何确保大模型不同部分之间的连接和功能不受影响?
终端侧性能优势不足的话,又要如何解决?
……
这些问题并非出现在某个单独案例中,而是已经切实存在于每个受AIGC影响的行业或场景。
无论是破局方法还是实际落地经验,都要从具体的场景和行业案例中才能摸索出答案。
AIGC进入第二阶段,大模型日渐普及,行业也开始探寻落地之道。
高通《混合AI是AI的未来》白皮书中提到,以智能手机和PC为例,新战场智能终端产业,已经有不少AIGC的落地场景的案例。
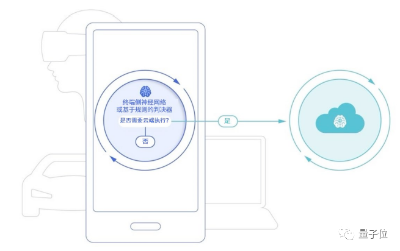
目前,已经有公司将较小的大模型部署到终端侧,用于处理更加个性化的问题,包括查找邮件、生成回复消息、修改日历事件和一键导航等。
像是“预定喜欢的餐厅座位”,就可以基于大模型,根据用户数据分析喜欢的餐厅和空闲的日程表,给出安排推荐,并将结果加入日历中。
高通认为,由于终端部署的大模型参数量受限、且不联网,因此回答时可能出现“AI幻觉”,这时候就能基于编排器(orchestrator)技术,在大模型缺乏信息时设置护栏,防止上述问题出现。
如果对于大模型生成的内容不满意,还能一键将问题发送到云端执行,再将回答效果更好的大模型生成结果回馈到终端侧。
这样一来,既能降低大模型在云端运行的算力压力,又能确保大模型在最大程度上保障用户隐私的同时,实现个性化使用。
至于终端侧算力、算法等本身需要突破的技术瓶颈,也已经有玩家研究出了一些“破局之道”。
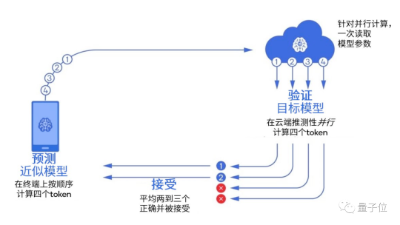
高通在白皮书中以前段时间大火的投机采样(Speculative Decoding)为例,介绍了一类当前已被广泛应用的新技术。
这是谷歌和DeepMind同时发现的一种加速大模型推理的方法,可以应用一个较小的大模型,来加速大模型的生成速度。
简单来说,就是训练一个更小的模型,给大模型提前生成一批“候选词”,相比于让大模型自己“思考”生成,直接做“选择”就好。
由于小模型生成速度比大模型快好几倍,一旦大模型觉得小模型已有的词可用,就直接拿来,不用自己再缓慢生成一遍。
这种方法,主要利用了相比计算量的增加,大模型推理速度更容易受到内存带宽影响的特性。
大模型由于参数量巨大、远超缓存容量,推理时相比计算硬件性能,更容易受内存带宽限制。例如GPT-3每生成一个单词,都需要读取一次全部1750亿参数,这个过程中在等待来自DRAM的内存数据时,计算硬件往往处于闲置状态。
换言之,模型做批量推理(batch inference)时,一次处理100个tokens和一个tokens时间上区别不大。
因此,利用投机采样,不仅能轻松跑几百亿参数的大模型,还能将部分算力放到终端侧进行,在确保推理速度的同时也能保留大模型的生成效果。
但无论是场景还是技术,最终都要找到彼此的适配点,才能产生实质的应用价值,正如软件和硬件的关系密不可分一样:
像生成式AI这样的软件算法突破,在寻找智能终端落地场景时,终究必然会面临与高通等移动端AI硬件结合的技术需求。
包括智能手机、PC、XR、汽车和物联网在内,智能终端产业下的各细分领域,如何基于AIGC热点找到自身的打法和价值?
各企业又要如何抓住这一次时代浪潮,来激发出这一类技术的应用价值,不错过全行业的生产力变革机遇?
量子位将基于长期的行业观察和对未来技术发展方向的深入思考,在「模力时代」这个专栏中,以当下大模型引领的行业热点为话题,从底层技术到上层应用,系统地解答行业内外人士心中对大语言模型、生成式AI的问题或疑惑。
由新热点引发的这一系列新问题,将在这个专栏接下来的更多内容中得到更加具体的解答。
文章来自微信公众号 “ 量子位 ”,作者 鱼羊 萧箫



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/